Happy New Year folks and welcome back to work! I hope you had a nice break. 🙂
I decided to kick off the new year of blogging with something fairly simple following some support work I did helping out a friend in the community. The problem encountered was twofold when dealing with data in Azure Data Lake Analytics and performing transformations using U-SQL.
- The dataset used custom field delimiters beyond the ‘out of box’ offerings of tabs and comma’s in the U-SQL extractors.
- The columns in the dataset varied from row to row with different rows containing different data values.
To combat these issues and for the purpose of this blog I’ve created this very simple text file seen below. Here we have 3 records in the file (Person 1, 2 and 3), but a single record is spread across multiple rows with a varying amount of fields on each line.
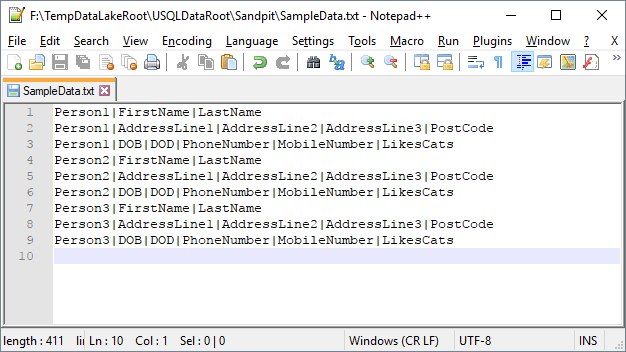
In both cases we can overcome these issues with the wonderful U-SQL string function split… Something that is now also available in T-SQL. Woo!
Using split we can define any delimiting character, pipes in my sample data. Plus, we can use the length of the array returned in the split to handle the variable rows. How? See below.
Extract
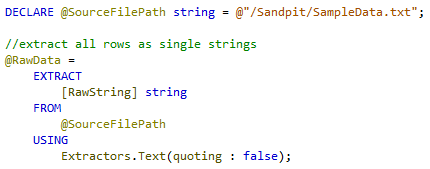
First, in the U-SQL extractor we need to ignore anything in the rows and simply ingest each complete row as a single string (128KB limit). To do this we can use the ‘out of box’ text extractor making sure we set the qualifier switch to false.
Transform
Next, let’s use split with a WHERE clause looking at the lengths of the arrays to deal with the varying amounts of fields. We can see in the file name data has 3 fields, address data has 5 fields and other data has 6.
![]()
Here you can see in the U-SQL I have put each subset of data in separate “table variables”.
Output
Finally, we can join the record subsets back together to form a standard width, more conventional CSV output file. Or in production do something else with the staged data.

The proof below. 3 records in a clean CSV file with field headers.

If you’d like a copy of the complete U-SQL script please feel free to download it here.
I hope you found the above example useful. Custom delimiters and varying fields per row handled.
Many thanks for reading.

Is there any benefit in extracting string and splitting it later over going
USING Extractors.Text(delimiter: ‘|’);
directly?
LikeLike
I mean in a scenario with fixed number of columns
LikeLike
Hi Dominik, I would suggest it depends if you want more or less control over the values you take from the data set. If you define the delimiter in the extractor, you’ll then also need to define each field as well up front. With my text and split approach validation can be a little easier and the array length (per row) can be used to check for data quality issues. Hope this helps. Paul
LikeLike
Hi Paul, Nice article. I grappled with a similar situation where due to a stray delimiter in the values, the activity used to error out saying that no. of columns don’t match. Do you have any article on variable width dataset problem where number of columns are not a known set of values ( as in your example : 3, 5,6)
LikeLike