Code Project Overview
![]() This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is delivered by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist for a given stage.
This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is delivered by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist for a given stage.
The framework is designed to integrate with any existing Data Factory solution by making the lowest level executor a stand alone processing pipeline that is wrapped in a higher level of controlled (sequential) dependencies. This level of abstraction means operationally nothing about the monitoring of orchestration processes is hidden in multiple levels of dynamic activity calls. Instead, everything from the processing pipeline doing the work can be inspected using out-of-the-box ADF features.
This framework can also be used in any Azure Tenant and allow the creation of complex control flows across multiple Data Factory resources by connecting Service Principal details to targeted Subscriptions > Resource Groups > Data Factory’s and Pipelines, this offers very granular administration over data processing components in a given environment.
Thank you for visiting, details of this latest release can be found below.
ADF.procfwk content and resources:
| Blogs | mrpaulandrew.com/ADF.procfwk | |
| GitHub | github.com/mrpaulandrew/ADF.procfwk | |
 |
#ADFprocfwk |
Version 1.2 of ADF.procfwk is ready!
Release Overview
 For this release of the framework the primary goal was to deliver execution restart-ability. To do this we firstly had to decide if we wanted Data Factory to naturally handle pipeline/activity failures and raise errors via its Success/Fail/Complete/Skip execution chains. Or, did we want to control the failure handling using the framework metadata. In order to achieve a simple way of managing restarts and surfacing errors in a graceful way I opted for the latter. Why? Well, I didn’t consider it to be in the remit of the processing framework to surface specific error details when a failure has occurred, this can be done via the ADF monitoring portal in the normal way for a particular activity, instead the framework just needs to stop processing in a controlled way that leaves the metadata in known state.
For this release of the framework the primary goal was to deliver execution restart-ability. To do this we firstly had to decide if we wanted Data Factory to naturally handle pipeline/activity failures and raise errors via its Success/Fail/Complete/Skip execution chains. Or, did we want to control the failure handling using the framework metadata. In order to achieve a simple way of managing restarts and surfacing errors in a graceful way I opted for the latter. Why? Well, I didn’t consider it to be in the remit of the processing framework to surface specific error details when a failure has occurred, this can be done via the ADF monitoring portal in the normal way for a particular activity, instead the framework just needs to stop processing in a controlled way that leaves the metadata in known state.
To further clarify my stance here with an example, if a Databricks Notebook fails the Data Factory activity provides details of the error and bubbles up a link to the exact Notebook and code cell that errored via the Databricks workspace. You can’t get much better than that when troubleshooting. I therefore don’t want the framework to replicate the handling of exception information, just to acknowledge that a failure has occurred for a particular pipeline. Once done, operationally we can investigate the failure via methods far better tailored to the processing pipeline that was called.
We only care what has failed, not why it failed. The ‘why’ can be found in the pipeline code not written for the framework, only called by it.
Next, I considered it important to define some execution scenarios that could warrant the framework needing to be restarted. As follows:
Execution Scenarios
- The processing pipeline called by the framework failed and reports a failure state to the Azure Function.
- The framework parent or child pipelines are cancelled from the Azure Data Factory monitoring portal.
- The Azure Function fails to run for reasons outside of the processing framework. Maybe due to an authentication issue or some other wider Azure resource problem.
- Azure Data Factory fails to run for reasons outside of the processing framework. Maybe the Azure IR compute encounters an unexpected error for a given Azure region.
For the first 3 scenarios I think its reasonable to expect the framework to be able to recover. Furthermore, scenario 1 this is the mostly likely outcome that must to be handled.
Failure Handling
Based on the above the key thing to be aware of is that the Azure Function calling our low level processing pipelines will always return a status (from the HTTP Trigger/Request) ofOkObjectResult, rather than a bad request or some other exception thrown via C#. Snippet from the Azure Function below.

What is also key is that the output from the Function provides the pipelineRun.Status for the given Run Id. This is now critical for the framework as this status will drive what happens next in terms of reporting, handling the failure and stopping downstream execution stages.
Processing Lifecycle
Given this failure handling behaviour our pipeline status values can therefore be set during a current execution using the following logic:
- If an error occurs in a processing pipeline it will be given statues of ‘Failed’. As reported from the Azure Function.
- All processing pipelines in execution stages downstream of the error will be given a status of ‘Blocked’.
- All processing pipelines in execution stages upstream and in the current stage that completed successfully will keep the status of ‘Success’.
- Pipelines stopped by Azure Data Factory as part of some manual intervention that were ‘Running’, will be logged as ‘Cancelled’.
Next, once the error has been fixed by the operations team the processing framework parent pipeline can be called again without any changes needed in the metadata. Restarting processing after a failure will be the frameworks default behaviour. However, this can be overridden, see new database properties below.
Finally, upon restart:
- All pipelines with a statues of ‘Failed’ will be reset to NULL.
- All downstream pipelines with a status of ‘Blocked’ will be reset to NULL and the ‘IsBlocked’ flag removed.
At this point the failed pipeline will become the new started point for the current execution and allow the framework to continue from where the error occurred. Pipelines that completed successfully within the same execution stage as the failure will not be reran as there should not be inter dependencies in an execution stage.
To visualise these steps below is a set of snapshots from the [CurrentExecution] table during a failure and restart.
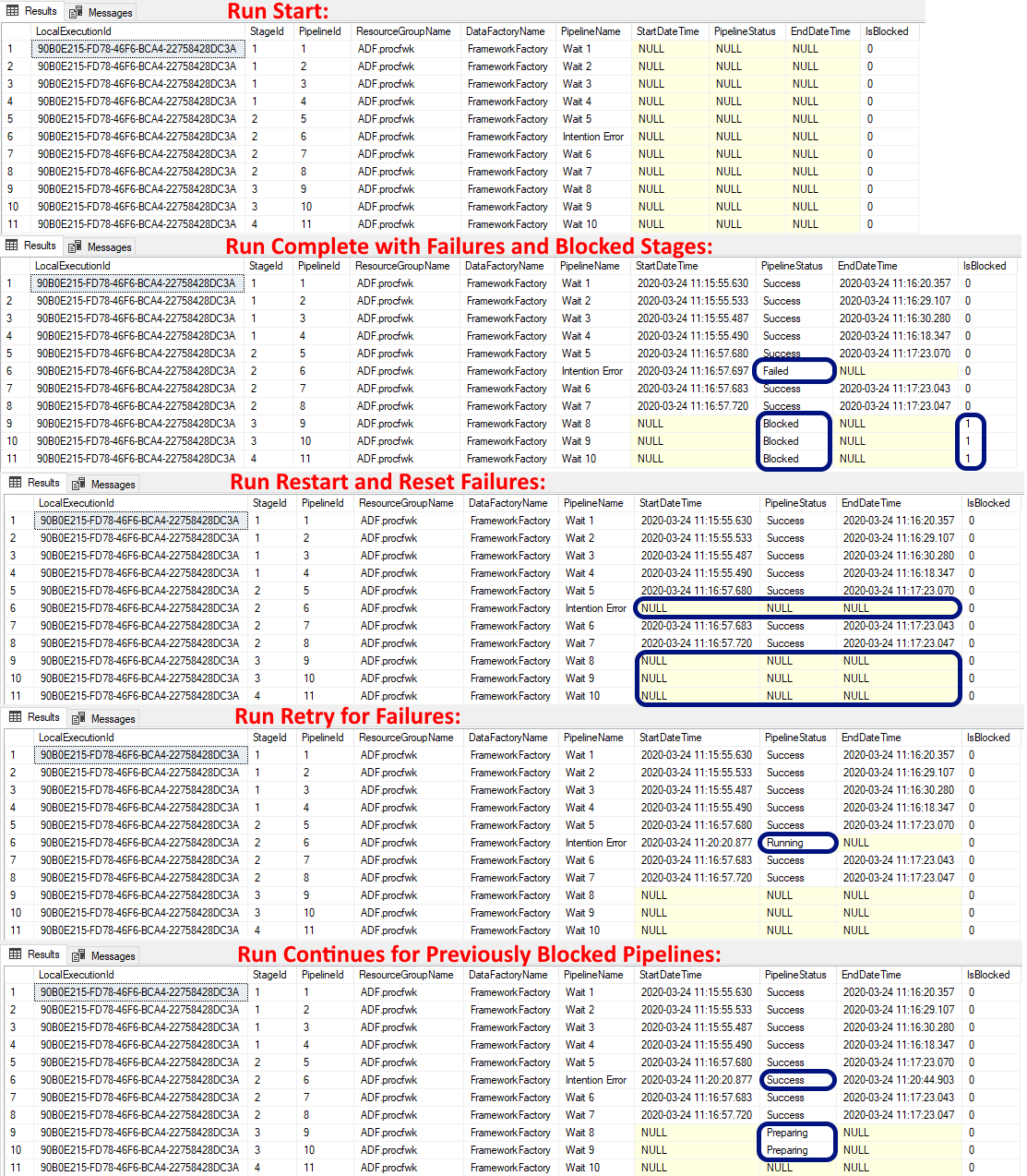
Also be aware that failed pipeline details will be persisted to the long term execution log table and the same execution GUID maintained until a complete new execution state is created.
Bug Fixes
Not strictly a bug, but worth calling out is a minor oversight in previous versions of the processing framework. As stated above the Azure Function will always returns an Ok result, which means the Function activity in the Data Factory child pipeline will always complete successfully. Because of this, the red failure path in the activity chain will never be called. The processing pipeline that was called may have failed, however, the Function reported an Ok result from the HTTP Request so the activity was successful. Definitely a false positive problem. The only reason for the failure path in the previous version of the framework is if the Azure Function being called failed for another reason outside of Data Factory.

Happily, this has now been addressed in v1.2, please continue reading.
Database Changes
Tables
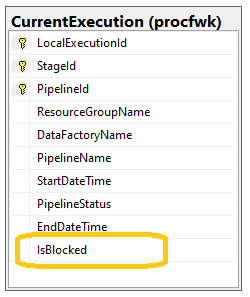 In order to achieve framework restarts only 1 additional attribute was required in
In order to achieve framework restarts only 1 additional attribute was required in [CurrentExecution] table, called ‘IsBlocked’. This is a BIT field with a default value of 0 or false. All other database tables remain the same.
In addition, to help processing performance when setting the status of pipelines a none clustered index has been added to the [CurrentExecution] table. For large orchestration solutions with many thousands of rows of metadata this should reduce contention on the table during an execution run. The index will also be rebuilt for each new execution run.
Properties
Alongside our existing Tenant and Subscription framework properties a new entry has been created called ‘OverideRestart’. It’s expected values are 1 or 0, these have the following meanings for the framework processing:
- OverideRestart = 0 – In the event of a failure, restart processing and reset the status of pipelines that errored in the
[CurrentExecution]table. This will be the default behaviour. - OverideRestart = 1 – Even if a failure occurred during the last execution, do not attempt to restart processing. Clear down the
[CurrentExecution]table and simply start again with a fresh set of stage and processes metadata.
Given these definitions I’m hoping the property name becomes a little more self explanatory given the context.
Data Factory Changes
The parent and child pipeline activities have now evolved into the following for version 1.2:
Click to enlarge.
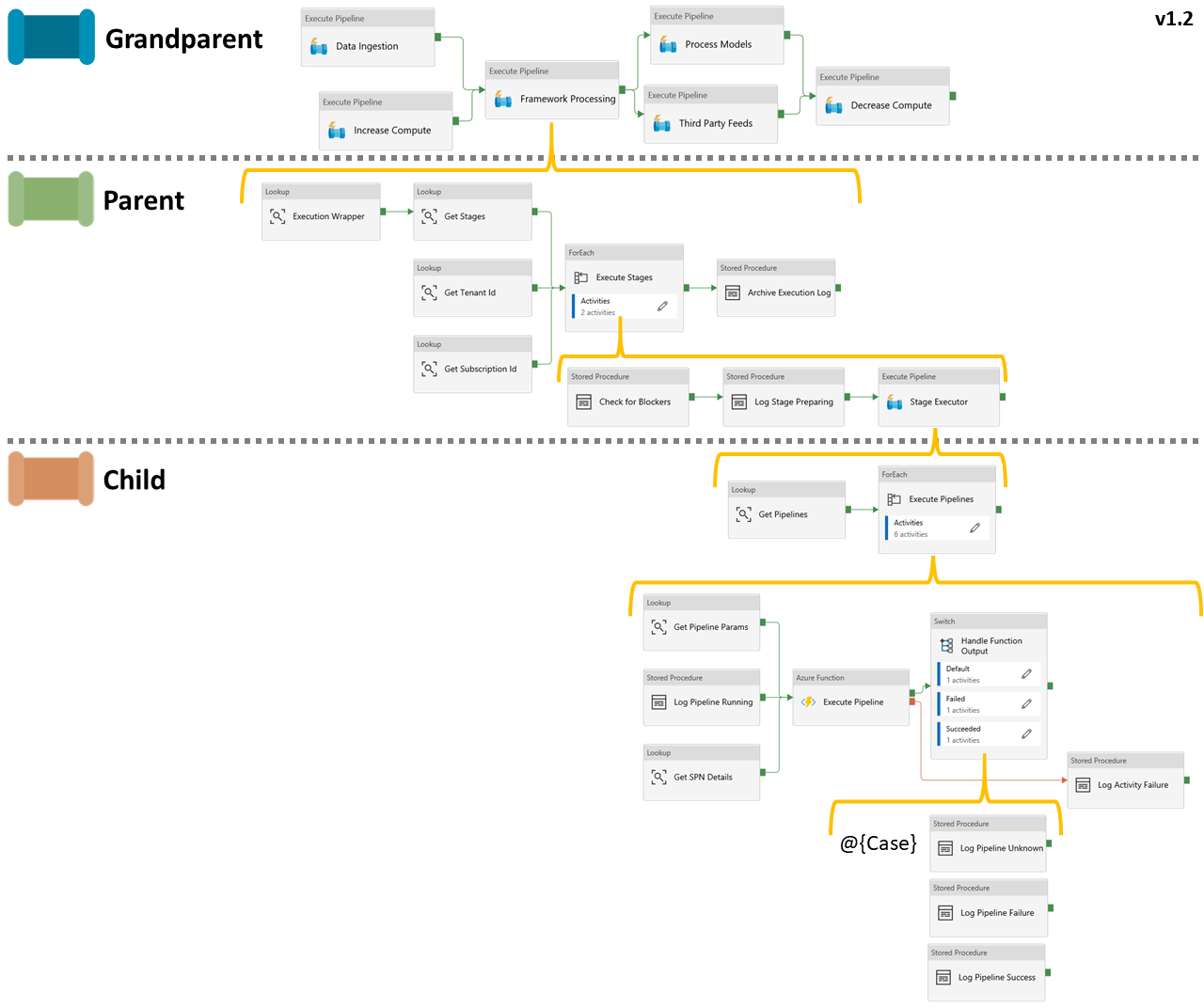
If your not a fan of looking at this as an image, please check out the PowerPoint file in the GitHub repository. Here each slides is a version of the framework that can be compared as the activities have changed.
To offer some narrative on these activity updates in the context of the new restart capability:
- Execution Wrapper – This replaces the previous ‘Create New Execution’ stored procedure activity with the new wrapper version that establishes if a restart is required or if a new execution can be created. This is done by inspecting the content of the
[CurrentExecution]and considering the ‘OverideRestart’ property.- IF the
[CurrentExecution]table isn’t empty and contains pipelines that don’t have a ‘Success’ status, plus the override restart property is false.- THEN execute
[procfwk].[ResetExecution]
- THEN execute
- ELSE IF the execution table isn’t empty, but the override restart property is true.
- THEN execute
[procfwk].[UpdateExecutionLog]AND execute[procfwk].[CreateNewExecution]
- THEN execute
- ELSE this must be a completely new execution run.
- THEN execute
[procfwk].[CreateNewExecution]
- THEN execute
- IF the
- Check for Blockers – With the sequential ForEach activity in the parent pipeline we can’t avoid this finishing its iterations over all execution stages in our metadata. The best we can do is avoid other activities being fired unnecessarily when we are going to need to restart. Therefore, this stored procedure activity checks if we have blockers due to upstream failures as soon as soon for the next iteration stage and reports an error. Sadly this will need to fire for all blocked staged.
- Log Stage Preparing – This replaces the previous ‘Log Stage Started’ status and activity with a better status value called ‘Preparing’ for a given point in the execution stages. Previously the ‘Started’ status was set as a batch along with a date/time for all pipelines in a stage. Now only ‘Preparing’ is set as a batch at the stage level. Then the start date/time update applied when the pipeline is set to ‘Running’ at the pipeline level.
- Handle Function Output (Switch) – This switch uses the output from the Function activity to drive case conditions using the pipeline run status returned. The switch also replaces the old success execution path with better handling for the restart. Case outcomes:
- Log Procedure Unknown – provides default handling in the Switch activity if the Function activity returns an unknown condition.
- Log Procedure Failure – calls the stored procedure to update the
[CurrentExecution]table with Failed and Blocked pipeline status values. - Log Procedure Success – calls the stored procedure to update the
[CurrentExecution]table with Success pipeline status values.
- Log Activity Failure – This replaces the previous failure path mentioned in the bug fix section above with a more accurate activity failure stored procedure. The procedure feeds back into the framework metadata allowing a restart to occur even if the function failed.
Other Changes
In addition to all this great stuff done above a few side things for this release as follows:
- All Data Factory components (Pipelines/Activities/Datasets/Linked Services) related to the processing framework now have the Annotation of ADF.procfwk to help you separate them within large solutions.
- All Data Factory Pipelines and Activities now have one liner descriptions added to help with understanding when clicking around the ADF developer interface.
- The pipeline log start date/time is now set by the framework child pipeline at the actual point of starting per pipeline, rather than by the parent pipeline and set for all pipelines in a stage.
- The store procedure
[GetProcessStages]has been renamed to[GetStages]just to make terminology simpler. - A stored procedure called
[dbo].[FailProcedure]has been added to the development environment with a pipeline called ‘Intention Error’. This is purely to test the restart capabilities when an error occurs. I’ll keep this procedure in place to support functional testing of the framework before each release. - There is now a fourth stage in the development metadata using to test the blocking of multiple downstream execution stages when an error and restart is required.
That concludes the release notes for this version of ADF.procfwk. Sorry if it was a bit of a heavy one…. Restart and failure logic is never simple to engineer.
Please reach out if you have any questions or want help updating your implementation from the previous release.
Many thanks

One thought on “ADF.procfwk v1.2 – Execution Restartability”