Defining a Data Product
Use the tag Data Mesh vs Azure to follow this blog series.
I was recently asked by Data Mesh Radio host Scott Hirleman and several of my customers to define a data product. After much thinking. Below is my current answer.
In the context of an idealistic data mesh architecture, establishing a working definition of a data product seems to be very real problem for most. What constitutes a data product seems to be very subjective, circumstantial in terms requirements and interlaced with platform technical maturity. AKA, a ‘minefield’ to navigate in definitional terms.
To help get my thoughts in order (as always) here is my currently thinking and definition for a data mesh – data product.
Of course, the usual caveats apply, it probably isn’t perfect. But we can figure it out together and hopefully move towards a definition that is both generic enough and real enough that we can reach agreement.

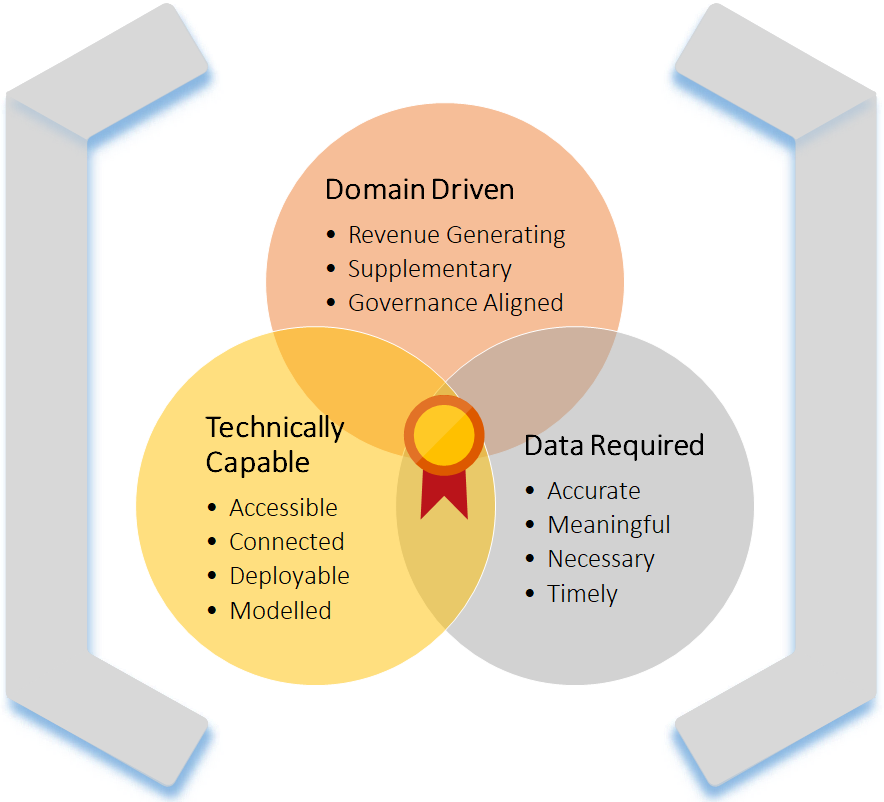
Let us break down the definition with a Venn diagram to start with. I do love representing things with overlapping circles! You’ll notice on page 30 of Zhamak’s book (Data Mesh – Deliverying Data-Driven Value at Scale) a Venn is also used to support this thinking. Great minds maybe 😉
In the Venn to the right, where we see overlap, we potentially find a data product.
But…
I think a little more depth is required for each. Maybe a 3D Venn diagram would be better! Visually it does not matter, but to address the depth I’m talking, we need to consider requirements. Later we can even think about our minimum viable set of requirements… A post for another time though.
The thing I also want to be mindful of. Declaring something as a data product could be considered a privileged state of compliance to have reached in the overall data mesh solution. Certainly, a standard that not every scrap of data we find might be able to adhere to and also a standard that can’t simply be declared for existing data platforms/applications. You can easily see a situation where a data domain works away on a series of datasets that later gets awarded/published with data product status.
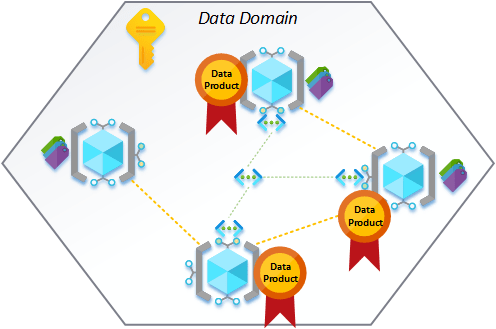
This sprint data domain ABC has completed its work for the XYZ datasets achieving data product status for the third time and awarded as a new authoritative source within the data mesh.
A little light-hearted when blogging, of course, but something in practice I see as a big deal that should be celebrated. Based on what I’m about to set out in the rest of this post as a data product definition and high bar to achieving it.
Right, let’s break this down.
Starting with the easy one first, technical capabilities. What do we mean in the context of delivering a data product in our mesh?
TECHNICAL CAPABILITIES

Given the theory vs practice theme of this blog series so far, when delivering a data mesh architecture in Azure we do have that high bar to entry in terms of what we need to build. This could be broken down using a set of technical capabilities, a technical menu if you like. For example:
- Metadata driven data ingestion. An Autoloader, if you like.
- Robust change data capture handling.
- Auditing and data lineage support.
- An enriched output dataset with business logic transformations. Maybe we call them bronze, silver, and gold layers. It seems to be a popular way to go at the moment.
- Continuous integration and continuous delivery pipelines.
- An API layer supporting developer experience interactions.
- A set of primary data interfaces through the PaaS plane, considering the points from part 2 of this blog series.
- Operational telemetry and frictionless connectivity, considering the points from part 3 of the blog series.
… to name a few technical capabilities that we could consider. The menu could be vast when thinking about tech. However, what we can then say is; if we don’t have these things, we fail to mean the minimum requirements of what is needed to deliver a data product in the mesh.
DATA DOMAIN (BUSINESS) DRIVERS

In the spirit of decentralised domain ownership and our federated governance practices. We need to consider the feasibility (or business drivers) for the data we are considering bringing into the data mesh. To think about this in terms of some simple use cases:
- A negative – if the data involves a large amount of personally identifiable information, that from a governance perspective we cannot currently support and should not exist in the platform. We might not be able to proceed. You could say an anchor in preventing official data product status if you follow the ship analogy of wind, sails, north star etc.
- A positive – if the new data helps unlock a new set of analytics capabilities and supplementary information previously missing from the data domain. We might want to make the onboarding as a data product a priority. Revenue generation for the business will always get support where possible.
These drivers, and many other examples like them, can then be used to inform the decision of the data being delivered as a product in the mesh. We can then quantify the numbers of drivers (fore/against) to determine if the data meets a minimum threshold for our data product.
DATA REQUIREMENTS

Data requirements is another potential easy one to address and lends itself nicely to the overlapping Venn diagram concept when combined with our above business drivers. But needs to be thought about from an input and output perspective. I like to break down requests for data into a scale of necessity. Answered simply by the following questions.
- What data do you require?
- Why do you require this data?
- When do you require this data?
These questions offering a starting point, but I feel a time element to this is also a critical factor. Especially in the context of delivering a data mesh data product. The platform by nature is going to have the high bar to entry as already stated, meaning when onboarding new data, it should be carefully accessed and not simply dumped into a given Data Lake, then forgotten about or unmanaged.
To support our data product definition, what/why/when should be included as attributes. But also, for how long or on what cadence will the data be refreshed. For example, an ad-hoc dataset relating to the weather forecast might support the understanding of queries relating to ice cream sales on a relative timeline, but once used and if left to become stale the requirements mean this data should not be elevated to the status of data product within the mesh.
Conclusion
Hopefully the above gives us a roadmap and way to define a data product in a way that supports the evolution of our data mesh, including data product onboarding.
To summarise, let us revisit the Venn diagram and extend the areas with some key attributes having talking around the reasoning. All of which can be accessed using respective ranges of maturity.
Question: what is a data product?
Answer: the “thing” at the centre of this Venn diagram that we can work towards delivering and achieving…
Many thanks for reading

For me this is too narrow a definition. Consider the example of a Python library written with functions to check data quality within an organisation. This is still a data product which will have a product owner and customers, and an associated implementation team, but it doesn’t fit the views above which lean very heavily towards data sets being the only data products.
LikeLike
Excellent guide! This review commends the clarity and effectiveness of ‘Building a Data Mesh Architecture in Azure.’ A valuable resource for navigating the complexities of data architecture.
LikeLike