Switching Between Different Azure Databricks Clusters Depending on the Environment (Dev/Test/Prod)
 As far as I can gather at some point last year, probably around the time of Microsoft Ignite Azure Data Factory (ADF) got another new Activity called Switch. This is excellent and exactly what ADF needed. Nested If activities can get very messy so having this value vs case behaviour at the control flow is really nice.
As far as I can gather at some point last year, probably around the time of Microsoft Ignite Azure Data Factory (ADF) got another new Activity called Switch. This is excellent and exactly what ADF needed. Nested If activities can get very messy so having this value vs case behaviour at the control flow is really nice.
If you aren’t familiar with the switch concept Data Factory works in exactly the same way as the C# Switch and probably many other languages. Summarised below:
- Receive a value/parameter/variable.
- Review a list of possible outcomes.
- Exit to the outcome that matches the value/parameter/variable passed.
This approach is often considered to be more efficient for larger sets of conditions than a block of If, Else If, Else If, Else type logic tests.
To continue the C# comparison I expect if we pealed back the pretty ADF UI we would see something constructed very similar to the below (with less Console line calls and some actual work being done).

Background on the concept done. Let’s look at the exact ADF implementation of Switch and think about how we could apply it to help our solution orchestration. I’ve added the Microsoft document link below if you want more of a baseline.
https://docs.microsoft.com/en-us/azure/data-factory/control-flow-switch-activity
Scenario
We have a data platform solution containing a development, test and production environment. In each environment its likely that the amount of compute we want to use will vary. For example, in development we use a small Databricks cluster with only a few worker nodes. Whereas in production (with complete big datasets) we might use a large highly concurrent cluster with many workers.
Normally good deployment practices would mean we can easily separate those environment work loads with different Data Factory’s etc. But what if we only had a single Data Factory? To demonstrate the Switch activity I’m going to assume exactly that. Feel free to toll me in the comments if you think my scenario isn’t realistic enough for you 🙂
Solution
Using a Data Factory pipeline parameter to determine the current running environment we could use a Switch activity to drive which Databricks cluster we hit. For each Case in the Switch we have a Databricks Notebook activity, but depending on the condition passed this uses a different Databricks linked service connection. Each Databricks linked service from Data Factory has a different job cluster configured for each environments requirements. Visually this might look something like the below.

For the actual Data Factory pipeline and components, firstly we need our Linked Services. Shown below. Nothing exciting, just three predefined connections to Databricks, each setup with a job cluster and with different compute tiers and scaling capabilities. As you’ll also see in the JSON I’m using Azure Key Vault to handle credentials, as we should all be doing 😉
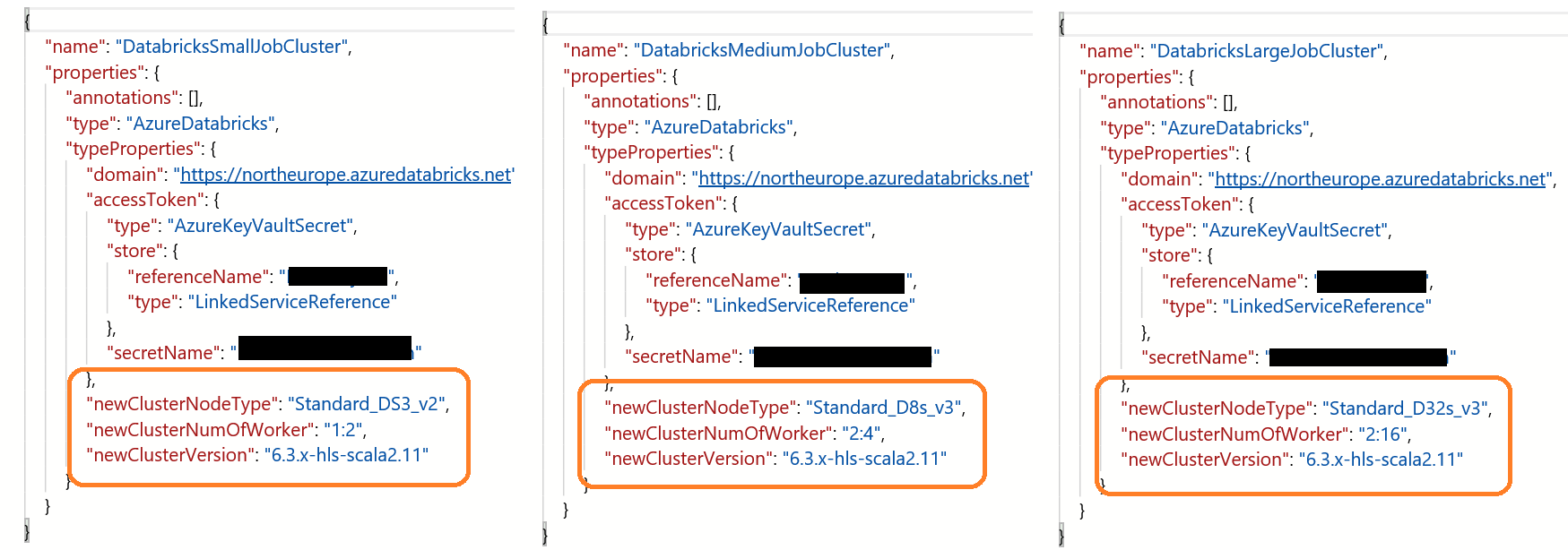
Next, the pipeline itself. The Case activity is very simple to use and accepts all the usual expression builder content to handle the value passed. This doesn’t have to be a pipeline parameter. It could be the output of a Lookup activity, or whatever. Once established we then need to set the static values for each Case output. While initially playing around with this activity I did encounter a bug if you removed Cases and re-added them so be careful. Also make sure your data types are correct with the value passed compared to the Case. Don’t assume an implicit conversion.
 |
 |
Lastly, for my default case I added a Wait activity for 1 second. This isn’t perfect, I just did it as an example. This could be an alert or maybe something to show that the value passed to didn’t match any of the case outputs. My advise is to have a think about this as you don’t just want the pipeline to report a success when the value resolved to the default case. This could in fact indicate a failure of something else.
That’s it. There isn’t really much more to say about the Case activity. It does exactly what you’d expect it to do. I hope my scenario gave you a flavour of its usage. There are of course many other applications for it.
Many thanks for reading.

Hi Paul! I greatly appreciate all of your ADF Blogs. I have a question; I am trying to put a switch activity inside a ForEach Activity. All it shows is Default; does a Switch not work inside a ForEach?
Thanks
Mike Kiser
LikeLike
Hi Mike, yes, Switch does work inside a ForEach. I’ve implemented this pattern in my procfwk.com parent pipeline if you’d like to see an example here: https://github.com/mrpaulandrew/procfwk/blob/master/DataFactory/pipeline/02-Parent.json
Thanks Paul
LikeLike
Hi Paul, great information, thanks..!! Inside a switch activity could build a large or complex pipeline? or are there limitations?
Thanks
David
LikeLike
Best just to use the Execute pipeline activity and have a secondary pipeline do the heavy lifting, but bootstrapped by the Switch.
LikeLike
Hi Paul, great information, thanks..!! Inside a switch activity could I build a large or complex pipeline? or are there limitations?
LikeLike
The main limitation I hit is 40 activities per pipeline. Which is why I created procfwk.com
LikeLike