Data Mesh vs Azure –
Theory vs practice
Use the tag Data Mesh vs Azure to follow this blog series.
As a reminder, the four data mesh principals:
- domain-oriented decentralised data ownership and architecture.
- data as a product.
- self-serve data infrastructure as a platform.
- federated computational governance.
Source reference: https://martinfowler.com/articles/data-mesh-principles.html
In Part 1 and Part 2 of this blog series I defined our Azure data mesh nodes and edges. With the current conclusion that Azure Resource Groups can house our data product nodes within the mesh and a good edge interface could/should be a SQL endpoint of some flavour for our primary data integrations.

When thinking about our node edges in part 2 I also made the statement about a primary set of node interfaces. In my initial drawings I alluded to this then capturing what I’ve called the PaaS Plane, suggesting the Azure Resource type used.
Building on this understanding I want to cover off the remaining edge use cases by exploring the other interface types we will typically need for the nodes of our data mesh architecture.
In addition to the primary interfaces, I want to define secondary and tertiary interfaces as follows:
- Primary – data integration/exchange.
- Secondary – operational reporting and logging.
- Tertiary – resource (network) connectivity.
Let’s explore the practical implementations for these in this blog post.
Edges (Secondary Node Interfacing)
Staying on the PaaS Plane the focus for our secondary interfaces is operational reporting, monitoring, logging and alerting (to name a few). Often the long term implications of building a platform are forgotten at design and development time. To correct this, I suggest that when moving from the theory of the data mesh, to the practical implementation an operational lens should be applied to the data product nodes as standard. Not just for data integration, but considering the roles of a ‘managed services’ team or service desk function.
Enter our data product node picture from before, but this time with a set of secondary monitoring interfaces:

The key to these secondary interactions is the Diagnostic Settings telemetry available for the majority of our Azure Resources (represented with the green book icon in the picture above). This telemetry can be sent to:
- Azure Log Analytics – for querying using the Kusto query language (KQL) as well as creating rich dashboards in the Azure Portal. As a side note; KQL can now be written and executed using Azure Data Studio, see: https://docs.microsoft.com/en-us/sql/azure-data-studio/extensions/kusto-extension?view=sql-server-ver15
- Azure Event Hub – if the resource requires a real-time stream of telemetry for business-critical system monitoring.
- Azure Storage – for the long term and archiving of all telemetry data that could later be querying using Azure Data Explorer, for example.
See the following Microsoft Docs page for more details on doing this with Azure Monitor: https://docs.microsoft.com/en-us/azure/azure-monitor/essentials/diagnostic-settings
This covers the ‘out-of-box’ functionality that we should implement for our data mesh node secondary interfaces. There are of course many other custom logs and event based outputs we might want to create. For example, we could use Azure Application Insights to return data processing metrics from our Azure Databricks Notebooks.
Edges (Tertiary node Interfacing)
Moving to the IaaS Plane, here I want to define and think about the requirements for our Azure Resources to interact using none-public network connections and endpoints. Or, simply put, our network connectivity. This is certainly another aspect missing from the data mesh theory that needs to be considered when put into practice.
Using private connections for resources is completely optional but recommended to add an extra layer of security to solutions running on public cloud platforms. To caveat this section, I’m not a security or network architect, but hopefully I can articulate enough to cover the points of our implemented data mesh architecture.
Enter our data product node picture once again, but this time with a set of tertiary network/connectivity interfaces:

In this context we have many different options to choose from and many different combinations of what is supported for different Azure data resources.
As a starting point I suggest every node within our data mesh architecture has its own Azure VNet. This could be managed or unmanaged depending on the data resource compute implemented.
Next, how should a given nodes VNet and resource communicate with the other nodes in the data mesh as well as any on premises LAN services?
Option 1 – Full Vnet Peering

Every node has its VNet peered with all the other nodes within the mesh. If you have a limited numbers of nodes this could be an option. But, it would mean for every new node added a redeployment is required for every other node within the mesh. I would say this is almost certainly a bad approach and only included for completeness. Having a limited number of nodes also breaks the data mesh theory of scalability.
Option 2 – Hub and Spoke VNet Peering
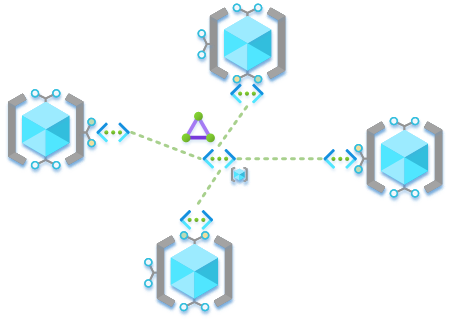
A central (hub) VNet used, with every node VNet peered to that as spokes, this is the most common pattern I’ve seen implemented. However, there are advantages and disadvantages of this approach. Scaling and adding new nodes doesn’t require redeployments like option 1 and the hub VNet could also support things like our Express Route circuits. The main disadvantage is cost, if this is a factor for your solution. Each node-to-node communication requires a double hop via the hub VNet which Microsoft kindly charge you extra for within the region as inbound and outbound data transfers (per GB) as well as cross region transfers. For clarity this is different to Azure ingress/egress charges. See the Azure VNet Pricing Calculator for details: https://azure.microsoft.com/en-gb/pricing/details/virtual-network/
Option 3 – Targeted Service/Private Endpoints
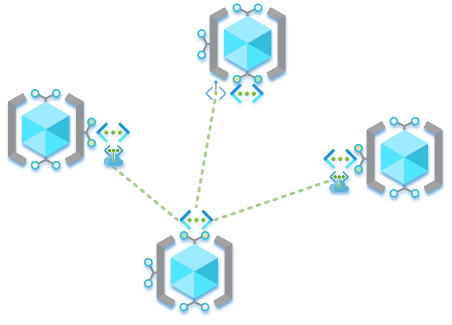
Using targeted Service Endpoints and Private Endpoints for only the communications required between nodes. For example, node 1 wants data from node 2 so a Service Endpoint is established from the node 2 Azure Storage Account to the node 1 VNet/Subnet.
This approach means potentially a lot of inconsistency and no standard set of tertiary interfaces. But it could allow for better data isolation and the use of floating VNet’s if peering isn’t required. Some network admins may prefer this considering Databricks clusters require huge amounts of IP address space within the Subnets.
Option 4 – Something Else?
This could be another ‘it depends’ situation where we do something else. Maybe using a combination of the above configurations. Or even nothing at all where public endpoints are acceptable for the solution.
Edge Conclusions Update
Separating the PaaS vs IaaS Planes feels like a good logical step when defining the edges for our node interfaces and using the primary, secondary, tertiary definitions shows a clear boundary of roles/skills and deployment requirements.
Therefore, in my opinion, if I then had to choose what to implement my current preference would be:
- Secondary edges delivered with a minimum of Diagnostics Settings enabled for Azure Log Analytics with operational dashboards created with Kusto queries, published to the Azure Portal.
- Tertiary edges delivered using the option 2 hub/spoke approach to Azure VNet Peering. The extra cost seems a reasonable trade off considering the consistency and simplicity advantages. I would also suggest that in development lifecycle or PoC situation option 2 be combined with option 3 for such sandbox nodes that don’t require peering of all resource, maybe!
Many thanks for reading, stay tuned for more in this series of blogs.

Thanks for this third part article, Paul. I agree that Option 2 (Hub & spokes vnet peering) sounds the most reasonable. I wonder how much more costs it could generate in a real scenario. Of course, I know that all depends 🙂
LikeLike
Paul, we spent some time in researching the pattern which allows max throughput and lower costs when using private endpoints. Hub and spoke is something we discounted early on in research and pilots. Link to our published guidance is https://docs.microsoft.com/en-us/azure/cloud-adoption-framework/scenarios/data-management/eslz-network-considerations. It is part of the core design principles and has been implemented at customers which might help Kamil above.
Azure Policies should drive that as services are added to a landing zone, its monitoring is sent to a central log analytics workspace which combines data from the whole tenant. This is part of the design principles for Microsoft Cloud Adoption Framework.
LikeLike
Have you considered Azure WAN as the alternative for a mesh of VNET peers?
https://docs.microsoft.com/en-us/azure/virtual-wan/virtual-wan-global-transit-network-architecture#anytoany
LikeLike
These are great considerations. I’d love to see insights and experiences from real-world implementations. Currently, the concept Data Mesh is widely discussed, heavily promoted by some people, even some books are written, but has anyone actually built something like that with at least “some” success?
LikeLike