Code Project Overview
![]() This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is delivered by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist for a given stage.
This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is delivered by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist for a given stage.
The framework is designed to integrate with any existing Data Factory solution by making the lowest level executor a stand alone processing pipeline that is wrapped in a higher level of controlled (sequential) dependencies. This level of abstraction means operationally nothing about the monitoring of orchestration processes is hidden in multiple levels of dynamic activity calls. Instead, everything from the processing pipeline doing the work can be inspected using out-of-the-box ADF features.
This framework can also be used in any Azure Tenant and allow the creation of complex control flows across multiple Data Factory resources by connecting Service Principal details to targeted Subscriptions > Resource Groups > Data Factory’s and Pipelines, this offers very granular administration over data processing components in a given environment.
Thank you for visiting, details of this latest release can be found below.
ADF.procfwk content and resources:
| Blogs | mrpaulandrew.com/ADF.procfwk | |
| GitHub | github.com/mrpaulandrew/ADF.procfwk | |
 |
#ADFprocfwk |
Version 1.3 of ADF.procfwk is ready!
Release Overview
With this release of the framework I wanted to take the opportunity to harden the database and add some more integrity (intelligence) to the metadata, things that go beyond the existing database PK/FK constraints. After all, this metadata drives everything that Azure Data Factory does/is about to do – so it needs to be correct. These new integrity checks take two main forms:
- Establishing a minimum set of criteria within the metadata before the core Data Factory processing starts and creates an execution run.
- Establishing a logical chain of pipeline dependencies across processing stages. Then providing a set of advisory checks for area’s of conflict and/or improvement.
More details on both are included against the actual stored procedure in the database changes section below.
In addition to database hardening, I’ve added a few other bits to the solution, including a PowerShell script for ADF deployments and a Data Studio Notebook to make the developer experience of implementing this code project a little nicer.
Bug Fixes
A did encounter a minor bug while using the framework which I feel compelled to call out. This relates to the Service Principal handling for specific Data Factory pipelines. The scenario where this applied; if you wanted to delete the link between an SPN and specific Data Factory pipeline, then re-add the pipeline using an existing (different) SPN the stored procedure [procfwk].[AddServicePrincipal] didn’t handle this situation and reported an error that the SPN already existed.
I’m fairly sure this scenario is an outlier, but those are often the worst kind of bugs! This has now been fixed 🙂
Database Changes
Tables
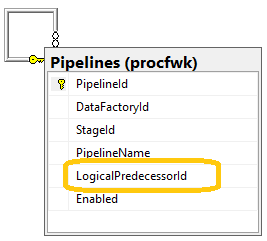 The main database table change for this release of the framework is for the (renamed)
The main database table change for this release of the framework is for the (renamed) [Pipelines] table. A new attribute called [LogicalPredecessor] has been added, this attribute can be NULL, but for values added the table now has a FK constraint to itself for the [PipelineId]. Meaning the logical predecessor ID must be an existing pipelines in the table. Also, as the relationship implies, one pipeline Id can be referenced as the logical predecessor for multiple downstream pipelines. The behaviour becomes clearer when used in conjunction with the stored procedure[procfwk].[CheckStageAndPiplineIntegrity]detailed below.
The other key change to tables in this release relates to a clean up on naming conventions. This includes 3 tables renames as follows:
[procfwk].[DataFactoryDetails]>[procfwk].[DataFactorys][procfwk].[ProcessingStageDetails]>[procfwk].[Stages][procfwk].[PipelineProcesses]>[procfwk].[Pipelines]
In all cases I’ve updated the related stored procedure code as part of the release. Then to ensure backwards compatibility I’ve added simple (pass through) Synonyms just incase anyone has written any custom views over the metadata.

Warning; the database project pre-deployment script will drop the legacy tables and backup the tables into [dbo].[zz_{LegacyTableName}]. This applies if you have existing metadata in place from a previous release of the processing framework. You’ll then need to repopulate the new table names with your metadata.
 Finally, the execution tables now support a new attribute to capture the Data Factory name that called the processing pipelines. Seen on the right. This applies if the framework is not running in the same Data Factory as the processing pipelines.
Finally, the execution tables now support a new attribute to capture the Data Factory name that called the processing pipelines. Seen on the right. This applies if the framework is not running in the same Data Factory as the processing pipelines.
Stored Procedures
[procfwk].[CheckMetadataIntegrity]– This procedure now acts as a pass/fail check before a given framework exeuction runs starts. If any of the checks fail the Data Factory pipelines will not start and the execution run will be stalled.In debug mode details of the checks that failed can be reviewed and fixed.[procfwk].[CheckStageAndPiplineIntegrity]– This procedure uses the new optional attribute[LogicalPredecessorId]within the table[procfwk].[Pipelines]to create a chain of dependencies between processes. This chain has no affect of the execution of the framework, but does allow data lineage paths to be reviewed and created without impacting processing. The procedure also implements a series of case statement checks against pipeline chains to advise where metadata issues may exist. For example:- Pipeline could be moved to an earlier stage if it has no predecessors and/or isn’t in the first stage.
- Dependency issue, predeccessor pipeline is currently running in the same stage as successor.
- Disabled pipeline has downstream successors.
- Disabled stage has downstream successors.
It is recommended that these advisory points and checks from both new integrity procedures are reviewed and the logical chain of pipelines updated to inform better framework execution before running the framework. The intelligence of this checks is of course only as good as the intelligence of us updating the metadata values.
Data Factory Changes
The only change to Data Factory during this release is the addition of 1 new activity at the beginning of the parent pipeline; Metadata Integrity Checks. This calls the stored procedure detailed above and must complete successfully before anything else can happen.
Click to enlarge.

Other Changes
As part of the wider processing framework hardening I’ve added a few miscellaneous things to this release to improve the implementation/developer experience as mentioned in the overview above. I’ve broken these down into sub headings to provide more details and allude to my thought process for each enhancement. As follows:
Azure Data Studio Notebook
![]() If you haven’t yet worked with Azure Data Studio please give it a try, personally I’m a little ‘old skool’ and still prefer SQL Server Management Studio. However, with the fairly recent introduction of Jupyter Notebooks into Data Studio this does make the cross platform tool a lot more appealing and nicer for adding narrative to code via Markdown. Furthermore, the cell by cell execution means script context can deviate from the normal long procedural set of code that you might find in a typical SQL file.
If you haven’t yet worked with Azure Data Studio please give it a try, personally I’m a little ‘old skool’ and still prefer SQL Server Management Studio. However, with the fairly recent introduction of Jupyter Notebooks into Data Studio this does make the cross platform tool a lot more appealing and nicer for adding narrative to code via Markdown. Furthermore, the cell by cell execution means script context can deviate from the normal long procedural set of code that you might find in a typical SQL file.
With this in mind, I’ve had a play around with Azure Data Studio Notebooks and created a user friendly set of scripts for working with the framework metadata. In the Notebook narrative accompanies these code snippets to explain how to interact with the framework metadata. Initially I’ve added content to the Notebook for:
- Getting Current & Previous Execution Details
- Reviewing Basic Processing Metadata
- Reviewing and Checking Logical Pipeline Metadata Integrity
- Checking and Adding Framework Properties
- Checking, Getting, Adding and Deleting Service Principals
- Reviewing the Pre-Execution Metadata Integrity Checks
Please let me know if you’d like anything more.
PowerShell
Following the installation of PowerShell 7 on my laptop I decided to break out the Az cmdlets and create a method for deploying the framework Data Factory to your preferred Azure tenant/subscription. This new PowerShell script (included in the solution Deployment Tools project) is now available for deploying the ADF.procfwk Data Factory components, which means only the linked services/datasets/pipelines specific to the framework get deployed rather than using the ARM template import approach.
Generally this technique of deploying Data Factory parts is much nicer and more controlled than using the ARM Templates. However, is does mean you have to manually handle component dependencies and removals, if you have any. A visual of the approach:
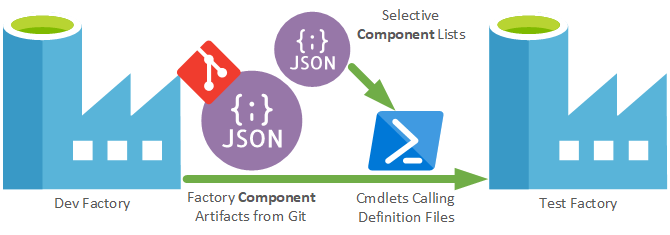
The PowerShell uses the artifacts created by Data Factory in the GitHub repository (not the adf_publish branch). Then for each component provides this via a config list as a definition file to the respective PowerShell cmdlets. This uses the DefinitionFile parameter to hit the respective JSON files from the GitHub repository that were created by the Data Factory dev instance.
Sudo PowerShell and JSON example below building on the visual representation above, complete code also in GitHub.

Finally, to accompany this PowerShell deployment approach for Data Factory, a new Markdown file has also been added to offer a set of steps to deploy the whole metadata driven framework project for all resources. Check this out under the ‘DeploymentTools’ project in the Solution.
Visual Studio Solution & VSCode Explorer
 Lastly, for this release and probably slightly more boring than the technical stuff above; I’ve tidied up the Visual Studio Solution and added new logical folders for all the files within the repository. Visual Studio projects are great, but I also like to have visibility to the other artifacts created in the code project. After all, a Visual Studio Solution often isn’t the complete solution, lots of other files are needed to deliver something. Eg. Visio design documents.
Lastly, for this release and probably slightly more boring than the technical stuff above; I’ve tidied up the Visual Studio Solution and added new logical folders for all the files within the repository. Visual Studio projects are great, but I also like to have visibility to the other artifacts created in the code project. After all, a Visual Studio Solution often isn’t the complete solution, lots of other files are needed to deliver something. Eg. Visio design documents.
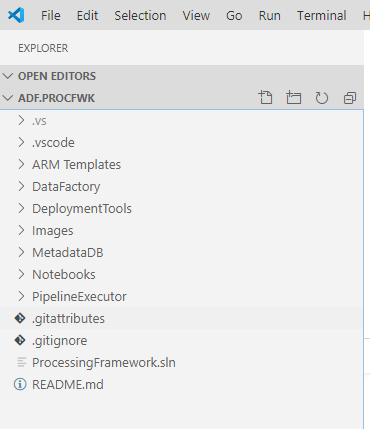 If you aren’t a fan of Visual Studio and prefer VSCode that’s also fine. Via the Explorer panel in VSCode the supporting JSON files have also been added meaning the UI knows what to do when you open the directory.
If you aren’t a fan of Visual Studio and prefer VSCode that’s also fine. Via the Explorer panel in VSCode the supporting JSON files have also been added meaning the UI knows what to do when you open the directory.
That said, I haven’t yet worked out locally debugging the Azure Function App via VSCode and the C# extension only gets you so far.
That concludes the release notes for this version of ADF.procfwk.
Please reach out if you have any questions or want help updating your implementation from the previous release.
Many thanks

One thought on “ADF.procfwk v1.3 – Metadata Integrity Checks”