Defining What Isn’t a Data Product – Data Pretenders rather than data products
Background
In part 8 of this blog series I explored the definition of a data mesh data product. Following several comments and feedback it now seems like a good idea to also address what is not a data product. As the saying goes, playing devil’s advocate with our data mesh – data product understanding.
The reasons for calling out what should not be declared as a data product can take many different forms and in some cases even result in anti-patterns that should be addressed as technical debt etc. Governanace and compliance has always been a key part of successful platform delivers, but who/how do we go about policing this both technically and in the context of people/process? Maybe ‘Data Product Police’ could be a thing! 🙂
With the data mesh principals its already hard enough knowing what to do, in what order and how, without needing to address an unhealthy dose of what not to do as well. Below is my current thinking to help breakdown and challenge those that wish to dismiss the data mesh purity and simply go around declaring all existing data platform solutions as a data product, without thought, to gain traction amoungst the hype.
So, where could this go wrong and what should we check for when reviewing ‘so called’ data products? I’m going to start with a simple check list, building on the thinking of this blog series. Some of this might be obvious, some not so much and certainly not an exhaustive list at this point.
Going forward I’m going to refer to these “things” as a data pretenders rather than data products.
I was tempted to go with data proclaimers, but that just resulted in the song – I Would Walk 500 Miles playing in my head on repeat! YouTube link added if helpful! 🙂
Shut up Paul, move on!
Data Pretender Checks
- Does the data pretender contain source data from a system ingested directly, from outside of its aligned data domain?
- Similar to point 1, but as a catch all, does the data pretender contain duplicated datasets already available within the data mesh?
- Has the data pretender implemented a consistent set of primary, secondary and tertiary interfaces mandated by the data mesh architecture. These standards could be subjective based on the technical requirements of the wider mesh, meaning consistency becomes key.
- Does the data pretender offer datasets that are no longer meaningful or accurate? Maybe stale data that hasn’t been refreshed for a lengthly period of time. For example, wheather forecast information for a given location and time of year, but based on a 5 year old records.
- Does the data pretender subscribe to a mesh wide set of security practices and access models?
- Have datasets within the data pretender been presented as authoriative without ratification from the domain owner?
- Considering our data mesh planes, defined in this blog series (IaaS, PaaS, SaaS), have the components of the data pretender been constructed correctly, or have shortcuts been taken to build data platform offerings using unmanaged resources?
- Has data been modelled within the data pretender using persisted entities from other data products rather than using virtualisation practices?
- Has all components of the data pretender to built and delivered using established configuration driven DevOps practices? Allowing the data product to be removed and recreated without excessive manual intervention.
- Has the data pretender been created using non-compliant IaC resources that haven’t be taken from the data mesh market place?
Ten probing questions (areas of exploration) seems like a good place to stop, for now. As mentioned this isn’t an exhaustive list, but hopefully makes the point of why we need to think about this and brings to light some of the failings I’ve seen when data pretenders are prematurily declared as data products. Time is often the enemy here. In the real world there is always preassure to deliver solutions and demonstrate business value. Few have the luxoury of taking our time to deliver what I often refer to as technical purity. Ultimatley we have to be pragmatic, but with compromises made in the right way to be revisited later.
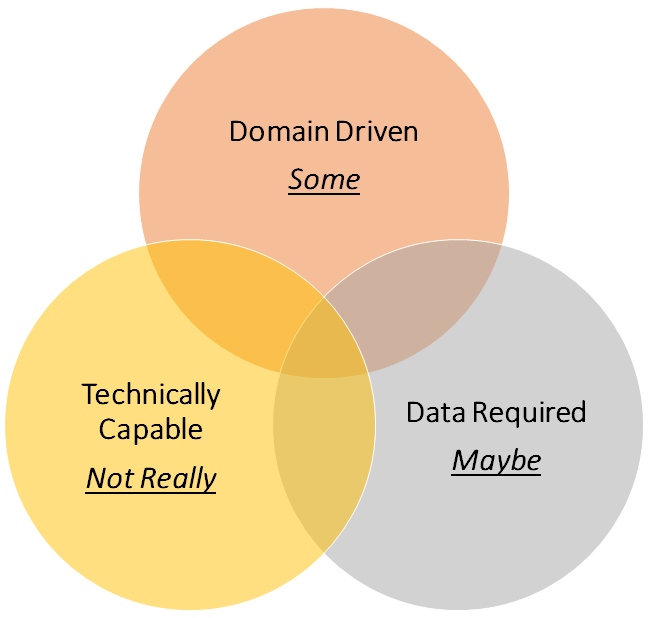
Final Thoughts
I’m not against any delivery team working towards the creation of a data product and allows dataset access to support business users sooner rather than later (pragmatic). In this context the roadmap is clear, the delivery of the data product is still in progress.
I am against the brown field solutions wish to take shortcuts and offer up an unfinished data mess, because they didn’t take the time to retro fit everything that was/is needed to gain data product status.
As always, please let me know your thoughts on this.
Many thanks for reading

One thought on “Building a Data Mesh Architecture in Azure – Part 10 – What is NOT a Data Product?”