 In this four part blog series I want to share my approach to delivering a metadata driven processing framework in Azure Data Factory. This is very much version 1 of what is possible and where can we build on this to deliver a hardened solution for our platform orchestrator. For the agenda of this blog series I’m planning to break things down as follows:
In this four part blog series I want to share my approach to delivering a metadata driven processing framework in Azure Data Factory. This is very much version 1 of what is possible and where can we build on this to deliver a hardened solution for our platform orchestrator. For the agenda of this blog series I’m planning to break things down as follows:
- Design, concepts, service coupling, caveats, problems. Post link.
- Database build and metadata. Post link.
- Data Factory build. Post link.
- Execution, conclusions, enhancements. Post link.
Blog Supporting Content in my GitHub repository:![]()
https://github.com/mrpaulandrew/BlobSupportingContent
Part 3
Welcome back to part 3 in this 4 part blog series. In this post let’s do the plumbing to build and connect up Azure Data Factory to our Azure SQLDB (Metadata) and an Azure Function (lowest level executor).
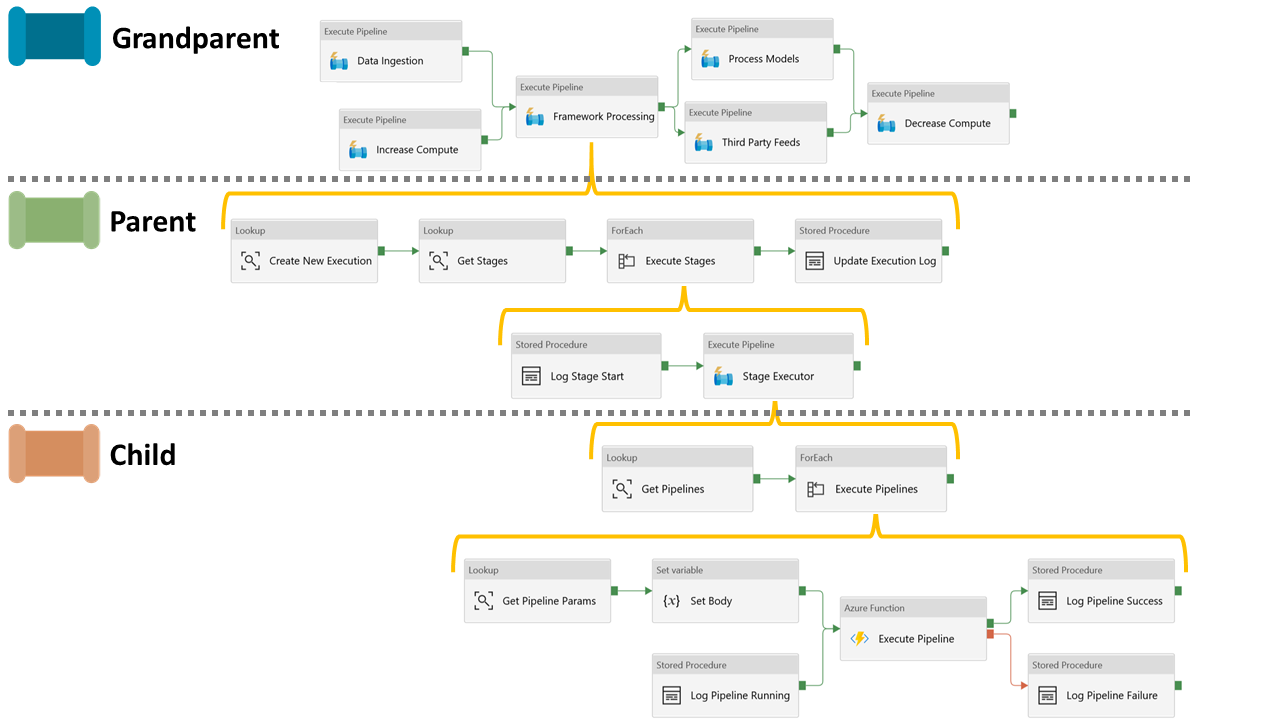
Firstly, to help guide this post below is a mock up of our Data Factory pipelines and activities to show the end goal. Hopefully this view informs how things are going to be connected using what I call a pipeline hierarchy system and how they will work in the overall framework. For our metadata processing framework we can make the following category distinctions about the activities represented:
- Grandparent – This is the top level orchestration of our wider data platform solution. Here a scheduled trigger could be connected or processing in our solution grouped into natural areas. Technically this level isn’t required for our processing framework, but I’ve included it as good practice.
- Parent – Our parent pipelines primary purpose (try saying that fast 3 times 🙂 ) is to handle the stages of our processing framework. The stages will then be passed off sequentially to our child pipeline using another execute pipeline activity.
- Child – At this level in the framework the child is hitting the Azure Function to call the lowest level executors, or the pipelines that we want to actually do the work in our data platform solution. In my previous post I added some example metadata to call pipelines name Stage X-X. These in turn relate to a set of empty place holder pipelines that contained only Wait activities.
Click to enlarge.
From this overview let’s now go deeper into the activities for each level of the framework process.
Parent Pipeline (Framework Stages Bootstrap)
As you’ve read several times now the stages of our processing framework will be executed sequentially to support a wider dependency chain. In addition to this behaviour, our parent pipeline also sets up the execution run (to provide a fixed set of metadata for the current processing) and then archives off the run details to the long term execution log, once successful.

To be explicit about what else is required in the parent pipeline, below is a exact breakdown of what each activity is doing and calling, in terms of database stored procedures and tables.
| Name | Type | Calling | Output |
| Create New Execution | Lookup | [procfwk].[CreateNewExecution] |
Copies all enabled pipeline metadata into the table [procfwk].[CurrentExecution]. |
| Get Stages | Lookup | [procfwk].[GetProcessStages] |
Returns a distinct list of [StageId] from [procfwk].[CurrentExecution] with an ascending ORDER BY clause. |
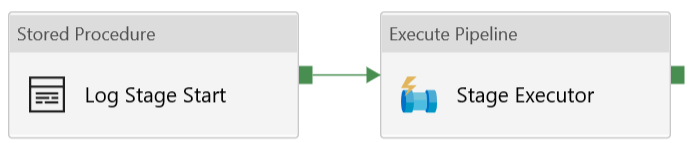
| Execute Stages | ForEach | Within the ForEach, two further activities are called:
Stored Procedure:
Execute Pipeline:
|
The stored procedure updates the table [procfwk].[CurrentExecution] setting status of the stage to ‘Running’.
The Execute Pipeline activity calls our framework child executor. This is configured to Wait on completion to ensure all stages happen synchronously. |
| Update Execution Log | Stored Procedure | [procfwk].[UpdateExecutionLog] |
Copies all current execution data from the table [procfwk].[CurrentExecution] to the long term logging table [procfwk].[ExecutionLog]. |
Next, for a single execution stage we can focus on what is does in the next level of the framework orchestration.
Child Pipeline (Framework Processes Caller)
For our child pipeline we hit our second level ForEach activity which can now run in parallel for all processes within a given execution stage. I’ve left the parallelism of the ForEach activity with its default behaviour. However, in a future enhancement of the framework I’d like the number of threads to become a global property. That said, the activity doesn’t currently allow the batch size to be set dynamically.
Please note; there is a key assumption here that the metadata is correct and that all processes can execute in parallel without compromising on data integrity or affecting any underlying business logic.
For the activities themselves in the child pipeline:
| Name | Type | Calling | Output |
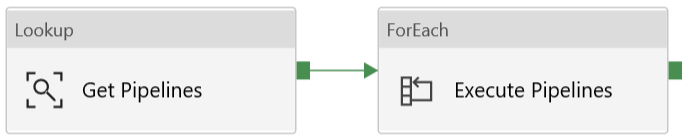
| Get Pipelines | Lookup | [procfwk].[GetPipelinesInStage]
The stored procedure is passed the StageId which is handled as a Pipeline Parameter provided by the parent.
|
The procedure returns an array of the PipelineId and PipelineName from the table [procfwk].[CurrentExecution] for the passed StageId. |
| Execute Pipelines | ForEach | I’ll detail the child executor separately for the inner set of activities from this ForEach below. | |
At the final level in our processing framework we have the following Data Factory activities:
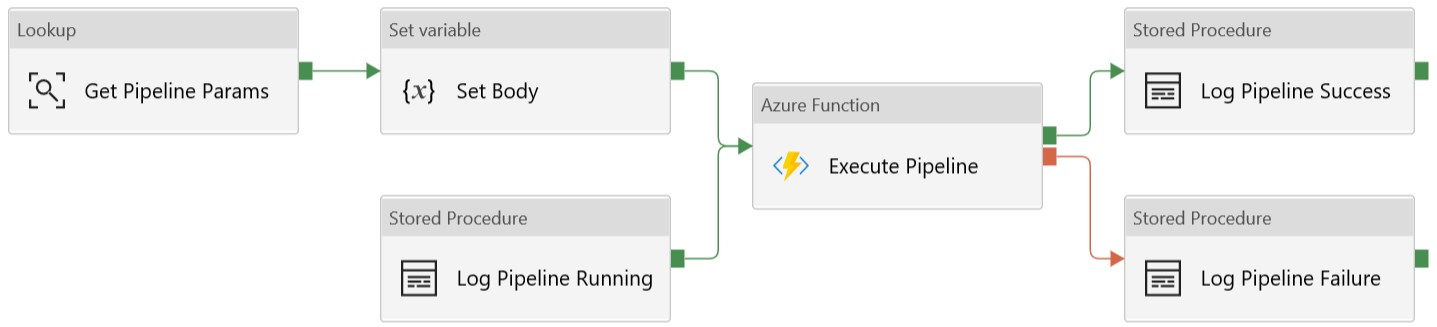
| Name | Type | Calling | Output |
| Get Pipeline Params | Lookup | [procfwk].[GetPipelineParameters] |
Returns a set of key value pair parameters for the current PipelineId. As advised in the part 2 of the blog this creates a JSON string that we can use in the Function Body. |
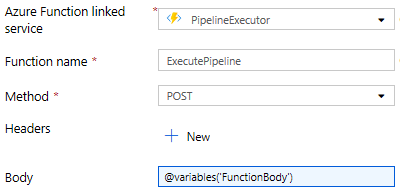
| Set Body | Set Variable | FunctionBody | From the Lookup activity to ‘Get Pipeline Params’ the output of the variable sets the Body request that is passed to the Azure Function. This is created as a separate activity for debugging ease, when developing I often set break points on this activity to see the content of the request before hitting the Function.
The In a future enhancement of the framework I’m going to update this so less of the values are hard coded in the request Body. |
| Log Pipeline Running | Stored Procedure | [procfwk].[SetLogPipelineRunning] |
Update the [procfwk].[CurrentExecution] table setting the current PipelineId to a Status of ‘Running’. |
| Execute Pipeline | Azure Function | POST to our Pipeline Executor Function App | The PipelineName is executed using the Body created in the variable 🙂
|
| Log Pipeline Success | Stored Procedure | [procfwk].[SetLogPipelineSuccess] |
Update the [procfwk].[CurrentExecution] table setting the current PipelineId to a Status of ‘Success’. |
| Log Pipeline Failure | Stored Procedure | [procfwk].[SetLogPipelineFailed] |
Update the [procfwk].[CurrentExecution] table setting the current PipelineId to a Status of ‘Failed’. |
That concludes the chain of activities to run the processing framework.
Datasets and Linked Services
For completeness, the before operations all used a single dataset and only three linked services as follows.
| Name | Type | Role |
| Vault of Keys | Azure Key Vault | To allow Data Factory to request authentication secrets for the other two linked services. |
| Pipeline Executor | Azure Function | To allow Data Factory to hit the Azure Function App and POST to the function that calls the low level pipelines for execution. |
| Support Database | Azure SQL Database | To allow Data Factory to interact with the procfwk database schema and metadata. |
| Get Set Metadata |
AzureSqlTable
|
Dataset to provide activities a method for calling stored procedures in the metadata database. |
 I appreciate that sometimes when building a Data Factory its easier to visually click around the UI of the example being followed or at least look at the JSON. I’ve therefore added version 1.0 of the Data Factory ARM template to my ‘Blog Supporting Content’ GitHub repository. However, I’m working on sorting out the authentication details currently hard coded in the body request (these have been modified in the ARM template for obvious reasons). Stay tuned for part 4 of this blog series, new releases are coming.
I appreciate that sometimes when building a Data Factory its easier to visually click around the UI of the example being followed or at least look at the JSON. I’ve therefore added version 1.0 of the Data Factory ARM template to my ‘Blog Supporting Content’ GitHub repository. However, I’m working on sorting out the authentication details currently hard coded in the body request (these have been modified in the ARM template for obvious reasons). Stay tuned for part 4 of this blog series, new releases are coming.
This concludes the third part in this blog series. To recap:
- Pipelines created.
- Activites built with all required dynamic expressions.
- Datasets and linked services created.
In part 4 of Creating a Simple Staged Metadata Driven Processing Framework for Azure Data Factory Pipelines we’ll finish up the blog series, create some meaningful conclusions from the approach and think about next steps to enhance the framework.
Many thanks for reading.

I may try this out with Logic Apps instead of Azure Functions as my peers prefer as little code as possible.
LikeLike
Sure, funny thing is, ADF is just logic apps underneath. Better to hit the Azure Management API, if your downstream pipeline requests are simple. I use Function for the procfwk.com so I can call Synapse and ADF pipelines interchangeabily.
LikeLike