Exciting times friends, today (25th March) the lovely people at Microsoft granted me access to the private preview MVP workspace for Azure Synapse Analytics 😀

In this quick blog I wanted to share my experience so far, which I’m basically writing as I’m playing around…

https://azure.microsoft.com/en-gb/services/synapse-analytics/
The main reason I wanted access to Synapse is to play around with Spark.Net via the Synapse workspace Notebooks. Currently if deploying Synapse via the public Azure portal you only get the option to create a SQL compute pool, formally known as an Azure SQLDW. While this is good, it gives us none of the exciting things that we were shown about Synapse back in November last year during the Microsoft Ignite conference.
To get the good stuff in Azure Synapse Analytics you need access to the full developer UI and Synapse Workspace. The complete workspace currently gives you the following menu options:
- Home
- Data
- Develop
- Orchestrate
- Monitor
- Manage
Other the Manage panel is the ability to create both SQL compute pools and Apache Spark compute pools.
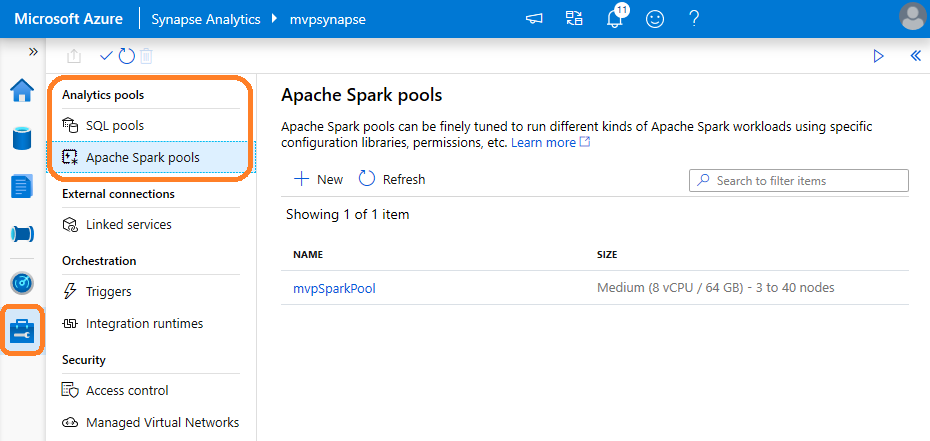
That said, and for completeness, you can write and run Spark.Net locally via Visual Studio (getting started link below) but this development experience is no where near as nice as using Notebooks in Synapse.
The Microsoft.Spark NuGet package makes things easy when developing, but to run your code you’ll still need to install a local intance of Spark and submit the Spark App via a command line. As I say, not as nice as using Notebooks in Synapse. Anyway, I digress. Maybe we can talk about the local developer experience in another blog.

Back to Synapse…
From the Data panel in Synapse we get access to:
- Storage Accounts
- Databases
- Datasets

 To start simple, I used the built in Storage Explorer screens to create a new Container (PaulsPlayground) and uploaded some sample data from the Spark.Net tutorial (input.txt).
To start simple, I used the built in Storage Explorer screens to create a new Container (PaulsPlayground) and uploaded some sample data from the Spark.Net tutorial (input.txt).
Once done, a really nice feature is being able to create a ‘New Notebook’ directly from a selected file. Screen snippet on the right. The result of this is a Notebook created which include a single cell of PySpark, this references the text file (in this case) and gives you a data frame to read and show data from first 100 rows.
I did this for a few different file types which just changes the format parameter in the Read.Load method, as you’d expect. For a CSV file the generated code also provides options to set the header parameter as well. Some of you may remember Data Lake Analytics had the same feature writing U-SQL for files in Data Lake Store Gen1, thanks Mike 🙂

As I didn’t want to use PySpark I simply went directly to the Develop panel and created a new Notebook manually. I attached it to an existing Spark compute pool and set the Language (kernel) to .NET Spark (C#).
Then it was simply a case of writing a query or two. I reused a lot of the code from the tutorial linked above. The point was really to play around in the Synapse workspace, not to write a complex Spark.Net query. Plenty of time for that in later blogs.
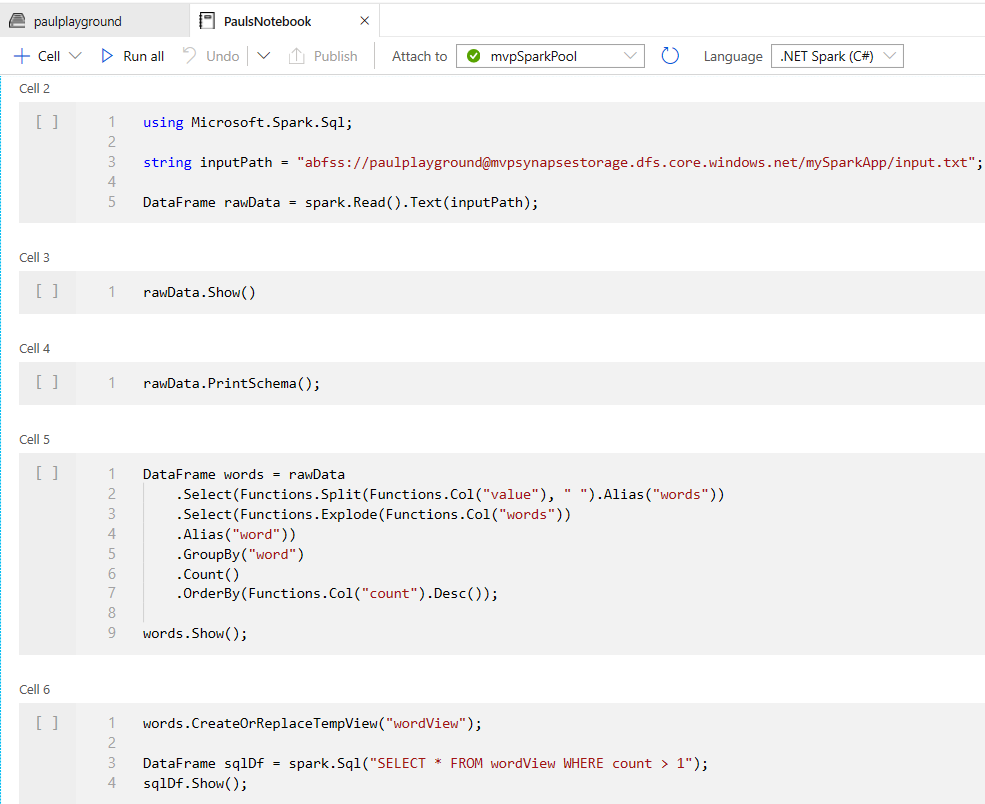
Here is a full export of my Notebook file…
https://github.com/mrpaulandrew/BlogSupportingContent
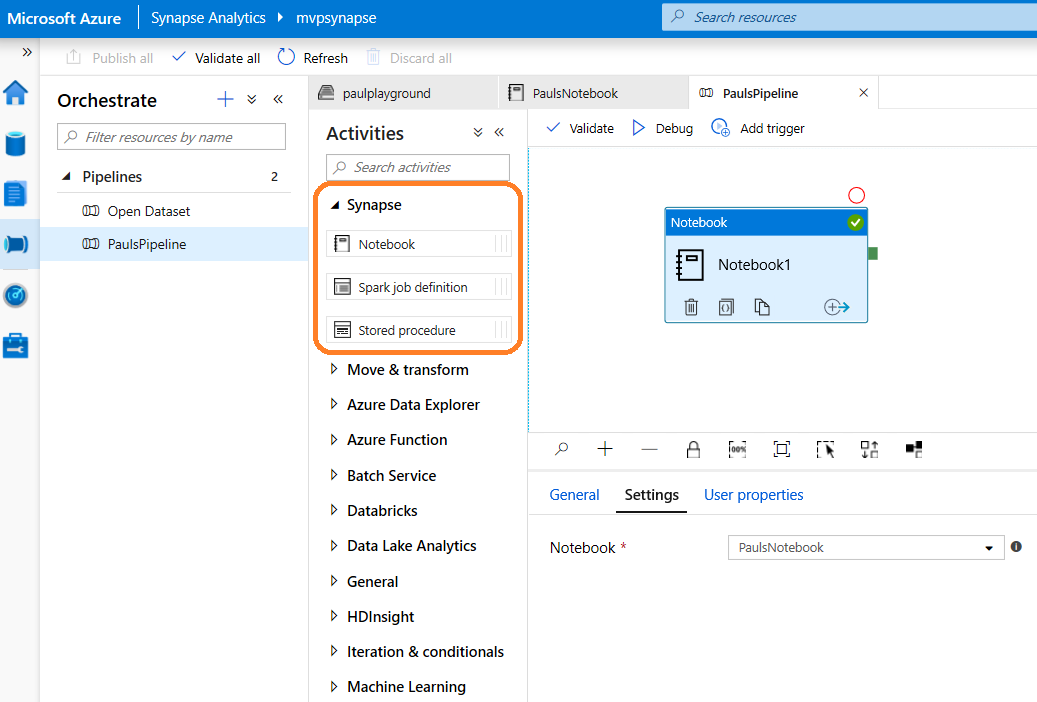
Finally, I went to the Orchestrate panel and ran the Notebook in a pipeline using the new Synapse Notebook activity. This is all very familiar if you’ve ever used Azure Data Factory. Although zero Linked Service connections needed as its all integrated into the single Synapse workspace.
Conclusion
To conclude my first round of playing with Azure Synapse Analytics, its exceeded expectations for features promised and ease of use. Also the preview environment I’m using in the West US 2 region seems to be very stable. The only thing really missing on the surface is the ability to integrate with source control so we can complete the DevOps story for Synapse.
More blogs coming as I explore other areas of this all-in-one data engineering/analytics/science platform.
Many thanks for reading.

awesome work .. love your blogs around Azure Big Data space and looking forward to more exciting work in the coming future
LikeLike
Thanks 😊
LikeLike
Good work! but i have problem when execute “DataFrame sqlDf = spark.Sql(“SELECT * FROM wordView WHERE count > 1″);
sqlDf.Show();”
Error:
“org.apache.spark.sql.AnalysisException: The root scratch dir: /tmp/hive on HDFS should be writable.”
Why?
LikeLike