Just a very quick post with lots of pictures 🙂
![]() SQL Server 2019 Big Data Clusters are still in private preview and I’m currently running with version CTP 2.1. However, I wanted to share some of the exciting new features we can expect from this latest big data tech in terms of tools, management and monitoring capabilities.
SQL Server 2019 Big Data Clusters are still in private preview and I’m currently running with version CTP 2.1. However, I wanted to share some of the exciting new features we can expect from this latest big data tech in terms of tools, management and monitoring capabilities.
If you aren’t sure what SQL Server Big Data Clusters are, there is a great overview post by Microsoft’s Travis Wright here:
Or, grab the white paper here:
https://info.microsoft.com/ww-landing-SQLDB-Microsoft-SQL-Server-WhitePaper.html
So, tools, management and monitoring. All images clickable to enlarge or in my GitHub repo.
Blog Supporting Content also in my GitHub repository:![]()
https://github.com/mrpaulandrew/BlobSupportingContent
Tools
Let’s kick off with an obvious one, our long standing friend SQL Server Management Studio (SSMS). Since the application became stand alone from SQL Server we’ve had a fairly aggressive release cycle with lots of shiny new additions, all of which rely on you using Windows as our operating system.
SSMS v18
Version 18 of SSMS gets it’s new version number because it now uses Visual Studio 2017 as it’s shell. So a fairly significant release for the application.
If you want to interact with SQL Server 2019 you’ll need version 18 of SSMS, regardless of whether your using a conventional SQL instance or you want to access the master instance for your big data cluster.
Public preview features can be found here: https://cloudblogs.microsoft.com/sqlserver/2018/10/03/ssms-18-0-public-preview-released/

Azure Data Studio
Next up, our cross platform tool Azure Data Studio. Previously called SQL Operations Studio. In the below screen shot I’ve connected to the SQL 2019 Big Data Cluster master instance and get a very similar view to SSMS. Although with Data Studio I also need several VS Code plugins to support everything I want to see for the SQL Agent etc. Again, not really any surprises here.
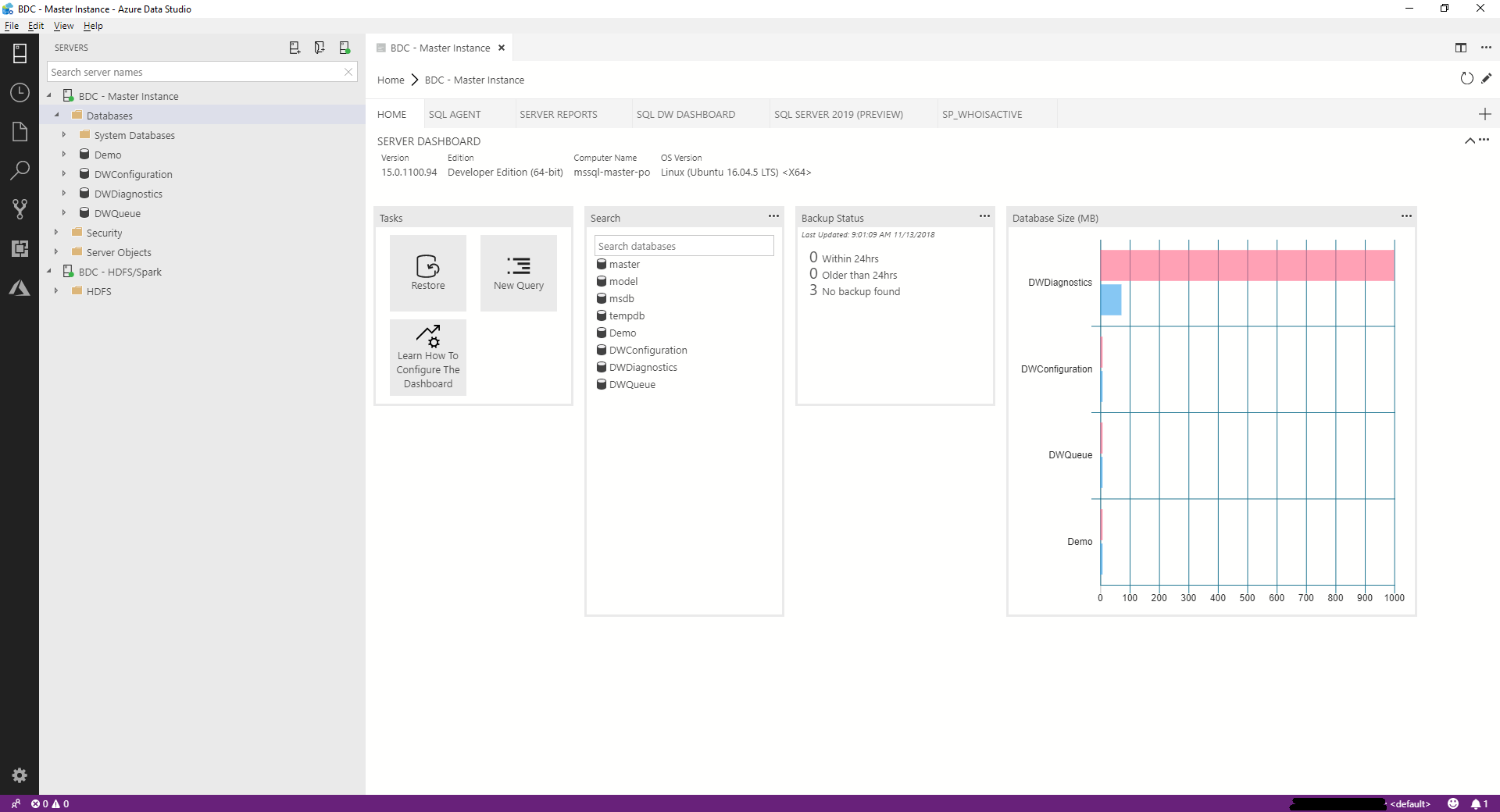
This is where things get a little more interesting…

With the SQL 2019 Big Data Cluster plugin, installed manually, from here. I can now access my Storage Pool (Data Lake), write Notebooks and submit Spark jobs! Yes, we are still talking about a SQL Server product 🙂 Very cool.
Management
I was an accidental DBA in a previous life so do appreciate having the occasional web based pretty interface to view my cluster and manage things.
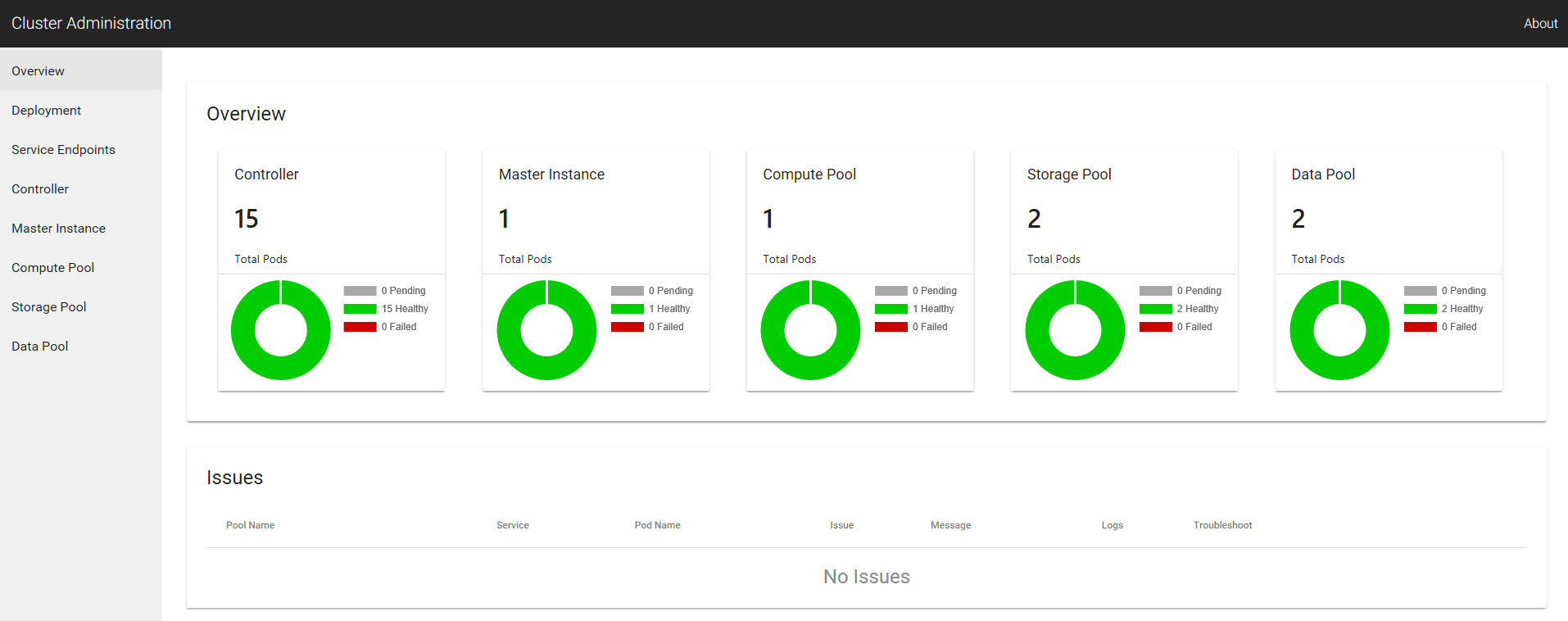
Cluster Administration Portal
Via the cluster admin portal we can’t do much yet. However, during the Ignite videos the demo suggested this was going to become the main area for all cluster related admin tasks. Currently we can just view our Kubernetes pods and its a handy place to get to our other Service Endpoint IP addresses.
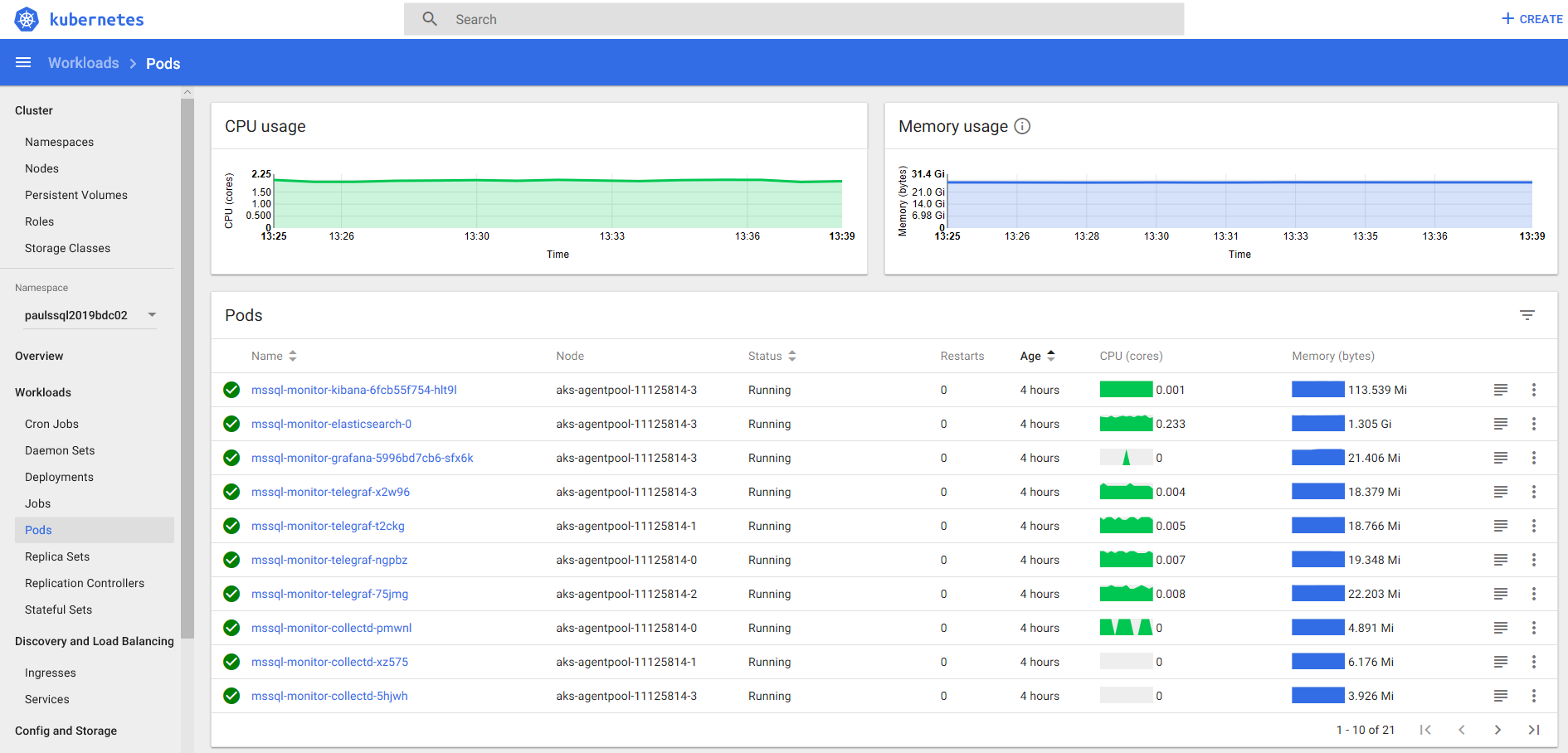
Kubernetes Portal
The Kubernetes dashboard isn’t anything new for most container people. However, it was a first for me seeing it after creating an Azure KS to run my SQL 2019 Big Data Cluster. It’s very handy having command line access to the container services through a browser. I get to this a tunnel can be created using the Azure CLI because the dashboard doesn’t have an external IP address.
Monitoring
Again, a little more excitement here when using a Big Data Cluster. Firstly, Grafana dashboards. Setup and configured out of the box, very pretty and movement in real-time.
Grafana Dashboards
These dashboards currently come in two main flavours:
- Cluster node metrics showing CPU, RAM and disk usage.

- SQL metrics showing transactions per second, batch requests and wait stats.
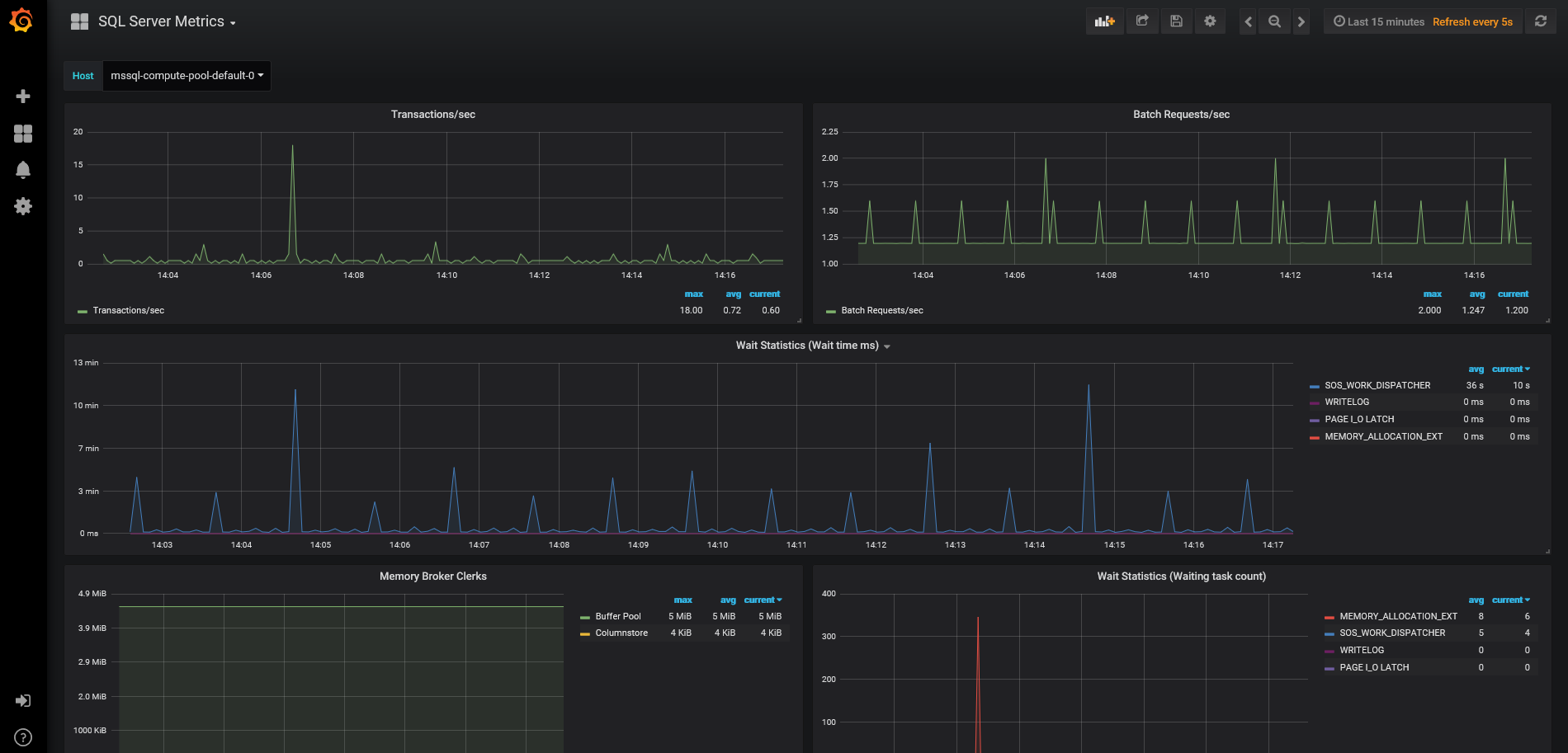
To access them I recommend using the links under ‘Master Instance’ in the Cluster Administration portal.
Spark History Server
Lastly, we have our Spark logs. For anything Spark related done via our new Notebooks we can drill into the job detail here via our Spark History Server. I got the external IP for this from my Cluster Administration portal Service Endpoints panel.

I hope you found this quick (picture heavy) post informative and raised your excitement for SQL Server 2019 Big Data Clusters 🙂
Many thanks for reading.

So right now this is SQL Server only, but wondering if you know if there will be an Azure PaaS version? It looks like this could become a strong alternative to Azure Databricks in the future.
LikeLike