 Azure Data Factory & Azure Synapse Analytics Integrate Pipelines
Azure Data Factory & Azure Synapse Analytics Integrate Pipelines

In this post I want us to explore and understand the difference between an internal and external activity when using our favourite orchestration pipelines. I’ll focus predominately on Azure Data Factory (ADF), but the same applies to Azure Synapse Analytics.
*Warning: this is a fairly dry, deep dive-ish blog post. So much so I confess to have put off writing for a long time due to its dry-ness! Glass of water/wine required.* 🙂
Firstly, you might be thinking, why do I need to know this? Well, in my opinion, there are three main reasons for having an understanding of internal vs external activities:
- Microsoft cryptically charges you a different rate of execution hours depending on the activity category when the pipeline is triggered. See the Azure Price Calculator.
- Different resource limitations are enforced per subscription and region (not per Data Factory instance) depending on the activity category. See Azure Data Factory Resource Limitations.
- I would suggest that understanding what compute is used for a given pipeline is good practice when building out complex control flows. For example, this relates to things like Hosted IR job concurrency, what resources can connect to what infrastructure and when activities may might become queued.
At this point I should probably qualify my terminology, when I say ‘activity category’, I mean the difference between internal and external. I wanted to refer to this as the activity type. However, this would go against the existing meaning of activity type, relating to what the activity does. For example; a Web activity or a Copy activity. So, activity category is what I’ll use for this post.
Next, let’s focus on points 2 and 3 above. Both relate to compute, which in Data Factory can also be a little confusing given the underlying separation of orchestrator from it’s integration runtimes (IR). If you aren’t familiar with IR’s, check out the below Microsoft docs page for the information on the three types of IR available in ADF.
https://docs.microsoft.com/en-us/azure/data-factory/concepts-integration-runtime
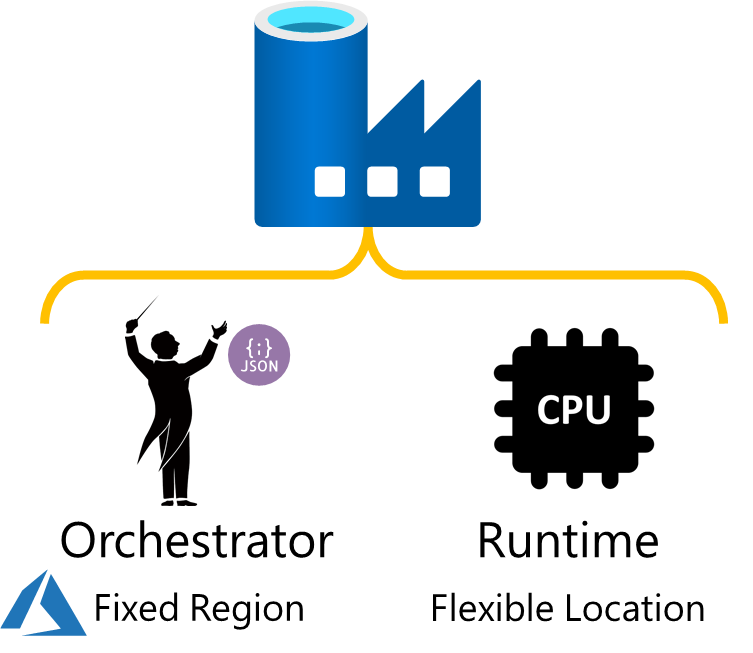
Like other Azure resources and cloud services in general separating/decoupling storage and compute offers a lot of advantages. In ADF, we can extend this by saying the control plane (the orchestrator) is separated/decoupled from the compute (the IR’s). It is that compute that gives us our first clue about the activity categories.
To define our activity categories in the context of our IR’s we could crudely say that activities calling other resources via linked service connections are external and those where we don’t define a linked service are internal. In this statement I’m also siting the fact that IR’s are set against our linked service connections. This is reasonable starting point for our activity categories but there are exceptions, these include our Data Flow and SSIS Package activities.
Ok, confused yet? 🙂
Let’s move on with a less confusing table where I can definitively tell you which activity type falls into which category. Later we can then revisit our definition based on what we know about the different activity use cases. I’ve also added the concurrency limits to the table as a reminder.
Special thanks to Microsoft PM Abhishek Narain for validating this list for me.
| Activity Category | Activity Type | |
| External
Concurrency Limit:
3,000 |
Azure Data Explorer Command |  |
| Azure Function |  |
|
| Azure ML Update Resource |  |
|
| Azure ML Batch Execution |  |
|
| Azure ML Execute Pipeline |  |
|
| Custom (Azure Batch) |  |
|
| Databricks Notebook |  |
|
| Databricks Jar | ||
| Databricks Python | ||
| U-SQL (Data Lake Analytics) |  |
|
| HD Insight Hive |  |
|
| HD Insight MapReduce |  |
|
| HD Insight Pig |  |
|
| HD Insight Spark |  |
|
| HD Insight Streaming |  |
|
| Stored Procedure |  |
|
| Web Activity |  |
|
| Internal
Concurrency Limit:
1,000 |
Append Variable |  |
| Copy |  |
|
| Data Flow |  |
|
| Delete |  |
|
| Execute Pipeline |  |
|
| Execute SSIS Package |  |
|
| Filter |  |
|
| For Each |  |
|
| Get Metadata |  |
|
| If Condition |  |
|
| Lookup |  |
|
| Set Variable |  |
|
| Switch |  |
|
| Until |  |
|
| Validation |  |
|
| Wait |  |
|
| Web Hook |  |
|
Given the above we can now harden our definition and understanding of our activity categories.
- External activities use compute that is configured and deployed externally to Azure Data Factory.
- The Web activity recently became external in order to support its use on Hosted IR’s, ultimately allowing Data Factory access to “extend the orchestration into the customer’s network.”
- Internal activities use compute that is configured and deployed by Azure Data Factory.
- Typically this means the activities are using the default ‘AutoResolveIntegrationRuntime’ Azure IR for execution.
- The SSIS Package activity can be consider internal because it’s compute (the SSIS IR) is configured and deployed by Azure Data Factory. Also, the SSIS IR cluster is charged separately.
 For completeness in Azure Synapse Analytics – Integrate Pipelines we also have the following new external activities.
For completeness in Azure Synapse Analytics – Integrate Pipelines we also have the following new external activities.
Please also be aware that SSIS Package execution isn’t supported via Synapse so we don’t have those activity or IR types available via the Synapse Workspace.
| Activity Category | Activity Type | |
| External | Synapse Notebook |  |
| Synapse SQL Pool Stored Procedure | |
|
| Synapse Spark Job | |
|
I hope this post helps in your understanding of:
- Resource Charging
- Activity Concurrency Limits
- Orchestration Compute
Many thanks for reading

“PIPELINES – UNDERSTANDING INTERNAL VS EXTERNAL ACTIVITIES” Excellent and very cool idea and best content of different kinds process of the valuable information’s.
https://www.kellytechno.com/azure-data-factory-training-in-hyderabad/
LikeLike