Blog post updated 14th August 2021 🙂
 My colleagues and friends from the community keep asking me the same thing… What are the best practices from using Azure Data Factory (ADF)? With any emerging, rapidly changing technology I’m always hesitant about the answer. However, after 6 years of working with ADF I think its time to start suggesting what I’d expect to see in any good Data Factory implementation, one that is running in production as part of a wider data platform solution. We can call this technical standards or best practices if you like. In either case, I would phrase the question; what makes a good Data Factory implementation?
My colleagues and friends from the community keep asking me the same thing… What are the best practices from using Azure Data Factory (ADF)? With any emerging, rapidly changing technology I’m always hesitant about the answer. However, after 6 years of working with ADF I think its time to start suggesting what I’d expect to see in any good Data Factory implementation, one that is running in production as part of a wider data platform solution. We can call this technical standards or best practices if you like. In either case, I would phrase the question; what makes a good Data Factory implementation?
The following are my suggested answers to this and what I think makes a good Data Factory. Hopefully together we can mature these things into a common set of best practices or industry standards when using the cloud resource. Some of the below statements might seem obvious and fairly simple. But maybe not to everybody, especially if your new to ADF.
Contents
Platform Setup
Parallelism
Reusable Code
Security
Monitoring & Error Handling
Cosmetic Stuff
Documentation
|
Other Stuff…
Azure Data Factory by Example ISBN-13978-1484270288 I did the technical review of this book with Richard, it has a lot of great practical content. Check it out if you prefer a detailed guide on creating a good Data Factory.
PowerShell Checker Script As a side project I recently created a PowerShell script to inspect an ARM template export for a given Data Factory instance and provide a summarised check list coverings a partial set of the bullet points on the right, view the blog post here.
|


Let’s start, my set of Data Factory best practices:
Platform Setup
Environment Setup & Developer Debugging
Having a clean separation of resources for development, testing and production. Obvious for any solution, but when applying this to ADF, I’d expect to see the development service connected to source control as a minimum. Using Azure DevOps or GitHub doesn’t matter, although authentication against Azure DevOps is slightly simpler within the same tenant. Then, that development service should be used with multiple code repository branches that align to backlog features. Next, I’d expect developers working within those code branches to be using the ADF debug feature to perform basic end to end testing of newly created pipelines and using break points on activities as required. Pull requests of feature branches would be peer reviewed before merging into the main delivery branch and published to the development Data Factory service. Having that separation of debug and development is important to understand for that first Data Factory service and even more important to get it connected to a source code system.
For clarification, other downstream environments (test, UAT, production) do not need to be connected to source control.
Final thoughts on environment setup. Another option and technique I’ve used in the past is to handle different environment setups internally to Data Factory via a Switch activity. In this situation a central variable controls which activity path is used at runtime. For example, having different Databricks clusters and Linked Services connected to different environment activities:

This is probably a special case and nesting activities via a ‘Switch’ does come with some drawbacks. This is not a best practice, but an alternative approach you might want to consider. I blogged about this in more detail here.
Multiple Data Factory Instance’s
Question: when should I use multiple Data Factory instances for a given solution?
My initial answer(s):
- To separate business processes (sales, finance, HR).
- For Azure cost handling and consumption.
- Due to regional regulations.
- When handling boiler plate code.
- For a cleaner security model.
- Decoupling worker pipelines from wider bootstrap processes.
In all cases these answers aren’t hard rules, more a set of guide lines to consider. I’ve elaborated on each situation as I’ve encountered them it in the following blog here. Even if you do create multiple Data Factory instances, some resource limitations are handled at the subscription level, so be careful.
Furthermore, depending on the scale of your solution you may wish to check out my latest post on Scaling Data Integration Pipelines here. This assumes a large multi national enterprise with data sources deployed globally that need to be ingested.
Source code artifacts
With a single Data Factory instance connected to a source code repository its possible to get confused with all the different JSON artifacts available. There are in three possible options here:
- From the collaboration branch and feature branchs artifacts for each part of the Data Factory instance, separated by sub folders within Git. For example, 1 JSON file per pipeline.
- If publishing the Data Factory instance via the UI, the publish branch we contain a set of ARM templates, one for the instance and one for all parts of the Data Factory.
- Via the UI, you can download/export a Zip file containing a different set of ARM templates for the Data Factory instance.
These three options are visualised below.

My recommendation is to always use the option 1 artifacts as these give you the most granular control over your Data Factory when dealing with pull requests and deployments. Especially for large Data Factory instances with several hundred different pipelines.
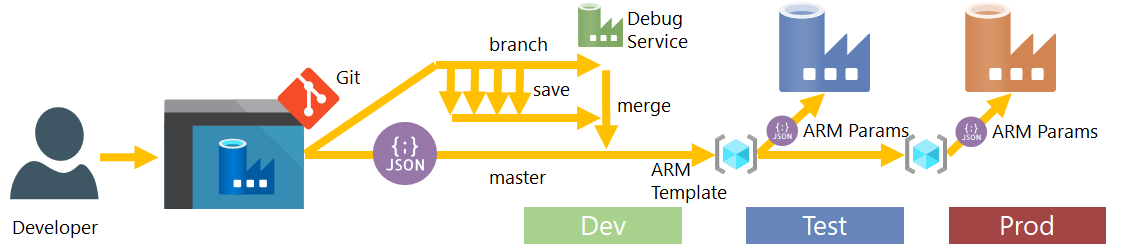
Deployments
Leading on from our environment setup the next thing to call out is how we handle our Data Factory deployments. The obvious choice might be to use ARM templates. However, this isn’t what I’d recommend as an approach (sorry Microsoft). The ARM templates are fine for a complete deployment of everything in your Data Factory, maybe for the first time, but they don’t offer any granular control over specific components and by default will only expose Linked Service values as parameters.
My approach for deploying Data Factory would be to use PowerShell cmdlets and the JSON definition files found in your source code repository, this would also be supported by a config file of component lists you want to deploy. Generally this technique of deploying Data Factory parts with a 1:1 between PowerShell cmdlets and JSON files offers much more control and options for dynamically changing any parts of the JSON at deployment time. But, is does mean you have to manually handle component dependencies and removals, if you have any. A quick visual of the approach:

To elaborate, the PowerShell uses the artifacts created by Data Factory in the ‘normal’ repository code branches (not the adf_publish branch), in the section above I refer to this as ‘artifacts option 1’. Then for each component provides this via a configurable list as a definition file to the respective PowerShell cmdlets. The cmdlets use the DefinitionFile parameter to set exactly what you want in your Data Factory given what was created by the repo connect instance.
Sudo PowerShell and JSON example below building on the visual representation above, click to enlarge.

If you think you’d like to use this approach, but don’t want to write all the PowerShell yourself, great news, my friend and colleague Kamil Nowinski has done it for you in the form of a PowerShell module (azure.datafactory.tools). Check out his GitHub repository here. This also can now handle dependencies.
I’ve attempted to summarise the key questions you probably need to ask yourself when thinking about Data Factory deployments in the following slide.

Automated Testing
To complete our best practices for environments and deployments we need to consider testing. Given the nature of Data Factory as a cloud service and an orchestrator what should be tested often sparks a lot of debate. Are we testing the pipeline code itself, or what the pipeline has done in terms of outputs? Is the business logic in the pipeline or wrapped up in an external service that the pipeline is calling?
The other problem is that a pipeline will need to be published/deployed in your Data Factory instance before any external testing tools can execute it as a pipeline run/trigger. This then leads to a chicken/egg situation of wanting to test before publishing/deploying, but not being able to access your Data Factory components in an automated way via the debug area of the resource.
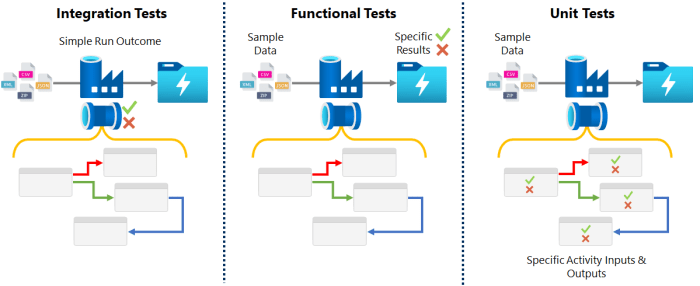
Currently my stance is simple:
- Perform basic testing using the repository connected Data Factory debug area and development environment.
- Deploy all your components to your Data Factory test instance. This could be in your wider test environment or as a dedicated instance of ADF just for testing publish pipelines.
- Run everything end to end (if you can) and see what breaks.
- Inspect activity inputs and outputs where possible and especially where expressions are influencing pipeline behaviour.
Another friend and ex-colleague Richard Swinbank has a great blog series on running these pipeline tests via an NUnit project in Visual Studio. Check it out here.
Wider Platform Orchestration
In Azure we need to design for cost, I never pay my own Azure Subscription bills, but even so. We should all feel accountable for wasting money. To that end, pipelines should be created with activities to control the scaling of our wider solution resources.
- For a SQLDB, scale it up before processing and scale it down once finished.
- For a SQLDW (Synapse SQL Pool), start the cluster before processing, maybe scale it out too. Then pause it after.
- For Analysis service, resume the service to process the models and pause it after. Maybe, have a dedicated pipeline that pauses the service outside of office hours.
- For Databricks, create a linked services that uses job clusters.
- For Function Apps, consider using different App Service plans and make best use of the free consumption (compute) offered where possible.
You get the idea. Check with the bill payer, or pretend you’ll be getting the monthly invoice from Microsoft.
Building pipelines that don’t waste money in Azure Consumption costs is a practice that I want to make the technical standard, not best practice, just normal and expected in a world of ‘Pay-as-you-go’ compute.
I go into greater detail on the SQLDB example in a previous blog post, here.

Hosted Integration Runtimes
Currently if we want Data Factory to access our on premises resources we need to use the Hosted Integration runtime (previously called the Data Management Gateway in v1 of the service). When doing so I suggest the following two things be taken into account as good practice:
- Add multiple nodes to the hosted IR connection to offer the automatic failover and load balancing of uploads. Also, make sure you throttle the currency limits of your secondary nodes if the VM’s don’t have the same resources as the primary node. More details here: https://docs.microsoft.com/en-us/azure/data-factory/create-self-hosted-integration-runtime
- When using Express Route or other private connections make sure the VM’s running the IR service are on the correct side of the network boundary. If you upgrade to Express Route later in the project and the Hosted IR’s have been installed on local Windows boxes, they will probably need to be moved. Consider this in your future architecture and upgrade plans.
For larger deployments and Azure estates consider the wider landscape with multiple IR’s being used in a variety of ways. Data Factory might be a PaaS technology, but handling Hosted IRs requires some IaaS thinking and management.

Lastly, make sure in your non functional requirements you capture protentional IR job concurrency. If all job slots are full queuing Activities will start appearing in your pipelines really start to slow things down.
Azure Integration Runtimes
When turning our attention to the Azure flavour of the Integration Runtime I typically like to update this by removing its freedom to auto resolve to any Azure Region. There can be many reasons for this; regulatory etc. But as a starting point, I simply don’t trust it not to charge me data egress costs if I know which region the data is being stored.
Also, given the new Data Flow features of Data Factory we need to consider updating the cluster sizes set and maybe having multiple Azure IR’s for different Data Flow workloads.
In both cases these options can easily be changed via the portal and a nice description added. Please make sure you tweak these things before deploying to production and align Data Flows to the correct clusters in the pipeline activities.
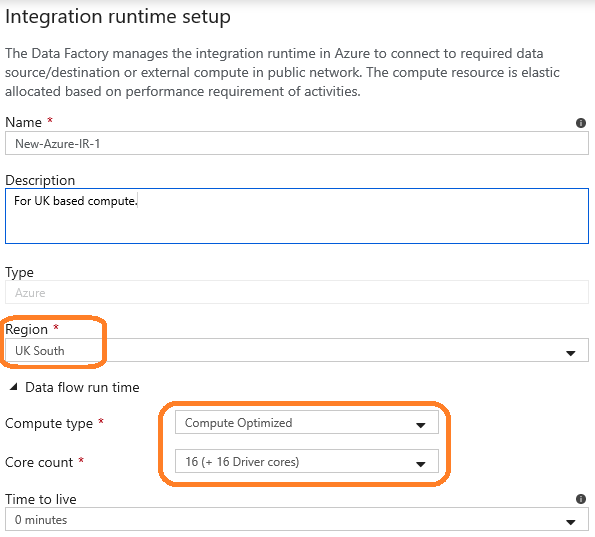
Finally, be aware that the IR’s need to be set at the linked service level. Although we can more naturally think of them as being the compute used in our Copy activity, for example.
SSIS Integration Runtimes
If you have a legacy on premises SQL Server solution that needs migrating into Azure using the PaaS wrapping within Data Factory can be a good hybrid stepping-stone for the project as a middle phase on the way to a full cloud native solution. Specifically thinking about the data transformation work still done by a given SSIS package.
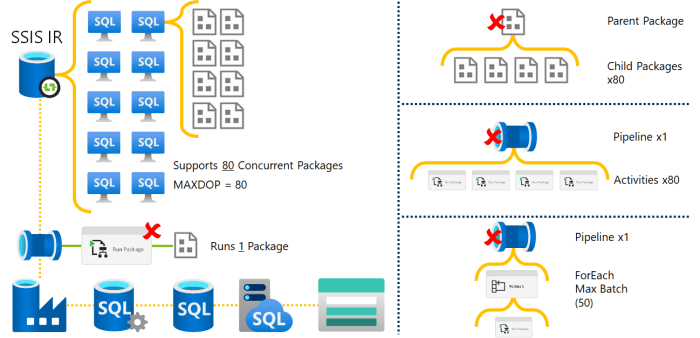
In this context, be mindful of scaling out the SSIS packages on the Data Factory SSIS IR. The IR can support 10x nodes with 8x packages running per node. So a MAXDOP for packages of 80.
That said, there isn’t a natural way in Data Factory to run 80 SSIS package activities in parallel, meaning you will be waste a percentage of your SSIS IR compute.
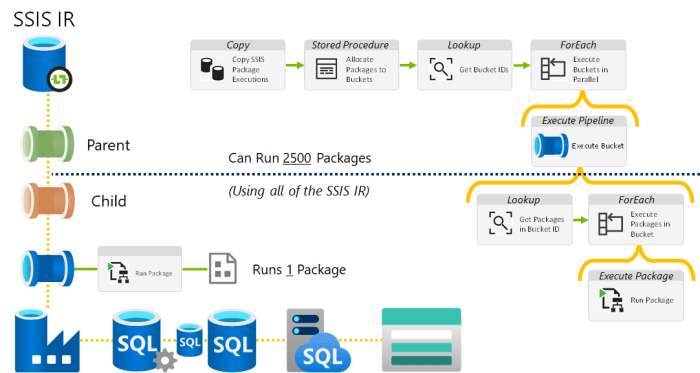
The best solution to this is using nested levels of ForEach activities, combined with some metadata about the packages to scale out enough, that all of the SSIS IR compute is used at runtime.
Parallelism
Parallel Execution
Given the scalability of the Azure platform we should utilise that capability wherever possible. When working with Data Factory the ‘ForEach’ activity is a really simple way to achieve the parallel execution of its inner operations. By default, the ForEach activity does not run sequentially, it will spawn 20 parallel threads and start them all at once. Great! It also has a maximum batch count of 50 threads if you want to scale things out even further. I recommend taking advantage of this behaviour and wrapping all pipelines in ForEach activities where possible.
https://docs.microsoft.com/en-us/azure/data-factory/control-flow-for-each-activity

In case you weren’t aware within the ForEach activity you need to use the syntax @{item().SomeArrayValue} to access the iteration values from the array passed as the ForEach input.
Service Limitations
 Please be aware that Azure Data Factory does have limitations. Both internally to the resource and across a given Azure Subscription. When implementing any solution and set of environments using Data Factory please be aware of these limits. To raise this awareness I created a separate blog post about it here including the latest list of conditions.
Please be aware that Azure Data Factory does have limitations. Both internally to the resource and across a given Azure Subscription. When implementing any solution and set of environments using Data Factory please be aware of these limits. To raise this awareness I created a separate blog post about it here including the latest list of conditions.
The limit I often encounter is where you can only have 40 activities per pipeline. Of course, with metadata driven things this is easy to overcome or you could refactor pipelines in parent and children as already mentioned above. As a best practice, just be aware and be careful. Maybe also check with Microsoft what are hard limits and what can easily be adjusted via a support ticket.
Understanding Activity Concurrency (Internal & External Activities)
 As part of Data Factory’s service limitations called out in the above section activity concurrency is featured. However, understanding the implications of this can be tricky as the limitation applies per subscription per IR region. Not per Data Factory.
As part of Data Factory’s service limitations called out in the above section activity concurrency is featured. However, understanding the implications of this can be tricky as the limitation applies per subscription per IR region. Not per Data Factory.
To recap:
- For external activities, the limitation is 3,000.
- For internal activities, the limitation is 1,000.
I blogged about this here with a full list of all activities detailing which is internal and which is external.
For a given Data Factory instance you can have multiple IR’s fixed to different Azure Regions, or even better, Self Hosted IR’s for external handling, so with a little tunning these limits can be overcome. With the caveat that you have good control over all pipeline parallel executions including there inner activity types.
Reusable Code
Dynamic Linked Services
Reusing code is always a great time savers and means you often have a smaller foot print to update when changes are needing. With Data Factory linked services add dynamic content was only supported for a handful of popular connection types. However, now we can make all linked services dynamic (as required) using the feature and tick box called ‘Specify dynamic contents in JSON format‘. I’ve blogged about using this option in a separate post here.

Create your complete linked service definitions using this option and expose more parameters in your pipelines to complete the story for dynamic pipelines.
Generic Datasets
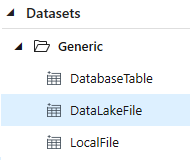 Where design allows it I always try to simplify the number of datasets listed in a Data Factory. In version 1 of the resource separate hard coded datasets were required as the input and output for every stage in our processing pipelines. Thankfully those days are in the past. Now we can use a completely metadata driven dataset for dealing with a particular type of object against a linked service. For example, one dataset of all CSV files from Blob Storage and one dataset for all SQLDB tables.
Where design allows it I always try to simplify the number of datasets listed in a Data Factory. In version 1 of the resource separate hard coded datasets were required as the input and output for every stage in our processing pipelines. Thankfully those days are in the past. Now we can use a completely metadata driven dataset for dealing with a particular type of object against a linked service. For example, one dataset of all CSV files from Blob Storage and one dataset for all SQLDB tables.
At runtime the dynamic content underneath the datasets are created in full so monitoring is not impacted by making datasets generic. If anything, debugging becomes easier because of the common/reusable code.
Where generic datasets are used I’d expect the following values to be passed as parameters. Typically from the pipeline, or resolved at runtime within the pipeline.
- Location – the file path, table location or storage container.
- Name – the file or table name.
- Structure – the attributes available provided as an array at runtime.
To be clear, I wouldn’t go as far as making the linked services dynamic. Unless we were really confident in your controls and credential handling. If you do, the linked service parameters will also need to be addressed, firstly at the dataset level, then in the pipeline activity. It really depends how far you want to go with the parameters.
Pipeline Hierarchies
I’ve blogged about the adoption of pipeline hierarchies as a pattern before (here) so I won’t go into too much detail again. Other than to say its a great technique for structuring any Data Factory, having used it on several different projects. How you define your levels it entirely based on your control flow requirements. Typically though, I’ll have at least 4 levels for a large scale solution to control pipeline executions. This doesn’t have to be split across Data Factory instances, it depends 🙂

Metadata Driven Processing
Building on our understanding of generic datasets and dynamic linked service, a good Data Factory should include (where possible) generic pipelines, these are driven from metadata to simplify (as a minimum) data ingestion operations. Typically I use an Azure SQLDB to house my metadata with stored procedures that get called via Lookup activities to return everything a pipeline needs to know.
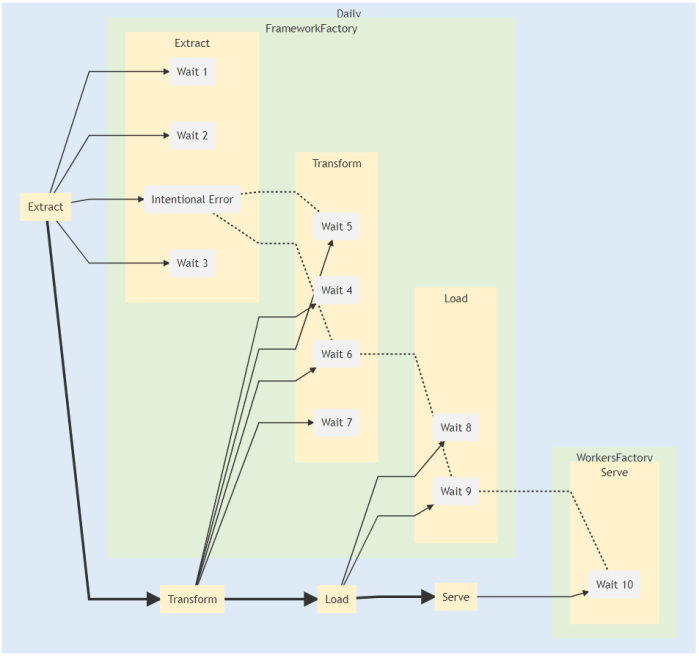
This metadata driven approach means deployments to Data Factory for new data sources are greatly reduced and only adding new values to a database table is required. The pipeline itself doesn’t need to be complicated. Copying CSV files from a local file server to Data Lake Storage could be done with just three activities, shown below.
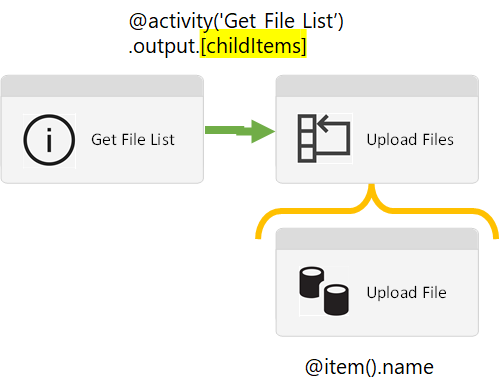
Building on this I’ve since created a complete metadata driven processing framework for Data Factory that I call ‘procfwk‘. Check out the complete project documentation and GitHub repository if you’d like to adopt this as an open source solution.
Using Templates
Pipeline templates I think are a fairly under used feature within Data Factory. They can be really powerful when needing to reuse a set of activities that only have to be provided with new linked service details. And if nothing else, getting Data Factory to create SVG’s of your pipelines is really handy for documentation too. I’ve even used templates in the past to snapshot pipelines when source code versioning wasn’t available. A total hack, but it worked well.
Like the other components in Data Factory template files are stored as JSON within our code repository. Each template will have a manifest.json file that contains the vector graphic and details about the pipeline that has been captured. Give them a try people.
In addition to creating your own, Data Factory also includes a growing set of common pipeline patterns for rapid development with various activities and data flows.
Security
Linked Service Security via Azure Key Vault
![]() Azure Key Vault is now a core component of any solution, it should be in place holding the credentials for all our service interactions. In the case of Data Factory most Linked Service connections support the querying of values from Key Vault. Where ever possible we should be including this extra layer of security and allowing only Data Factory to retrieve secrets from Key Vault using its own Managed Service Identity (MSI).
Azure Key Vault is now a core component of any solution, it should be in place holding the credentials for all our service interactions. In the case of Data Factory most Linked Service connections support the querying of values from Key Vault. Where ever possible we should be including this extra layer of security and allowing only Data Factory to retrieve secrets from Key Vault using its own Managed Service Identity (MSI).
If you aren’t familiar with this approach check out this Microsoft Doc pages:
https://docs.microsoft.com/en-us/azure/data-factory/store-credentials-in-key-vault
Be aware that when working with custom activities in ADF using Key Vault is essential as the Azure Batch application can’t inherit credentials from the Data Factory linked service references.
Managed Identities
 A lot of Azure Resources now have their own Managed Identities (MI), previously called Managed Service Identities (MSI’s). Microsoft Docs here.
A lot of Azure Resources now have their own Managed Identities (MI), previously called Managed Service Identities (MSI’s). Microsoft Docs here.
Using these Managed Identities in the context of Data Factory is a great way to allow interoperability between resources without needing an extra layer of Service Principals (SPN’s) or local resource credentials stored in Key Vault.
For example, for Data Factory to interact with an Azure SQLDB, it’s Managed Identity can be used as an external identity within the SQL instance. This simplifies authentication massively. Example T-SQL below.
CREATE USER [##Data Factory Name (Managed Identity)##]
FROM EXTERNAL PROVIDER;
GO
Another good reason for using Managed Identities is that for resources like Storage Accounts, local firewalls can be bypassed if the authentication is done using an MI.
Getting Key Vault secrets at runtime
Using key vault secrets for Linked Service authentication is a given for most connections and a great extra layer of security, but what about within a pipeline execution directly.
Using a Web Activity, hitting the Azure Management API and authenticating via Data Factory’s Managed Identity is the easiest way to handle this. See this Microsoft Docs page for exact details.
The output of the Web Activity (the secret value) can then be used in all downstream parts of the pipeline.

Security Custom Roles
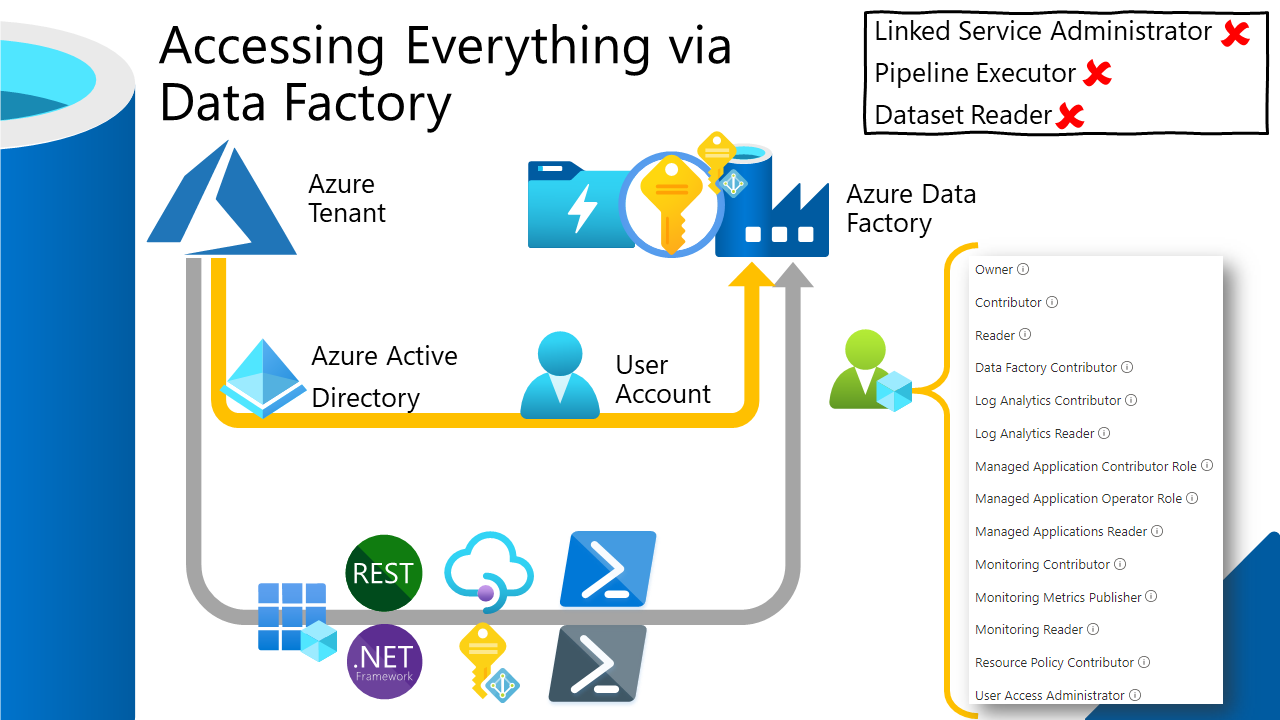
Given the above stance regarding Azure Key Vault. There is another critical point to consider; Data Factory has access to all the keys in Azure Key Vault. So who/what has access to Data Factory? Are we just moving the point of attack and is Key Vault really adding an extra layer of security?
That said, the security model and roles available for Data Factory are very basic. At the Azure management plane level you can be an Owner or Contributor, that’s it. Which in both cases will allow you access to anything in Key Vault using Data Factory as an authentication proxy.
The be really clear, using Data Factory in debug mode can return a Key Vault secret value really easily using a simple Web Activity request. See Microsoft docs below on doing this:
Given this, we should consider adding some custom roles to our Azure Tenant/Subscriptions to better secure access to Data Factory. As a starting point I suggest creating the following custom roles:
- Data Factory Pipeline Executor
- Data Factory Reader
In both cases, users with access to the Data Factory instance can’t then get any keys out of Key Vault, only run/read what has already been created in our pipelines. You can find some sample JSON snippets to create these custom roles in my GitHub repository here.
For this, currently you’ll require a premium Azure tenant. I also recommend using the Azure CLI to deploy the roles as the PowerShell preview modules and Portal UI screen don’t work every well at the point of writing this.
Securing Activity Inputs and Outputs
 For the majority of activities within a pipeline having full telemetry data for logging is a good thing. However, for some special cases the output of the activity might become sensitive information that should be visible as plain text.
For the majority of activities within a pipeline having full telemetry data for logging is a good thing. However, for some special cases the output of the activity might become sensitive information that should be visible as plain text.
Maybe a Lookup activity is hitting a SQL Database and returning PII information. Or, even a bear token is being passed downstream in a pipeline for an API call.
In these cases, set the ‘Secure Input’ and ‘Secure Output’ attributes for the activity. Shown on the right. These settings are available in Data Factory for most external activities and when looking back in the monitoring have the following affect.

Monitoring & Error Handling
Custom Error Handler Paths
Our Data Factory pipelines, just like our SSIS packages deserve some custom logging and error paths that give operational teams the detail needed to fix failures. For me, these boiler plate handlers should be wrapped up as ‘Infant’ pipelines and accept a simple set of details:
- Calling pipeline name.
- Run ID of the failed execution.
- Custom details coded into the process.
Everything else can be inferred or resolved by the error handler.
Once established, we need to ensure that the processing routes within the parent pipeline are connected correctly. OR not AND. All too often I see error paths not executed because the developer is expecting activity 1 AND activity 2 AND activity 3 to fail before its called. Please don’t make this same mistake. Shown below.

Finally, if you would like a better way to access the activity error details within your handler pipeline I suggest using an Azure Function. In this blog post I show you how to do this and return the complete activity error messages.
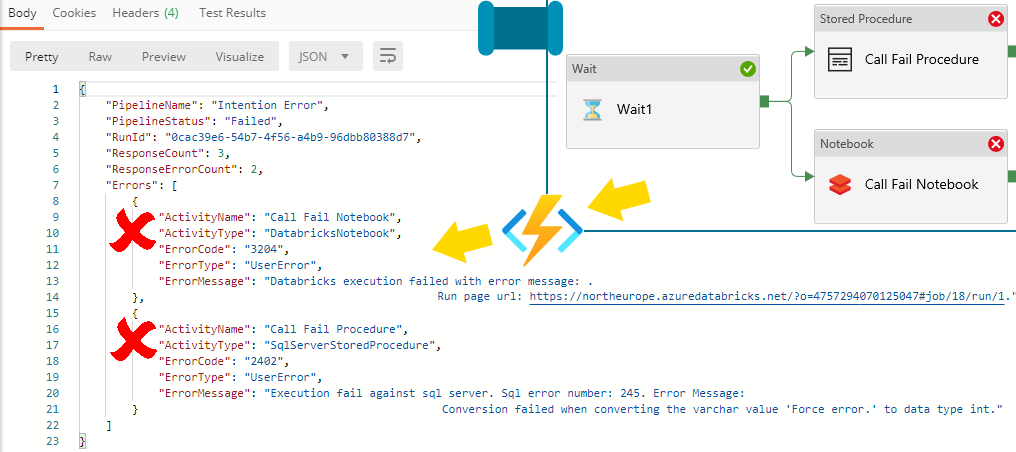
Monitoring via Log Analytics
 Like most Azure Resources we have the ability via the ‘Diagnostic Settings’ to output telemetry to Log Analytics. The out-of-box monitoring area within Data Factory is handy, but it doesn’t deal with any complexity. Having the metrics going to Log Analytics as well is a must have for all good factories. The experience is far richer and allows operational dashboards to be created for any/all Data Factory’s.
Like most Azure Resources we have the ability via the ‘Diagnostic Settings’ to output telemetry to Log Analytics. The out-of-box monitoring area within Data Factory is handy, but it doesn’t deal with any complexity. Having the metrics going to Log Analytics as well is a must have for all good factories. The experience is far richer and allows operational dashboards to be created for any/all Data Factory’s.
Screen snippet of the custom query builder shown below, click to enlarge.
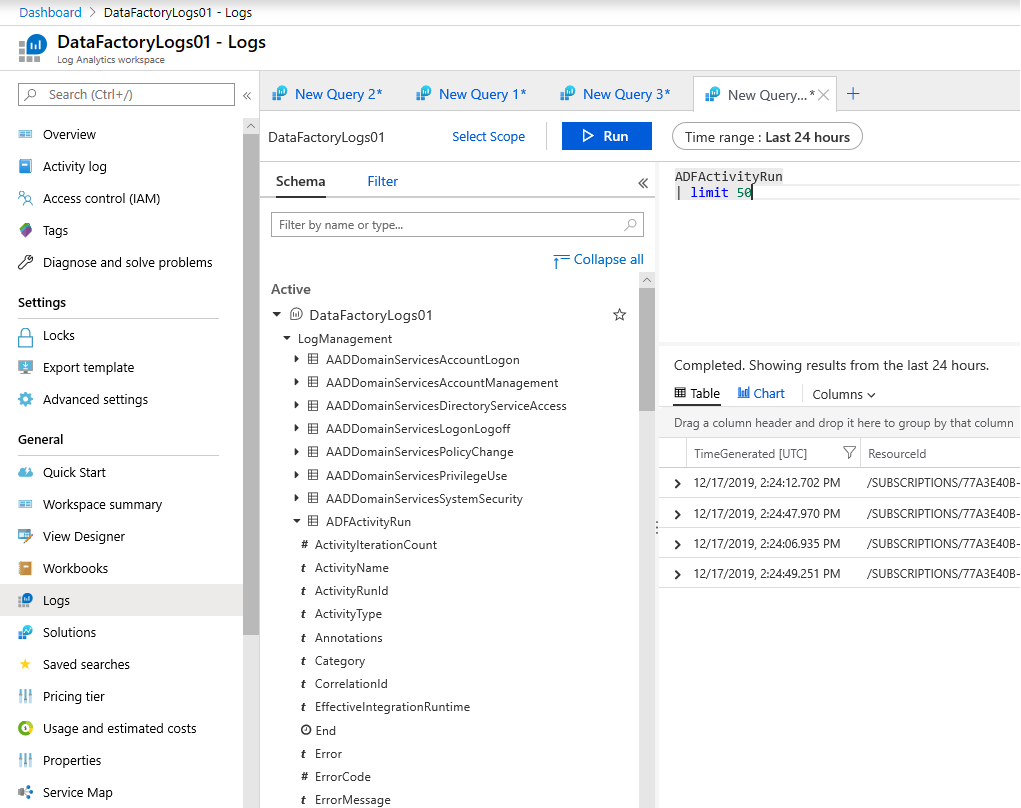
When you have multiple Data Factory’s going to the same Log Analytics instance break out the Kusto queries to return useful information for all your orchestrators and pin the details to a shareable Azure Portal dashboard. For example:
ADFPipelineRun
| project TimeGenerated, Start, End, ['DataFactory'] = substring(ResourceId, 121, 100), Status, PipelineName , Parameters, ["RunDuration"] = datetime_diff('Minute', End, Start)
| where TimeGenerated > ago(1h) and Status !in ('InProgress','Queued')
Timeout & Retry
Almost every Activity within Data Factory has the following three settings (timeout, retry, retry interval) which fall under the policy section if viewing the underlying JSON:

The screen shot above also shows the default values. Look carefully.
Awareness needs to be raised here that these default values cannot and should not be left in place when deploying Data Factory to production. A default timeout value of 7 days is huge and most will read this value assuming hours, not days! If a Copy activity stalls or gets stuck you’ll be waiting a very long time for the pipeline failure alert to come in. Hopefully the problem and solution here is obvious. Change this at the point of deployment with different values per environment and per activity operation. Don’t wait 7 days for a failure to be raised.
Credit where its due, I hadn’t considered timeouts to be a problem in Data Factory until very recently when the Altius managed services team made a strong case for them to be updated across every Data Factory instance.
Cosmetic Stuff
Naming Conventions
Hopefully we all understand the purpose of good naming conventions for any resource. However, when applied to Data Factory I believe this is even more important given the expected umbrella service status ADF normally has within a wider solution. Firstly, we need to be aware of the rules enforced by Microsoft for different components, here:
https://docs.microsoft.com/en-us/azure/data-factory/naming-rules
Unfortunately there are some inconsistencies to be aware of between components and what characters can/can’t be used. Once considered we can label things as we see fit. Ideally without being too cryptic and while still maintaining a degree of human readability.
For example, a linked service to an Azure Functions App, we know from the icon and the linked service type what resource is being called. So we can omit that part. As a general rule I think understanding why we have something is a better approach when naming it, rather than what it is. What can be inferred with its context.
Finally, when considering components names, be mindful that when injecting expressions into things, some parts of Data Factory don’t like spaces or things from names that could later break the JSON expression syntax.
Annotations
All components within Data Factory now support adding annotations. This builds on the description content by adding information about ‘what’ your pipeline is doing as well as ‘why’. If you treat annotations like tags on a YouTube video then they can be very helpful when searching for related resources, including looking around a source code repository (where ADF UI component folders aren’t shown).
Another key benefit of adding annotations is that they can be used for filtering within the Data Factory monitoring screen at a pipelines level, shown below:
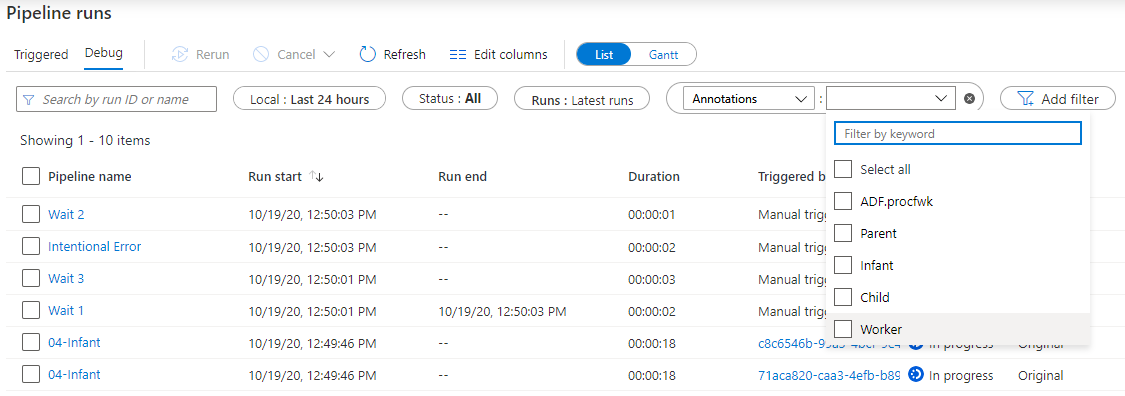
Pipeline & Activity Descriptions
 Every Pipeline and Activity within Data Factory has a none mandatory description field. I want to encourage all of us to start making better use of it. When writing any other code we typically add comments to things to offer others an insight into our original thinking or the reasons behind doing something. I want to see these description fields used in ADF in the same way. A good naming convention gets us partly there with this understanding, now let’s enrich our Data Factory’s with descriptions too. Again, explaining why and how we did something. In a this blog post I show you how to parse the JSON from a given Data Factory ARM template, extract the description values and make the service a little more self documenting.
Every Pipeline and Activity within Data Factory has a none mandatory description field. I want to encourage all of us to start making better use of it. When writing any other code we typically add comments to things to offer others an insight into our original thinking or the reasons behind doing something. I want to see these description fields used in ADF in the same way. A good naming convention gets us partly there with this understanding, now let’s enrich our Data Factory’s with descriptions too. Again, explaining why and how we did something. In a this blog post I show you how to parse the JSON from a given Data Factory ARM template, extract the description values and make the service a little more self documenting.
Factory Component Folders
 Folders and sub-folders are such a great way to organise our Data Factory components, we should all be using them to help ease of navigation. Be warned though, these folders are only used when working within the Data Factory portal UI. They are not reflected in the structure of our source code repository or in the monitoring view.
Folders and sub-folders are such a great way to organise our Data Factory components, we should all be using them to help ease of navigation. Be warned though, these folders are only used when working within the Data Factory portal UI. They are not reflected in the structure of our source code repository or in the monitoring view.
Adding components to folders is a very simple drag and drop exercise or can be done in bulk if you want to attack the underlying JSON directly. Subfolders get applied using a forward slash, just like other file paths.

Also be warned, if developers working in separate code branches move things affecting or changing the same folders you’ll get conflicts in the code just like other resources. Or in some cases I’ve seen duplicate folders created where the removal of a folder couldn’t naturally happen in a pull request. That said, I recommend organising your folders early on in the setup of your Data Factory. Typically for customers I would name folders according to the business processes they relate to.
Documentation
Pipeline Lineage
Do I really need to call this out as a best practice?? Every good Data Factory should be documented. As a minimum we need somewhere to capture the business process dependencies of our Data Factory pipelines. We can’t see this easily when looking at a portal of folders and triggers, trying to work out what goes first and what goes upstream of a new process. I use Visio a lot and this seems to be the perfect place to create (what I’m going to call) our Data Factory Pipeline Maps. Maps of how all our orchestration hang together. Furthermore, if we created this in Data Factory the layout of the child pipelines can’t be saved, so its much easier to visualise in Visio.
If you aren’t a Visio fan however and you have some metadata to support your pipeline execution chain. Try something like the below auto generated data lineage diagram, created from metadata to produce the markdown. Blogged about here:
Using Mermaid to Create a ProcFwk Pipeline Lineage Diagram
 Visio Stencils
Visio Stencils
Architecture diagrams are one thing, but what about diagrams or mock ups of out pipelines.
Instead of building a set of pipelines activities or the internals of a Data Flow directly in Data Factory using Visio can be a handy offline development experience.
If you agree, try out my Data Factory stencils for Visio that includes all the common Data Factory icons for Data Flow and pipeline Control Flow components.
Available via my GitHub repository here:
https://github.com/mrpaulandrew/ContentCollateral/tree/master/Visio%20Stencils
That’s all folks. If you have done all of the above when implementing Azure Data Factory then I salute you 🙂
Many thanks for reading. Comments and thoughts very welcome. Defining best practices is always hard and I’m more than happy to go first and get them wrong a few times while we figure it out together 🙂

thank you so much!!!! this post is great!!!!!!!!!
LikeLike
Big Thanks Paul! Really useful tips!
LikeLike
Do you have any thoughts on how to best test ADF pipelines?
LikeLike
That’s an interesting one… are you testing the ADF pipeline? Or are you actually testing whatever service the ADF pipeline has invoked? If the former and you don’t care about the service called what are you even testing for?
LikeLike
We are currently not doing any pipeline tests, just looking at how we may do it. We would mainly be interested in integration tests with the proper underlying services being called, but I guess we could also parameterize the pipelines sufficiently that we could use mock services and only test the pipeline logic, as a sort of unit test. The thinking so far is to have a separate folder in ADF for “test pipelines” that invoke other pipelines and check their output, then script the execution of the test pipelines in a CI build.
BTW., Thanks for the very nice writeup in the original article!
LikeLike
Excellent post and great timing as I’m currently getting stuck into ADF. We are following most of the above, but will definitely be changing a few bits after reading you’re post. One point we are unsure of is if we should be setting up a Data Factory per business process or one mega Factory and use the folders to separate the objects.
Current thoughts are to create a factory for each distinct area (so one for Data Warehouse, one for External File delivery etc.) then one extra factory just containing the integration runtimes to our on-prem data that are shared to each factory when needed. From a CI pipeline point of view then, with separate factories one release doesn’t hold up the other. We don’t see us having more than about 10 distinct areas overall.
Be great to hear your thoughts on best practice for this point. Thanks again for the great post.
LikeLike
Paul,
Thank you for the very informative article.
I am handling the infrastructure side of these deployments and I am trying to do what is best for my developers while also making sense architecturally.
Nwyra mentions creating, “one extra factory just containing the integration runtimes to our on-prem data that are shared to each factory when needed.” I would like to know your thoughts on this as well.
I find that I have multiple data factories requiring communication with the same site/server. When “Factory A” was originally built to perform the tasks of “Project 1”, an integration runtime was created and named after the single node it attached to. Now factory “B” needs to use that same IR node for “Project 2”. Since the node cannot be used by multiple IRs, I am now forced to share the integration runtime and therefore make “Project 2” reliant upon “Factory A”.
For this reason, I am considering architecting as Nywra suggested.
I will have “Infrastructure” data factories (local to each Azure region) with IRs named after the site (US1, EU2, etc) and the environment (DEV, PROD, etc) they service. The IRs will be shared from this Infrastructure DF to the DFs for each project.
Each IR in the Infrastructure DF will contain multiple nodes at each site so that nodes can be moved between the DEV and PROD IRs without breaking the pipelines in the DFs for each project.
I realize some additional considerations may need to be made since we are global and using private links wherever possible but does this architecture make sense or are we headed in the wrong direction.
Best,
Ray
LikeLike
I’m working on what I hope will be a best-practices reference implementation of Data Factory pipelines. Please check out https://github.com/marc-jellinek/AzureDataFactoryDemo_GenericSqlSink if you have a minute. I’m calling the project Throwing Mud on the Wall.
LikeLike
Great article – love the scale up / down steps – great tip!
LikeLike
Hi Paul, great article! As someone relatively new to Data Factory, but familiar with other components within Azure and previous lengthy experience with SSIS, I wanted to as a couple of questions:-
1. Would (and if so when would) you ever recommend splitting into multiple Data Factories as opposed to having multiple pipelines within the same Data Factory? In my head I’m currently seeing a Data Factory as analagous to a project within SSIS. From a deployment point of view, in SSIS having a “too big” project started making deployments and testing a little unwieldy with the volume of things being deployed; such as having to ensure that certain jobs were not running during the deployment and so on. Would this be the case with deploying the ARM template for DF? I’m also thinking of the security aspects, as I’m assuming RBAC is granted at the factory level?
2. Does DF suffer from the same sort of meta data issues that SSIS did? E.G. when an underlying table had a column that was not used in a data flow changed, you still needed to refresh the metadata within SSIS even though effectively no changes were being made.
3. From a code review/pull request perspective, how easy is it to look at changes within the ARM template, or are they sometimes numerous and unintelligible as with SSIS and require you to look at it in the UI? For SSIS collaborative working has always been a bit of a pain due to the shared xml structure.
4. I was mentioned above around testing, what frameworks (if any) are you currently using?
Thanks in advance if you get time to answer any of that, turned into more text than I was anticipating!
LikeLiked by 1 person
Hi Matthew, thanks for the comments, maybe let’s have a chat about your points rather than me replying here. Drop me an email and we can arrange something. Cheers Paul
LikeLike
Great Article Paul, I have same questions as Matthew Darwin, was wondering if you have replied to them.
LikeLiked by 1 person
It would definitely be good to hear an opinion on question number 1. I believe a lot of developers of ADF will struggle with this best practice. I can see a Data Factory becoming hard to maintain if you have multiple pipelines for different processes in the same Data Factory. It sounds like you can organize by using folders, but for maintainability it could get difficult pretty quickly.
LikeLiked by 1 person
Hi All
Sorry for the delayed reply.
To point 1 in Matthew’s comment above.
There are a few things to think about here:
Firstly, I would consider using multiple Data Factory’s if we wanted to separate business processes. E.g. Finance, Sales, HR. Another situation might be for operations and having resources in multiple Azure subscriptions for the purpose of easier inter-departmental charging on Azure consumption costs. Finally, data regulations could be a factor. For example, resources are restricted to a particular Azure region. You can overcome this using region-specific Azure Integration Runtimes with ADF, but that adds a management overhead to deployments of IR’s and aligning specific (copy) Activities to those dedicated IR’s. Therefore, separate factories might make more sense.
So, in summary, 3 reasons to do it… Business processes. Azure charging. Regulatory data restrictions.
What I would not do is separate Data Factory’s for the deployment reasons (like big SSIS projects). That said, it is also worth pointing out that I rarely use the ADF ARM templates to deployment Data Factory. Typically, we use the PowerShell cmdlets and use the JSON files (from your default code branch, not ‘adf_publish’) as definitions to feed the PowerShell cmdlets at an ADF component level. PowerShell as granular cmdlets for each ADF component (Datasets, Linked Services, Pipelines etc). This gives much more control and means releases can be much smaller.
Final thoughts, around security and reusing Linked Services. ADF does not currently offer any lower level granular security roles beyond the existing Azure management plane. Therefore, once you have access to ADF, you have access to all its Linked Service connections. Maybe this is a reason to separate resources and in-line with my first point about business processes.
Hope this helps inform your decisions.
Cheers
Paul
LikeLike
Hi Paul, Great article, i was wondering. I’m convinced by the github integration only on the dev env. (and by many other good practices you describe. I was wondering though : that means the triggers have to be scheduled the same way on all the environments ?
LikeLike
Hi, yes great point, in this situation I would do Data Factory deployments using PowerShell which gives you much more control over things like triggers and pipeline parameters that aren’t exposed in the ARM template. Rather than using a complete ARM template, use each JSON file added to the repo ‘master’ branch as the definition file for the respective PowerShell cmdlet.
For example:
…\Git\pipeline\Pipeline1.json. Then in PowerShell use Set-AzDataFactoryV2Pipeline -DefinitionFile $componentPath.
For a trigger, you will also need to Stop it before doing the deployment. So, something like…
$currentTrigger = Get-AzDataFactoryV2Trigger
if($currentTrigger -ne $null)
Stop-AzDataFactoryV2Trigger
Set-AzDataFactoryV2Trigger
Start-AzDataFactoryV2Trigger
Hope this helps.
LikeLike
nice post, thank you. I started working with adf since 10 months and was wondering where to looks for solutions if I get stuck. Finally i got a way, thank you I hooked up to all your articles since yesterday 🙂
Currently I am working on one of the new POC where trying to pull the data from api or website. In one of the scenario, I need to pull the data from excel (which is in web) and load in synapse.
I did convert that into separate csv files for every sheet and process further. But while doing that i found the data in csv is junk after certain rows which is causing the following error.
Error
{
“errorCode”: “BadRequest”,
“message”: “Operation on target CopyDataFromBlobToADLS failed: Failure happened on ‘Sink’ side. ErrorCode=ParquetJavaInvocationException,’Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=An error occurred when invoking java, message: java.lang.IllegalArgumentException:field ended by ‘;’: expected ‘;’ but got ‘Drain’ at line 0: message adms_schema { optional binary Country (UTF8); optional binary Year (UTF8); optional binary Rank (UTF8); optional binary Total (UTF8); optional binary SecurityApparatus (UTF8); optional binary FactionalizedElites (UTF8); optional binary GroupGrievance (UTF8); optional binary Economy (UTF8); optional binary EconomicInequality (UTF8); optional binary HumanFlightandBrain Drain\ntotal entry:10\r\norg.apache.parquet.schema.MessageTypeParser.check(MessageTypeParser.java:215)\r\norg.apache.parquet.schema.MessageTypeParser.addPrimitiveType(MessageTypeParser.java:188)\r\norg.apache.parquet.schema.MessageTypeParser.addType(MessageTypeParser.java:112)\r\norg.apache.parquet.schema.MessageTypeParser.addGroupTypeFields(MessageTypeParser.java:100)\r\norg.apache.parquet.schema.MessageTypeParser.parse(MessageTypeParser.java:93)\r\norg.apache.parquet.schema.MessageTypeParser.parseMessageType(MessageTypeParser.java:83)\r\ncom.microsoft.datatransfer.bridge.parquet.ParquetWriterBuilderBridge.getSchema(ParquetWriterBuilderBridge.java:188)\r\ncom.microsoft.datatransfer.bridge.parquet.ParquetWriterBuilderBridge.build(ParquetWriterBuilderBridge.java:160)\r\ncom.microsoft.datatransfer.bridge.parquet.ParquetWriterBridge.open(ParquetWriterBridge.java:13)\r\ncom.microsoft.datatransfer.bridge.parquet.ParquetFileBridge.createWriter(ParquetFileBridge.java:27)\r\n.,Source=Microsoft.DataTransfer.Richfile.ParquetTransferPlugin,”Type=Microsoft.DataTransfer.Richfile.JniExt.JavaBridgeException,Message=,Source=Microsoft.DataTransfer.Richfile.HiveOrcBridge,’”,
“failureType”: “UserError”,
“target”: “PL_CopyFromBlobToAdls”,
“details”: “”
}
Any idea the to cleans such data before processing further. Also whats the better way to ingest such data adf or bricks . Please advice. Thank you
LikeLike
Great article Paul. I feel it missed out on some very important gotchas: Specifically that hosted runtimes (and linked services for that matter) should not have environment specific names. That is, I come across ADF’s where the dev runtime is called ‘devruntime’ and the test one is called ‘testruntime’ and the result is it’s extra difficult to migrate code. Another gotcha is mixing shared and non shared integration runtimes. Again it’s extra difficult to migrate code from a shared runtime to a non shared runtime (or vice versa). Making this mistake causes a lot of extra needless work reconfiguring runtimes and packages. It seems obvious to me that non top-level resources should not have environment specific names.
LikeLike
Hey Nick, yes agreed, thanks for the feedback. I’ll include this in my next round of updates for the post. Cheers
LikeLike
Hi Nick. I am approaching this from the Infrastructure point of view. I want to make sure the IRs are architected properly for my developers.
Where does the difficulty come from in migrating from shared to non-shared (or vice-versa) and what do you recommend as the preferred approach?
Best,
Ray
LikeLike
Yeah, hard one, it depends how many environments you have to manage and how much resilience you want per environment. I typically go with 8x IR’s a 4 stage environment as a starting point…. 2x for dev, also shared with test. Then 3x for preprod and 3x for prod.
LikeLike
Hi @mrpaulandrew, thanks a lot for this blob. i am trying to implement azure devops pipeline for adf following adf_publish approach (sorry for not choosing the other PS approach as i find this more standard 🙂 ). i am able parameterise and deploy linked services, but i also have parameters for the pipelines.. how do i achieve parameterisation of those from devops.. i been trying to find a solution for this for more than a week.. pls help, thanks in advance!
LikeLike
Thankyou for sharing your experience
LikeLike
Hello and thanks for sharing!
What would be the recommended way to share common pipeline templates for multiple ADFs to use?
Is export/import the only option?
Thanks
LikeLike
Good question. My preferred approach is to have a common code base in Git/GitHub. Then deploy the generic pipeline definitions to multiple target data factory instances using PowerShell cmdlets. At deployment time also override any localised configuration the pipeline needs.
LikeLike
Thank for this information, I am planning to migrate from one subscription to another subscription, my questions are:
1. What is the best approach to migrate the Data factory to a new subscription?/*The document has details for moving to the new region not moving to newer subscription*/
4. What will happen to the roles and permissions for all the users when we move, will that be the same?/* Forexample if a user has a contributor role, after migration does the user will have the same role and permissions*/
8. Is it possible to move three Resources together (For ex ADF, azure SQl from one RG and Web App from other RG)?/* Can we migrate three or more resource groups or resources from different resource group parallelly*/
9. What is the order for moving the resources, Is it SQL first and then ADF later?
13. Is there any rollback option?
LikeLike
Hi
1. I would suggest simply redeploying your Data Factory to the new target resource group and subscription. Either using the ARM template, PowerShell cmdlets, or simply copying content from one code repo to the other manually if this is a one off.
4. Roles exist at a subscription level so these will need to be recreated.
8. Yes, if they are in the same Resource Group, the Azure Portal UI provides this option.
9. I would always do ADF last, the linked services do not validate connections at deployment time. So you could also do it first if you prefer. But generally, I would get everything else in place. Then use ADF to run an initial integration test.
13. Erm, maybe if things go wrong, just delete the new target resource group and carry on using the existing environment?
Thanks
Paul
LikeLike
In terms of parallel execution Paul, how would you handle that with say data going into a relational model or warehouse where dependencies (PK -> FK) are in place?
LikeLike
Hi, I would suggest for performance the normal practice would be to disable any enforced constraints before the load or not have them at all, especially for a data warehouse. Then maybe post load, run a set of soft integrity checks. This allows the orchestrator to scale without worrying about the data values. Cheers
LikeLike
HI Paul
Great article.
I am trying to define key logs to export to our Log analytics. Of course in a perfect world I would just select all the logs and export them. But our Enterprise Architect is very concerned about cost and noise. When setting up production ADFs do you always select every diagnostic setting log? If so why? Does the monitoring team look at every log category or are there some that should not be considered because they are too noisy/costly?
Thank you very much!
Jack
LikeLike
Hi Jack, this is only noisy if you use the items being reported in your Data Factory. Then, I would suggest the cost is quickly recovered when you have to troubleshoot a problem that requires the logs. What is the cost of not having the detail of why a failure occurred?? 🙂
LikeLike
Hi Paul,
thank you for these tips which will be our guidelines in any future ADF development.
I’m really disappointed with ADF performance though -> simple SQL activity which runs 0ms in database, takes sometimes up to 30 seconds in ADF. When I setup your procfwk and tried to run 10 Wait workers in parallel with Wait time parameter set to 1 sec and it took 4 minutes to finish.
Could you please tell me your opinion about ADF performance? And how can we work with this time overhead when we are trying to develop anything that suppose to run quite often and quickly.
Thank you very much!
honza, Joyful Craftsmen
LikeLike
Mmm, it’s a hard one. Because the Azure IR is ultimately shared compute. Try using a Hosted IR to interact with the SQL Database via a VNet and Private Endpoint. Then the activity compute will be dedicated to your resource.
LikeLike
I did try that today, unfortunately that made no difference. It seems that it is some overhead that is generated by the design of ADF. How do you solve this duration issues with your customers? Or there is no case when the customer needs to run it’s integration really fast?
Apart from that, I would really like to thank you for your excellent framework and that you are giving it out for free for others – that is truly amazing. I’m playing with it for two days and I already fell in love with it. Thank you!
honza, Joyful Craftsmen
LikeLike
I’d take the view that ADF is really for batch work loads.
If you need something faster you need to consider a streaming pattern.
Or, maybe something more event based.
Thanks 😊
LikeLike
Could you elaborate on the reasons you advocate incremental deployments to “higher” environment despite of complexities you mention? I am generally(not specific to ADF) of the opinion that full deployments(when it comes to code) are the way to go to simplify the flow and minimize risks of inconsistencies. Is there something ADF specific that I am overlooking?
LikeLike
When dealing with large enterprise Azure estates breaking things down into smaller artifacts makes testing and releases far more manageable and easier to control. Little and often. A full deployment of everything can be a nightmare to roll back. This isn’t specific to ADF. It applies to all resources.
LikeLike
I agree with your sentiment but believe that the right answer should be having ADF per “deployable project”. So you just blow it away and recreate on redeployment. It does not affect runtimes, that should be shared(even if we are using self hosted option they still can be shared).
LikeLike
One of the awesome post I found on Azure data factory so far.
LikeLike
Hi,
I’m not sure if i’ve seen anything on validation for pre and post processing, i’d like to check file contents and extract header and footer record before processing the data in ADF, once processing completes i’d like to validate to make sure i’ve processed all records by comparing the processed record count to footer record count.
any suggestions on how to handle this optimally?
Thanks
LikeLike
Option 1, use the validate activity. But it’s fairly limited.
Option 2, parse the diagnostic logs in Log Analytics with a Kusto query performing the validation and reconciliation checks as needed.
LikeLike
Hi,
Have you been in a situation where you have many developers working on the same data factory at the same time? I ask because we are starting our first data factory development and will have up to 5 developers working on their own units of work, but their ultimate output will be a single data factory that will be deployed to UAT, Production, etc.
We are looking at 2 options:
1. Each developer creates their own resource group, data factory, etc. and link it to a common git repo.
2. All developers work in a common data factory linked to common git repo.
In both cases the changes would be committed to feature branches and merged back to main via pull requests.
LikeLike
Hi,
I am starting a new development with up to 5 developers all working on the same data factory and I was wondering how this will work and if there are any issues that you are aware of.
We will be using git integration and each developer will create feature branches from main and then merge changes back to main via pull request.
However its been suggested to me that we give each developer their own resource group and separate copy of the data factory, instead of all using a common resource group and data factory. We would still co-ordinate the code changes via branching and merging but would this setup work or is it an unnecessary overhead?
Also I don’t anticipate any issues with adf_publish as we are using azure.datafactory.tools for publishing and deployment.
LikeLike
Hi Paul
Great article, have you tried implementing CI/CD for a ADF which has a SSIS IR ?
In my case I’m trying to implement CI/CD for a ADF development environment which would release into a ADF Production environment. They allow to share the IR between several ADF instances if its for a self hosted IR but not for SSIS IR. So with MS support advice I have separated the Dev and Prod DW databases into 2 different servers and implemented SSIS IR for both. But still could not figure out how the deployment can be done for the SSIS IR. Inside the deployment tried changing the link of the SSIS IR to the production using the ARM template, which did not work.
Any information that can lead me on the correct path would be highly appreciated..
Thanks in advance ..
LikeLike
Regarding using custom error handlers. There has been a fail activity available for a couple of months now that lets you do just that.
LikeLike
Awesome post! Defintely will be using some of the tips in upcoming projects. I have two main questions.
1. What are your thoughts on number of integration runtimes vs number of environments? If I have dev, test and prod, then does that translate in one IR in dev, one IR in test and one IR in prod (assuming they are all managed by Azure) ? Or should IRs be created based upon region or business area or some other logical separation?
2. With the latest updates to ADF for CI/CD do you still agree to use powershell for incremental deploys? Normally when I deploy functions, storage, api management apis or any other component its all or nothing so that there is consistency between what is in the repo and what is in the environment.
Thanks
LikeLike
Regarding the poiwershell deployment. In our project we have been using the devops release pipeline task extension, also impelemented by Kamil, which use his power shell libraries under the hood. Perhaps you could mention this great extension here as well?
LikeLike
Could add ADF testing as well, expression language used in various activities should be tested for various scenarios.
LikeLike
Thanks, @MRPAULANDREW for this article. Will surely follow these best practices
LikeLike
Thanks for a great article and sharing knowledge with everyone! One of the very organized tutorial kind of explanation covering all key areas to be considered in an enterprise project.
Would you be able to recommend any templates on how to better document high level design (HLD) of a complex data-factory project involving multiple sources (Oracle DBs/CSV files etc.), thousands of tables, high volume data (~billions) to cover and document the details of all the sections you have highlighted in your article.
Also, I would like your feedback on how to dynamically handle deletes in destination tables when data in source tables are deleted. Does ADF has an OOB solution for it?
Thanks in advance!
ST
LikeLike