Hi all, I get asked this question a lot. So I decided to do a full post on the subject based on my current thoughts and experience.
When should I use multiple Azure Data Factory’s?
 The consultants answer, it depends 😉
The consultants answer, it depends 😉
Ok, let’s go deeper and explore why it depends!
Also, to be clear, we aren’t talking about having multiple Azure Data Factory’s for Dev/Test/Prod environments.
My rational….
Business Processes
 The obvious and easy reason for having multiple Data Factory’s could be that you simply want to separate your business processes. Maybe they all have separate data delivery requirements and it just makes management of data flows easier to handle. For example:
The obvious and easy reason for having multiple Data Factory’s could be that you simply want to separate your business processes. Maybe they all have separate data delivery requirements and it just makes management of data flows easier to handle. For example:
- Sales
- Finance
- HR
They could have different data delivery deadlines, they process on different schedules and don’t share any underlying connections.
You may also have multiple projects underway that mean you want to keep teams isolated.
Azure Consumption
 The charging model for Data Factory is one of the most confusing things out of all Azure Resources. This is mainly because Data Factory can do so much and each part of the resource has a different charging metric. That said, calculating what a given orchestration process is going to cost is really tricky.
The charging model for Data Factory is one of the most confusing things out of all Azure Resources. This is mainly because Data Factory can do so much and each part of the resource has a different charging metric. That said, calculating what a given orchestration process is going to cost is really tricky.
Microsoft’s Azure Price Calculator: https://azure.microsoft.com/en-gb/pricing/calculator
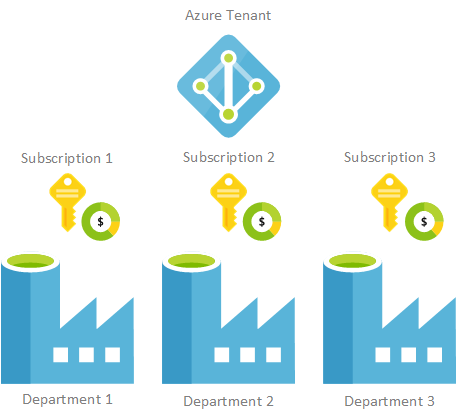
For some companies that want a really clean way of inter-department recharging having separate Azure Subscriptions is one way you might choose to handle billing. This means at an Azure Resource level each department could have a dedicated Azure Data Factory.
The flip side to that situation is that as a whole you may end up paying more for all Data Factory resources because you aren’t taking advantage of ‘economies of scale’. An example of this could be for things like Data Flow cluster compute or SSIS IR compute.
Regional Regulations
In a multiple national company regulatory restrictions may mean your data can’t leave country boundaries. Therefore having an Azure Data Factory dedicated to a particular Azure Region could be a factor.
You can overcome this in a single Data Factory using region-specific Azure Integration Runtimes, but that adds a management overhead to deployments of IR’s and aligning specific (copy) Activities to those dedicated IR’s. Therefore, separate factories might make more sense. With multiple Data Factory’s you can leave the default region ‘Auto Resolving’ IR in place without any configuration.

For those that aren’t aware, when performing data movement operations in Data Factory the compute is done at the destination (sink) location. For example, when copying data from Data Lake 1, located in East US to Data Lake 2, located in North Europe. You could say the data will be pulled by Data Factory to North Europe from East US.
Azure Regional data egress charges would also be incurred if you did this.
To clarify this point:
- Multiple region specific Data Factory’s without any configuration overhead.
- One Data Factory with region specific Integration Runtime’s, but with Activity configuration required.
Code Reuse
This is a reason not to use multiple Data Factory’s. You might only want to configure/create a single set of Linked Services and have generic Datasets for your source systems. Therefore, keeping everything in one Data Factory means boiler plate code parts is better. Plus, creating generic utility pipelines for sending emails, might be simpler if only developed, tested and deployed once.
Also, Data Factory Template‘s maybe a consideration for common data handling patterns.
Security (PII Data)
 The Azure Portal Resource Manager Access Control (IAM) options allow permissions to be assigned at Resource Group and Resource levels. Sometimes referred to as the Management Plane in Azure. However, for Data Factory that is where the granularity of security roles stop. Therefore, if you have access to Data Factory, you have access to everything Data Factory connects to via its Linked Services.
The Azure Portal Resource Manager Access Control (IAM) options allow permissions to be assigned at Resource Group and Resource levels. Sometimes referred to as the Management Plane in Azure. However, for Data Factory that is where the granularity of security roles stop. Therefore, if you have access to Data Factory, you have access to everything Data Factory connects to via its Linked Services.
Azure Key Vault offers a layer of separation to free text credentials, but typically Data Factory’s MSI will be able to read all Key Vault secrets so I wouldn’t class this as a complete security layer.
In this situation, you might want to separate your Data Factory’s to control access to the underlying connections and operations. Maybe for the sake of PII data separation or another source system containing sensitive data.
Decoupling Wider Orchestration from Workers
If you’ve been following my Metadata Driven Processing Framework (ADFprocfwk) posts for Data Factory you’ll know that I talk about Worker pipelines. These Worker pipelines contain the Activities specific to the operation we want to perform. It could be a Copy, a Notebook call, etc.
In the context of my processing framework it is perfectly acceptable to separate the Worker pipelines from the boiler plate Parent/Child framework pipelines. This could be because you want the wider solution orchestration and management to be disconnected from the data level processing.
It could also be that you want the common code base to be separated from the specific code. I don’t have any strong arguments why you might do this. But the option is there. Maybe, your organisation is structured in such a way that global operations are handed centrally from the localised operating company’s. In which case the disconnect in Data Factory’s works better for global teams.

Deployments
If your using ARM Templates to deploy Azure Data Factory you may feel like this whole sale approach isn’t great, and you’d be correct in thinking that. A massive ARM template with 100’s of parameters isn’t a nice thing to have to deal with. In this situation breaking up Data Factory’s could help. However, the better option is to not use the ARM Template’s from the ‘adf_publish’ branch altogether. Instead, use PowerShell for deploying only the Data Factory components you want. This means only the linked services/datasets/pipelines specific to a given release get deployed rather than using the ARM template approach. How? Take the JSON files from your default code branch (or feature branch) and for each file align it to the respective Set- PowerShell cmdlet as the definition file.
Generally this technique of deploying Data Factory parts is much nicer and more controlled than using the ARM Templates. However, is does mean you have to handle component dependencies and removals, if you have any.
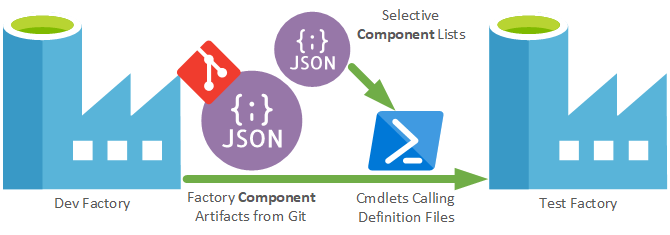 To clarify, for a large Data Factory:
To clarify, for a large Data Factory:
- Break up the Data Factory if using ARM Templates to deploy.
- Use PowerShell to control component level releases and keep the single Data Factory.
Summary
As you’ve hopefully realised there are several considerations why you might want to use multiple Data Factory resources. These considerations are very circumstantial to your organisation, setup, development team, regulations etc. However, this post outlines what those considerations are given my experience of the service.
In all cases there is the obvious deployment and management overhead of having several orchestration resources that need to be co-ordinated.
Hope this helps.
Many thanks for reading.

Excellent article.
Andrew, I am looking for simple ci/cd DevOps in Azure. I am working on Azure data factory and experience in ETL dev .
Now I want to learn how deployment works in Azure and what are tools required. If you provide your guidance
Regards,
Mangesh
LikeLike
To do DevOps in Azure, the tool you need is called ‘Azure DevOps’ 😊
LikeLike
I have a scenario where the data is stored in a single source and there are ADF pipelines created for ELT purpose. But for reasons the data is partitioned now into multiple shards.
So what is the best approach you may suggest to loop through all shards and perform ETL in each shard.
LikeLike
Hi Kiran, it sounds like you need to consider a different tool. ADF might not be the best thing to use here. Cheers
LikeLike
Hi,
I agree with you that using the one big ARM template in the ADF branch for the deployment of all ADF components in an ADF instance is not the nicest way to do deployments. I would much more like to split up all the components in a more functional manner. Being able to have multiple release pipelines in DevOps, using task groups for functional decomposition. You mention using the json templates in the collaboration branch. And deploying those using powershell? But how do you do this?
With kind regards,
Johan Berghmans
LikeLike
Hey Johan, check out Kamil’s PowerShell module Azure.DataFactory.Tools.
Cheers
LikeLike
Thanks for the reply :-). I also read about the details on how to do this in your best practices blog post. And which powershell library to use for that. In the mean time I also found documentation from Microsoft regarding the CLI library, with which you can do the same.
My preference usually is to use ARM templates for deployment. But as I said before, I agree with you that one large ARM template for all ADF components is not a good solution. What I do prefer though, in stead of using powershell scriptlets, is the usage of specific task in a DevOps release pipeline.
I don’t know i you know these already, or maybe already used them i project, but I found the following:
https://marketplace.visualstudio.com/items?itemName=liprec.vsts-publish-adf&targetId=b71ebfd3-db43-40f4-9ef4-b9692f28a045
https://marketplace.visualstudio.com/items?itemName=SQLPlayer.DataFactoryTools&targetId=b71ebfd3-db43-40f4-9ef4-b9692f28a045
And at first glance I think you can use the JSON configuration templates with these DevOps tasks as well.
I think we’ll tryout all three options in our team – both powershell/cli tasks, and the two task types I mentioned above.
With kind regards,
Johan.
LikeLike
Can you please suggest if we should create Azure Data Factory for Dev, Staging, UAT, Prod in the same subscription/resource group or separate resource group should be created for each environment.
LikeLike
I suggest you use Activity Concurrency to drive how you separate your environments. Subscriptions and Resource Groups are just for charging. Better to consider how the resources are going to scale. Check out my blog on activity limits (https://mrpaulandrew.com/2020/12/02/data-factory-activity-concurrency-limits-what-happens-next/) and I suggest understanding internal vs external activities here (https://mrpaulandrew.com/2020/12/22/pipelines-understanding-internal-vs-external-activities/)
LikeLike
Excellent article. I am in search of better CI/CD for ADF in our project. We have 3 subscriptions – Dev, Test and Prod and each having its own ADFs.
We have one ADF, multiple teams working on different use cases. They all work on their own working branch, which is fine. But we have only one collab branch (one ADF can have only one collaboration branch). If 2 team working same time and one team’s code is pushed on to Testing Env (SIT). During next sprint team 2 pushed their code on to SIT and team1’s code is moved to UAT. Form publish branch the code is taken to integration branch and form there we are deploying to multiple environments. In this scenario, team1 and team2 code are there in integration branch now. Team 1 is ready for deployment to Prod environment but the integration branch is having team2 changes as well. This one is creating all sort of problem for us – unwanted LS, Data Sets, Triggers everything is getting deployed onto Prod and we are manually deleting the triggers hence it wont get executed.
But this is not the right branching/deployment strategy for sure. We need your help on this. We have 20 use cases to build and ADF is doing all data ingestion activities for these use cases. Should we create 20 ADFs for data ingestion for 20 usecases? or any other better solution? Please advice.
LikeLike
Check out Kamil’s PowerShell module azure.datafactory.tools
LikeLike
Hi Jithesh K,
We are expecting similar issues as we have many use cases in queue. Do you found any workaround /resolution for this? Can you please share Kamil’s PowerShell module azure.datafactory.tools?
Thanks in advance.
Regards,
Hari
LikeLike
Hey, the module is available in the PowerShell gallery.
LikeLike