As a follow up to my blog about Data Factory resource limitations here. I decided to dig deeper and expose some of these limitations with a view to understanding what happens to your pipeline when/if you hit them.
In this post I’m focusing on the Activity Concurrency limits, as a reminder:
| Resource | Default limit | Maximum limit |
|---|---|---|
| Concurrent pipeline runs per data factory that’s shared among all pipelines in the factory | 10,000 | Contact support. |
| Concurrent External activity runs per subscription per Azure Integration Runtime region External activities are managed on integration runtime but execute on linked services, including Databricks, stored procedure, HDInsights, Web, and others. |
3000 | Contact support. |
| Concurrent Pipeline activity runs per subscription per Azure Integration Runtime region Pipeline activities execute on integration runtime, including Lookup, GetMetadata, and Delete. |
1000 | Contact support. |
Firstly, understanding how these limits apply to your Data Factory pipelines takes a little bit of thinking about considering you need to understand the difference between an internal and external activity. Then you need to think about this with the caveats of being per subscription and importantly per Azure Integration Runtime region.
Assuming you know that, and you’ve hit these limits! 🙂
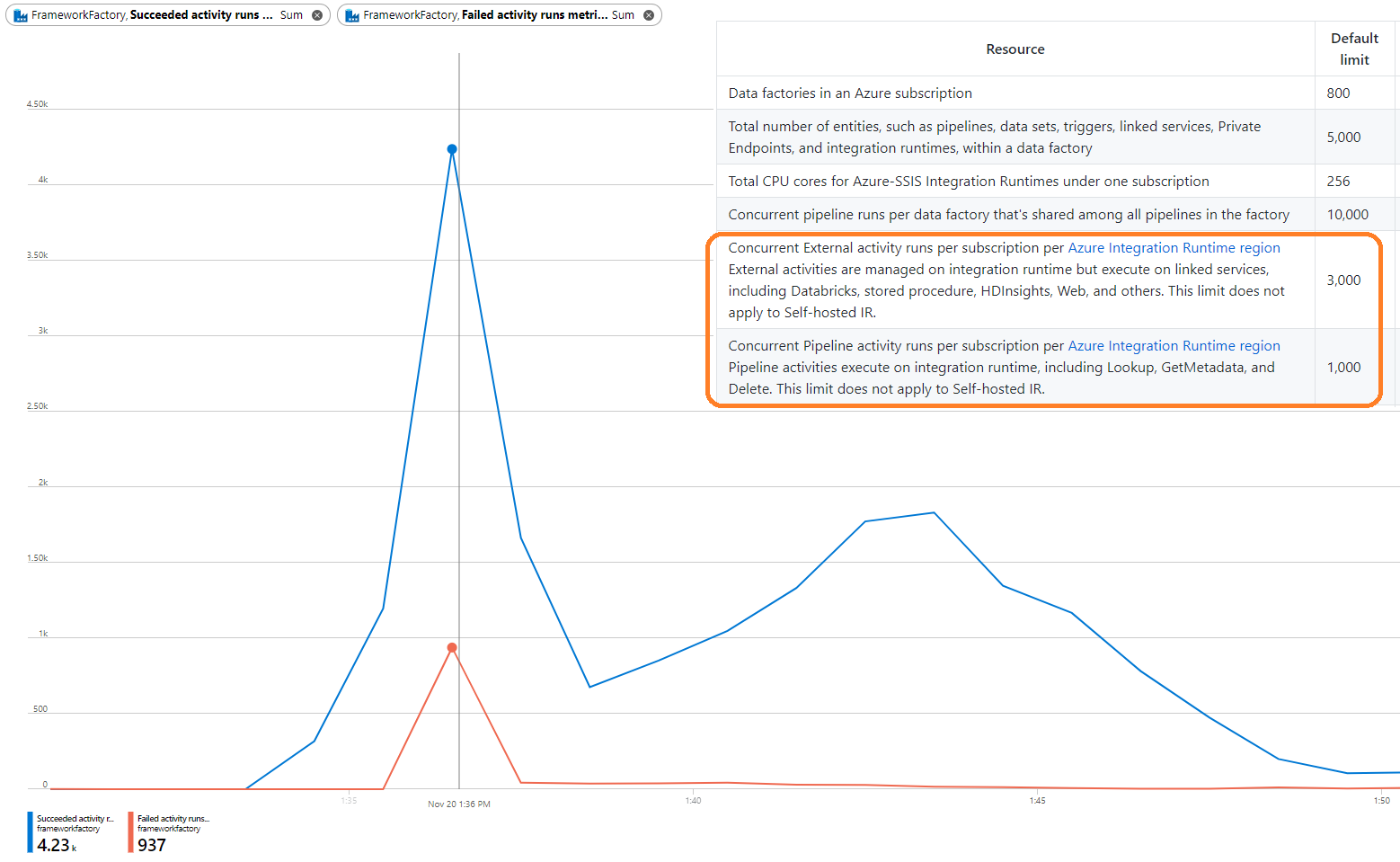
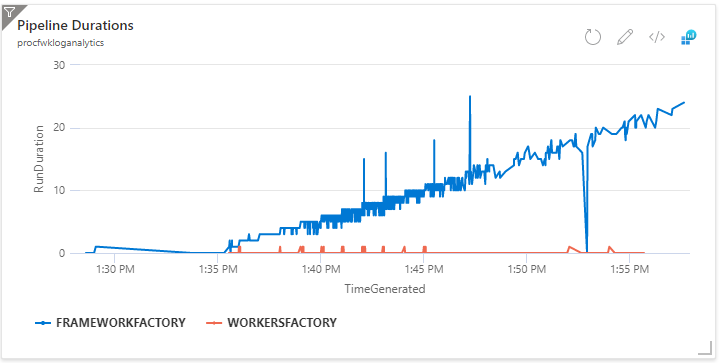
… As the blog title suggestions, what happens next?
In short, nothing.
- Pipelines fail.
- Activities fail.
- They don’t queue.
- They don’t even start.
- They don’t even try.
- They don’t offer any error messages. See 2min video:
They just fail.
So, if you hit the activity concurrency limits, you’ll have a pile of Data Factory pipelines with fail status values all over the place with no obvious reason what has happened.
You might think, why don’t you have a failure path to another…. erm…. ???? What, another activity? When you’ve hit the limit? 🙂
What about using another Data Factory to bootstrap and monitor the first one to catch failures?… It’s not going to help; the limit is per subscription. Maybe if you have the bootstrap factory in an isolated region. But monitoring everything, every pipeline and every activity for a failure that you can’t easily identify isn’t realistic.
My current advise is:
- Carefully understand these limits.
- Design for using multiple Azure regions if possible.
- Refactor your internal activities, especially things like setting variables. Do you really need them?
- Ask Microsoft to increase your limit.
Obviously a fairly specific topic, but hopefully a helpful one to understand.
Many thanks for reading.

One thought on “Data Factory Activity Concurrency Limits – What Happens Next?”