 With this post I wanted to write something a little different, something that isn’t directly focused on a particular technology, but is just as important when delivering an enterprise grade solution. Or any solution for that matter!
With this post I wanted to write something a little different, something that isn’t directly focused on a particular technology, but is just as important when delivering an enterprise grade solution. Or any solution for that matter!
Typically we all work in a team delivering Data Platform solutions for our internal/external customers. In order for that project to scale, developers could operate in a Scrum team taking on stories and tasks to complete subsets of the overall solution, hopefully this sounds familiar.
Then at some point the architect (the person technically accountable) needs to make sure that what has been created by the developers matches expectations in terms of design, performance, quality and best practice. To name a few things.
The first stage in doing this is what I refer to in the title of this blog post as a peer review. In this review, code produced by one team member is reviewed by others. Again, hoping this sounds familiar.
In order for this review to be successful the reviewers have to look closely at someone else’s code and understand the mindset of what is being created. This is hard. Context is everything and often in any coding situation there are many ways to do the same thing.
Given this situation and these challenges, I’ve created the below script and check list of things I like to follow when reviewing someone else’s code, I’ve written this in a blog for my own reference and to help guide others doing peer reviews.
So let’s dive in and set the scene…
Developer
- Some code has been written to deliver part of a Data Platform solution.
- The code has been written in a feature branch of the repository (maybe using Git).
- A commit and push of all the latest code has been done against the feature branch.
- A pull request has been raised to merge the feature branch back into the core solution branch, maybe ‘master’ or something else depending on your repository branching strategy.
- You request a review of the pull request before the operation is completed.
Reviewer
Using your favourite pull request tool (let’s assume Azure DevOps) you need to review and feedback to the developer on the feature produced/updated.
Then the pull request can be approved and completed.
Checking Script
Firstly, make sure the pull request isn’t too large, guidelines suggest limiting code reviews to 400 – 500 lines of code or 30 minutes of time, which ever comes first. If the pull request exceeds this I recommend you don’t even start the check list below and refactor the code into smaller byte size bits – puns intended! 🙂
Assuming we can proceed as a reviewer, I think we should be checking code as follows. I’ve tried to be technology agnostic with this checking script but couldn’t avoid mentioning certain tech in the examples provided, sorry. I’ve also tried to group these points naturally into basic stuff, cosmetics, coding standards and wider resource thoughts.
| Point | Check Done | Examples/Notes/Context |
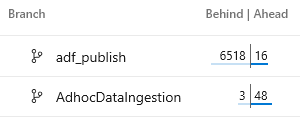
| 1 | Has a code merge from the core development branch been done before the pull request was raised?
Or to phrase that question differently; if the feature branch is now behind our core development branch commits are we risking other changes being undone if the pull request is completed? |
In Azure DevOps you can easily see for a given code branch how far ahead and behind it is via the UI.
|
| 2 | Are there any conflicts in the feature branch? Ideally this should have been addressed by point 1. So just a double check. | In the event of a conflict a choice needs to be made:
Visual Studio does the manual merge fairly nicely for most languages where I’ve had to deal with such a conflict. |
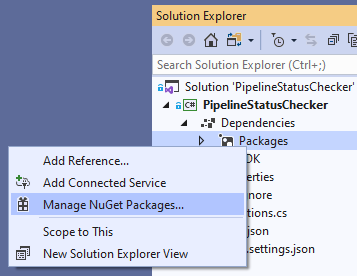
| 3 | Has the code been written using the latest version of the respective Software Development Kit (SDK)? | In the case of a C# project I would want to check the latest version of any NuGet packages has been implemented for example. You might need to do this via Visual Studio for ease in the package manager.
Also, consider that there might be some pre-release libraries that we want to avoid putting into a production environment at this stage.
|
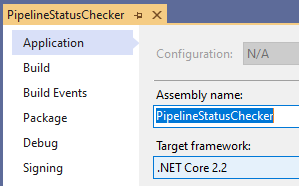
| 4 | Is the code project using the latest version of the development framework?
If yes or no, are there any referenced libraries that are now mismatched and also need to be updated? |
As I write this .NET Core 3.1.1 has only just been released.
Are you up to date with the security patches included? |
| 5 | Does the code include good comments? Things that explain the reason why logic has been implemented to assist future developers looking at the same code.
All too often, I see code comments written that just translate from code to English and tell me what is happening. What should be fairly obvious to the reviewer as they read the code. Why is so much more important. |
I previously wrote a blog post here on how I like my Databricks Notebooks to be structured. This includes lots of markdown and rich comments for others to understand the mindset of the author.
|
| 6 | Building on point 5. Is the code structured in a way that is easy to understand? |
|
| 7 | Have functions and methods been created in a way that is generic?… Meaning can the code be reused else where? | As we know abstraction solves everything! So be careful.
The key is to get the right balance of reusable or abstracted methods where useful to do so vs building bespoke logic into functions that then make the process even harder to understand. |
| 8 | Similar to point 7. Have functions and methods be written or re-written in a way that offers the ability to create further overloaded versions of the same?
This then supports forwards and backwards compatibility on new code and new requirements without breaking existing code that has already been deployed. |
If we have a generic method how many different signatures should that method have to support all our requirements?
Here’s a C# example involving me and coffee, click to enlarge 🙂
My tastes may have changed over time meaning I now require more than just the basic implementation. |
| 9 | Is there any ambiguity in the code? Especially with dataset attributes.
This also alludes to a mindset of defensive coding, we need to guard against things that could accidentally happen. |
Joining database tables or datasets is the best example of this.
Two tables joined together both contain a field named ‘Bob’. Which table should Bob come from? Even if there isn’t any current ambiguity, attributes should always be prefixed with the table alias to avoid issues in the future.
|
| 10 | If/when business logic needs to be included in a process, has it been parameterised to offer future flexibility?
Furthermore, are those parameters bubbled up through the solution layers allowing them to be set at the best levels of control. |
To offer a couple examples on this point:
|
| 11 | Often a project will have localised technical standards and conventions. Either dictated by the solution lead or maybe inherited from a customers existing implementation. In which case have the local technical standards been followed in the new code created? | Naming conventions of resources in Azure is an obvious example here. Less obvious examples may include database schemas used to isolate users. Or maybe Databricks Notebooks that inherit a common set of imported libraries. Is there a standard for the alias of these imports?
|
| 12 | Has performance been considered when processing the data? | For these 3 points I want to use the same example of why this might be important in a code review session.
Let’s consider a data transformation is performing poorly in a Databricks Notebook, to improve the workload datasets in the query are broadcast across all worker nodes in the cluster.
Suddenly the ripples of this basic peer review check become much more important and further reaching in the solution than originally expected by the developer. |
| 13 | Does the underlying storage/compute resource used have any limitations that need to be considered as a result of the newly created code? | |
| 14 | Has the cost of the underlying storage/compute resources been considered? Cloud based or otherwise. | |
| 15 | Are there any wider industry best practices that should be considered in the code created? | I accept this check is very general and maybe very vague.
To offer a specific example I’ve previously blogged about Azure Data Factory and my expected best practices for using that particular resource (post link). Depending on the technology used in the pull request being reviewed, I recommend you search for something similar to assist.
|
| 16 | Has the code been written with logging and auditing in mind? | Throughout any solution logging is ultimately what is needed to understand issues, when the solution becomes operational. This logging could be for information only or in the event of critical failures, in either case code should support logging beyond what a service provides out-of-the-box.
Within Azure, implementing Application Insights and Log Analytics is a great way to handle telemetry as well as custom details.
|
| 17 | Are exceptions handled and if so, is the output meaningful? Furthermore, does the code then exit gracefully once the exception stops any further processing.
Exceptions in code can take many forms, sometimes expected, sometimes very much unexcepted. This also alludes to a defensive mindset; can we predict where an error in the code will occur? |
For any exception its important to attempt to wrap code in a TRY – CATCH condition, maybe with a FINALLY code block as well if appropriate and depending on the language.
In the CATCH block I like custom, informative details to be thrown along with any system generated message.
|
| 18 | If/when an error occurs in the code and an exception is raised, does the data transformation leave the source or target dataset in a transaction safe state with data integrity preserved? | As a crude example, imagine a row by row process that errored on row 7 out of 10, when the code or process restarts should it continue from where it left off and how will it know?
Maybe, its simpler to handle things in the context of the entire batch and just overwrite anything done previously to avoid data integrity issues.
|
| 19 | Is authentication handled correctly for the solution with as many layers of protection as is reasonably possible in place?
If so, does the code created expose any weaknesses that short circuit the layers of security? |
For an Azure Data Platform solution, simple things like using Managed Service Identities and having Azure Key Vault in place as a central credential store is important to setup.
|
| 20 | Does the code under review require an element of testing or re-testing that wasn’t originally planned for?
This is not functional testing done by the code author, this is system testing undertaken by a dedicated test team. |
As a developer (in my opinion) we often forget about testing our work, either end to end, or when reconciling all the steps of a data transformation process.
Furthermore, in some cases, code may be updated/upgraded which changes the approach of the solution. The output might be the same but the testing effort now required due to additional complexity far exceeds what was originally intended. Consider codes changes vs testing impact. |




I promised myself I would stop at 20 check points. There is of course much more that could be done, especially if we wanted to focus on a particular technology. For now, this is the end of my peer review script.
Long term I want this standard of checking to help us all improve the code we deliver. To assist I’ve distilled the check points into a table of only questions to take away…

I hope you found this post useful, it is primarily based on my own experiences as an ex-developer come solution lead.
Further Reading
For more details I found the following sites helpful when first doing peer reviews for others:
5 Elements of a Perfect Pull Request by Atlassian
https://www.atlassian.com/blog/bitbucket/5-pull-request-must-haves
Best Practices for Code Review by Smart Bear
https://smartbear.com/learn/code-review/best-practices-for-peer-code-review/
Many thanks for reading.

One thought on “My Script for Peer Reviewing Code”