Should Data Domains Be More Than a Simple Structure?
Spoiler alert… Yes… Based on my experience.
Read all blog posts in the Data Mesh vs Azure series via this link.
Context
Defining an organisation hierarchy is always hard, even more so for large enterprises with massive amounts of interlock between business functions. In the context of data analytics, we attempt to tackle the problem by creating an organisation dimension as part of our star schema data model. This could include things like region, operating company, branch, department, team etc.
So, my friends, how do we go about handling this when considering a data mesh architecture and the de-centralised domains that support the natural scalability we crave. For me, it feels like we are just frontloading the dimensional modelling problem. Tackling it from the beginning in the very foundations of our data platform. But, with a twist.

In a data mesh we don’t have to think about an organisation hierarchy as a simple tiered structure. We can think about it like the Olympic Rings (maybe). As circles. One circle per domain. Circles that overlap, where domain ownership can be shared at the point of intersection. These domain circles then include our mesh data products at a lower level.
Given my usual musings and thought process this felt like a good topic to address next in this blog series. One that I hear a lot when customers start out considering a data mesh architecture. I’m even tempted to go as far as thinking about the problem aligned to the Spotify operating model, bear with me. Because data mesh teaches us that we need to think about people and process, not just technology. The people that need to be organised around the work. Not in exactly the same way as we would from a pure delivery/build perspective. But, certainly similar. Domain owners (people) organised to facilitate data product work and scale. Tell me if I’m stretching too much here, but I think there is some correlation.
Ok, enough waffling, let’s draw something. I must visualise things. By brain doesn’t work without pictures.
Theory
In our idealistic data mesh, we have domains and products, with a few, not all interface lines thrown in. Perhaps like the below. Nicely de-centralised and scalable with clear boundaries.

Reality
The reality, as I often find it when working with customers, is that we start with our domains more like the below. Fairly confused, no clear boundaries and lots of outliers.
All interface lines fully inferred this time to avoid making the picture becoming even more of a mess/mesh! 😉
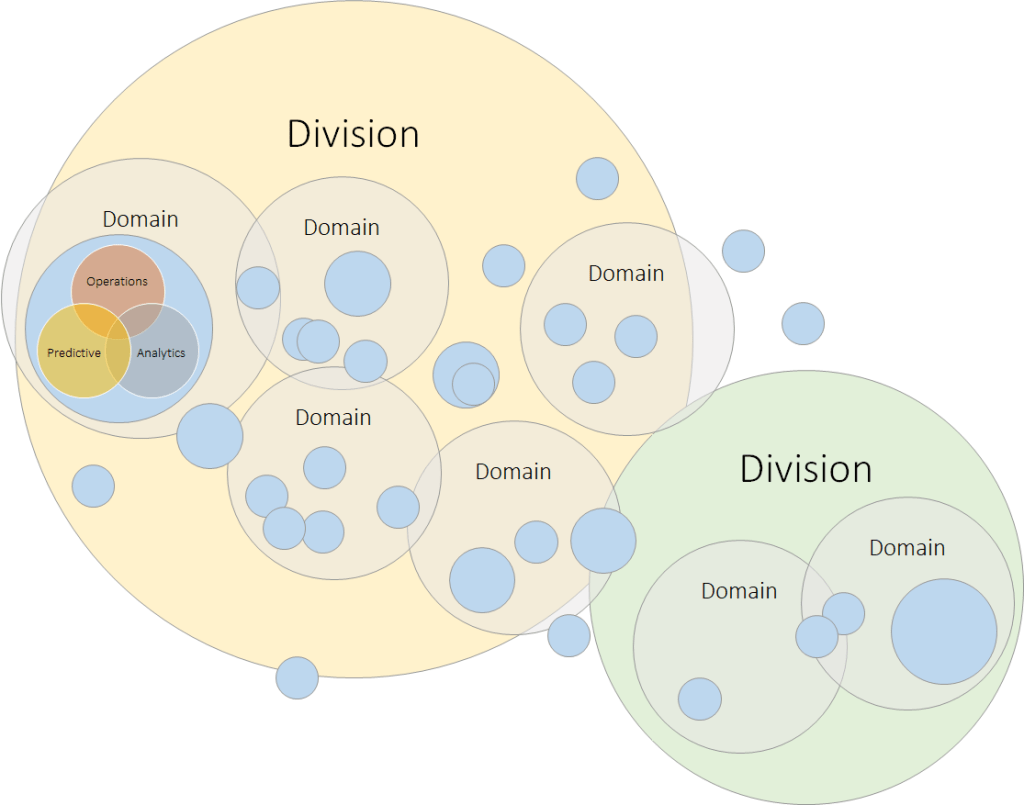
Here I’ve extended our domains and products in both directions, because we have to.
- Domains are part of wider divisions or business functions or segments or operating companies. Whatever terminology you prefer to exchange for division.
- Products that can be/need to be split by:
- Operations
- Analytics
- Predictions
There is certainly a side conversation here about the scope of data mesh and if transactional data is included or our mesh is purely for analytics use cases. Let’s avoid that one for now. I’m going with a data product that contains both.
Given the below, if we want to be simple about this as a hierarchy, fine…
- Business Division/Function/Segment
- Data Domain
- Data Product
- Operational/Transactional Data
- Data Analytics
- Predictive Data
- Data Product
- Data Domain
BUT, this can and will be broken and isn’t always as clean as the bullet points suggest. We might have newly formed data products floating around the outside. Or new teams that create fledgling areas of the business that haven’t yet me considered as part of a domain. The natural growth and evolution of organisations (of all sizes) means this will happen.
Now, the question really playing on my mind…
Should we bend the organisation to fit with our ideal data mesh as part of the implementation, or should we accept the current landscape and extend our data mesh definitions, applying the principals where we can? Especially considering what a minimum viable mesh might look like.
It depends 🙂
Having attempted both approaches (former and latter), my current view is one of pragmatism and a hybrid way of working.
- A little bending, but not so much it makes the bar to entry to high when delivering a data mesh.
- A little extending but not so much we dilute the principals beyond the point of being controlled or even valid.
Then, as we scale/grow from the brown field implementations into green field delivery we will (over a long period of time) become more “uniform”. The hope being that the uniform (data mesh federated governance) will become second nature to us and with-it delivery velocity. Faster insight, better decisions. Self-serving data platforms, no problem. Click-click, done.
Practice
This means in (let’s say) 3 – 5 years’ time. We will be able to redraw the picture like the version below. An applied, but extended, data mesh that we’ve been running with and has been used (probably with a great degree of difficulty and discipline) to clean up our organisation structure and improve our overall operating model. A data mesh of scalable domains, with boundaries defined overtime.
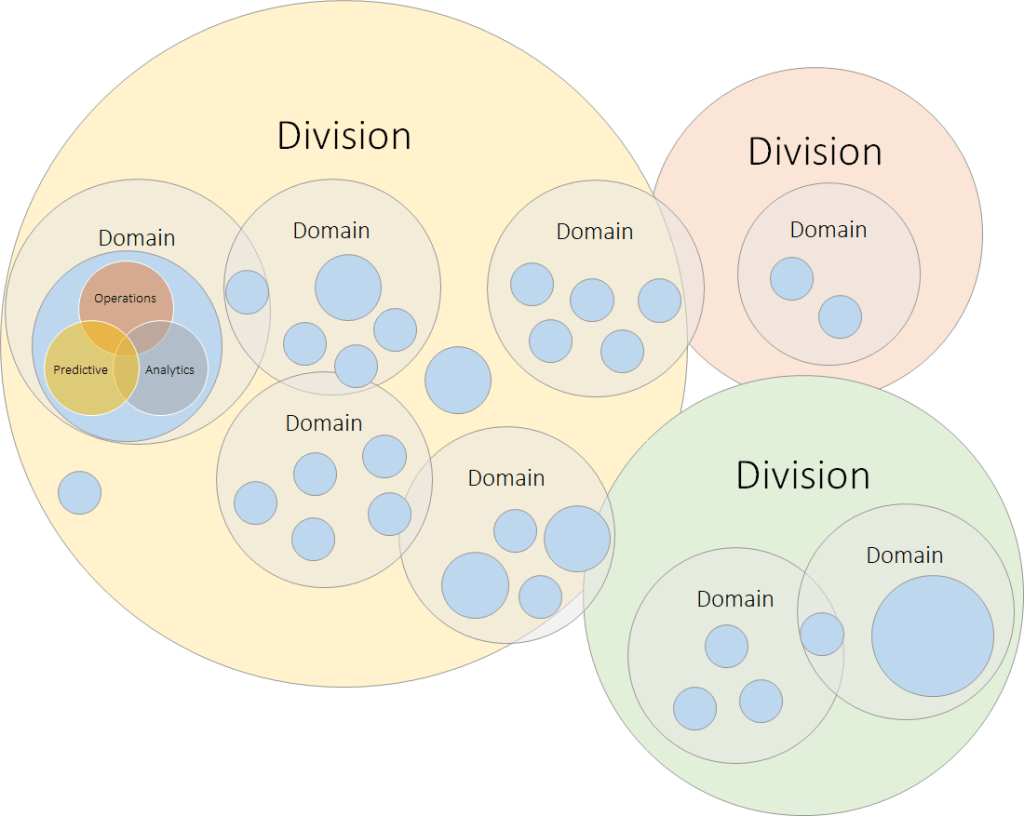
Conclusion
Staying true to the theme of this blog series. Data mesh – data domains, theory vs practice, to offer an end-to-end view of the point I’m making:
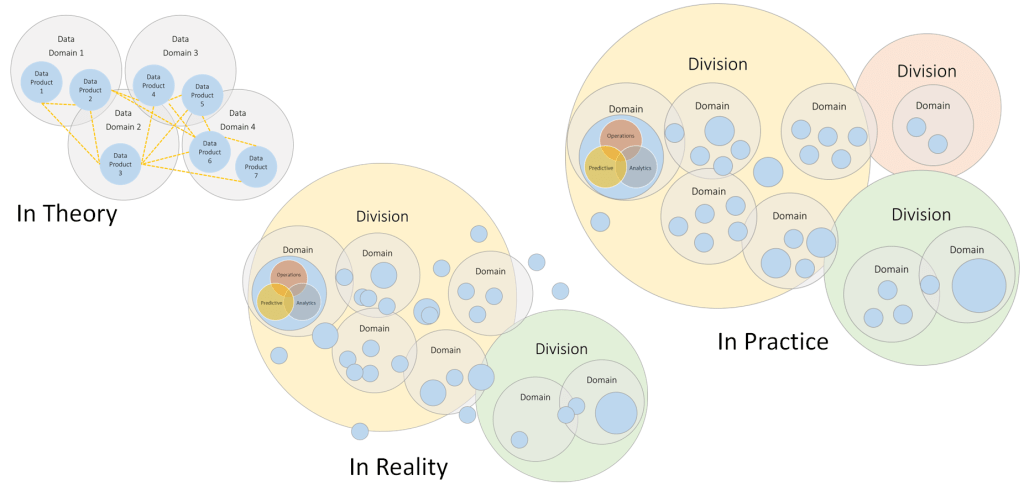
To be clear, in Azure we are basically forced into adopting this approach anyway, because everything has to sit within an Azure Subscription (AKA our data domains). The reality might allow a separate Tenant for sandbox work, sure. But when moving to production things need to be structured, to reference my implementation thoughts from part 5 of the blog series.
Please let me know your thoughts and how you’ve handled this.
Many thanks for reading.

That’s what I am experiencing at the moment,
This! Organization change is hard and takes time, and we have to change to be able to deliver value.
“Should we bend the organization to fit with our ideal data mesh as part of the implementation, or should we accept the current landscape and extend our data mesh definitions, applying the principals where we can?”
Thank you for the article Paul.
LikeLike
Exceptional guide! ‘Building a Data Mesh Architecture in Azure’ offers clear insights and practical strategies, making it a valuable resource for data architects.
LikeLike