 In this four part blog series I want to share my approach to delivering a metadata driven processing framework in Azure Data Factory. This is very much version 1 of what is possible and where can we build on this to deliver a hardened solution for our platform orchestrator. For the agenda of this blog series I’m planning to break things down as follows:
In this four part blog series I want to share my approach to delivering a metadata driven processing framework in Azure Data Factory. This is very much version 1 of what is possible and where can we build on this to deliver a hardened solution for our platform orchestrator. For the agenda of this blog series I’m planning to break things down as follows:
- Design, concepts, service coupling, caveats, problems. Post link.
- Database build and metadata. Post link.
- Data Factory build. Post link.
- Execution, conclusions, enhancements. Post link.
Blog Supporting Content in my GitHub repository:![]()
https://github.com/mrpaulandrew/BlobSupportingContent
Part 4
Here we are! Part 4. This is very much an optional read. If you’ve been through the other steps in this blog series I’m hoping you now have a working processing framework. If not, we’ll go through a quick run anyway. However, the main reason for this final post was to draw some conclusions and wrap up the implementation of ADF.procfwk v1.0 .
The below picture on my whiteboard at home is where it started in the middle of February 2020 when I hit the Data Factory service limit of having 40 activities within a single pipeline and needed to do something different for the orchestration of a data platform solution. I’ve delivered lots of things with pipelines hierarchies and using frameworks to execution Databricks Notebooks in the past, but nothing generic enough to call ADF child pipelines as the lowest level executor.

As you’ll know this drawing turned into the below fairly complex set of Data Factory activities that we built in part 3 of the blog series.
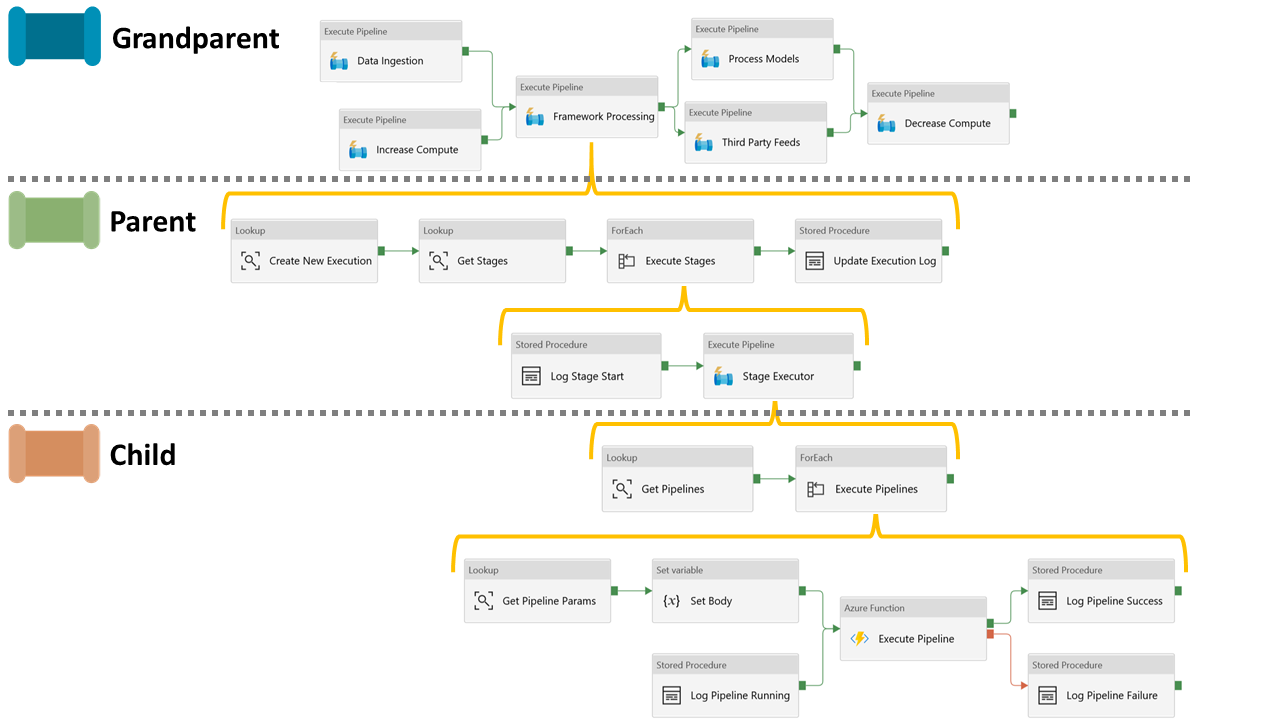
I think I prefer my whiteboard version! 🙂
Anyway, design to delivery done. What next…
End to End Execution
 For the end to end run of the framework we have a few options to see progress once its been triggered. Before that its worth pointing out that in the below I’ve used the sample metadata provided with the database scripts in GitHub. Then for each execution pipeline I’ve added a single Wait activity with a random time delay of a few seconds. The point here is to test the framework execution, not the pipelines being called. To further clarify, the Stage X-X pipelines names should be replaced with your actual pipeline names in your data platform solution.
For the end to end run of the framework we have a few options to see progress once its been triggered. Before that its worth pointing out that in the below I’ve used the sample metadata provided with the database scripts in GitHub. Then for each execution pipeline I’ve added a single Wait activity with a random time delay of a few seconds. The point here is to test the framework execution, not the pipelines being called. To further clarify, the Stage X-X pipelines names should be replaced with your actual pipeline names in your data platform solution.
Moving on to the execution itself, the results:
- Viewing the status of each stage and pipeline via the table
[procfwk].[CurrentExecution]as shown below (GIF only loops 3 times). As you’ll know from the parts 2 and 3 of the blog series this table is updated via various stored procedures during each level of the execution. Here the local execution ID GUID is the key to these updates for each stage and pipeline in the current run.

- Viewing everything via the Data Factory monitoring portal, also shown below. This offers much better insight into each activity and what parameters are being passed around if/when debugging. However, for an overview from a successful run I prefer the database table. Maybe later we could use a Power BI dashboard for this 😉

The key principal of this framework is that because we are calling existing pipelines (triggered using the Azure Function) at the lowest level of execution nothing about the monitoring is hidden in multiple levels of activity calls. Everything from the pipeline doing the work can be inspected at the top level in the monitoring portal. It is simply chained within the wide framework pipeline calls.
I’m highlighting this statement as this is the made concern I commonly face when building anything dynamic/metadata driven in Data Factory. “Will it be easy to debug?” Yes. Boom! Operational understanding of Data Factory should not change. Thank you 🙂
Next when running your own framework, I have a few top tips that may help…
- Make sure the Data Factory pipelines that are being called have been published to the Data Factory service being hit by the framework. Running the parent bootstrap pipeline in Debug mode is fine. However, the Azure Function will call published (deployed) pipelines only and it has no understanding of the Data Factory debug environment. Or to phrase this differently, run the framework in debug mode, but call published pipelines. After all, the publish pipelines shouldn’t be the thing we are checking, they are separate features in the wider solution (in theory).
- Ensure the SQLDB is scaled up to an appropriate level to handle the calls from Data Factory and considering the levels of concurrency that you may reach with your low level processes.
 Ensure the Azure Function App is running with a suitably scaled App Service Plan. Especially if you have long running pipelines that may hit basic service tier timeout limits (Microsoft Docs Link). Remember the function will block and wait for the pipeline it called to complete.
Ensure the Azure Function App is running with a suitably scaled App Service Plan. Especially if you have long running pipelines that may hit basic service tier timeout limits (Microsoft Docs Link). Remember the function will block and wait for the pipeline it called to complete.- When you hit the ‘Preview’ button via Data Factory for a given activity it isn’t aware that a stored procedure might be called, not a table/view. Therefore you need to make sure that executing the stored procedure is what you actually want to do as part of the preview data returned in the Data Factory UI. In the case of the ‘Create Execution’ Lookup activity the procedure will truncate the table
[procfwk].[CurrentExecution]. In short, in the screen snippet below, Preview Data = Execute Procedure.

- Currently on completion of an execution run the table data from
[procfwk].[CurrentExecution]is copied to the long term log table[procfwk].[ExecutionLog]and the current execution table truncated. If your pipeline(s) complete very quickly this data may get archived off before you’ve queried the current run table. This can lead to me/you thinking that nothing happened the first time and getting very confused because Data Factory shows it did execute! If you have any doubts, just use the following query to ensure you return details of the last execution.
Click for link to T-SQL in GitHub.

That concludes the execution part of this blog post, please let me know if you had any issues setting up the framework in your own environment. I’d be happy to spend some time debugging things with you so reach out.
Planned Enhancements
In true Microsoft style I think I’ve delivered a minimal viable product and will then release updates to improve the core functionality once its been tested by end users, much to everyone’s frustration when Microsoft do this! 🙂 If you can’t beat them, join them!
Anyway, below I’ve bulleted pointed the high level things that I’m going to include in later releases of the ADF.procfwk. If you have any other ideas or even a priority for the below list please comment on this post and I’ll add them to the mini backlog. I’d also be open to collaborating on this as a code project if you want to contribute?
- Restartability for a failed pipeline executions.
- Stored procedure defensive checking of values passed vs metadata.
- Performance views for the long term log table. Eg. Average pipeline duration.
- Add database view for the last execution run using the log table.
- A better error handler path with actual error details captured.
- Add a Data Factory metadata table.
- Add a Subscription metadata table.
- Add Global properties, to include:
- Second level ForEach settings.
- Tenant Id.
- Update the Function to avoid hardcoded authentication details.
- Pre-execution data integrity checks against all metadata.
- Add email alerting.
- Create a Power BI dashboard for monitoring large scale solutions.
- Create a PowerShell script to get and set pipeline processing for a given Data Factory resource.
- Update the Staging and Pipeline tables to use none sequential numbers for ID’s meaning adhoc stages could later be injected. Eg. 10, 20, 30.
- Refactor the stored procedures that update the current execution table in a single multi status version.
- Create a script to pre-populate the stages and pipelines metadata tables.
Version 1.1 Coming Soon
![]() You’ll be pleased to know that while writing up this blog series for version 1.0 of the processing framework I started work on the next release. To do this I’m promoting all the code into its own dedicated GitHub repository and giving it a proper Visual Studio solution to work from. This is currently a private repository, but I’ll make it public soon and write up a blog post for the v1.1 enhancements.
You’ll be pleased to know that while writing up this blog series for version 1.0 of the processing framework I started work on the next release. To do this I’m promoting all the code into its own dedicated GitHub repository and giving it a proper Visual Studio solution to work from. This is currently a private repository, but I’ll make it public soon and write up a blog post for the v1.1 enhancements.
Conclusions
Firstly, to recap on this specific blog:
- Version 1.0 metadata framework built.
- Version 1.0 ran using basic metadata and simple pipelines.
- Enhancements backlog started.
- Version 1.1 planned for release soon.
Next, a reflective moment on the blog series and the framework created.
Producing something from scratch is always hard, but maybe not as hard as rebuilding something already in place. My hope is that in both cases applying this framework to any data platform solution (old or new) should be fairly easy, mainly because we don’t need to change existing child pipeline functionality. The only immediate challenge might be populating the metadata tables with values that reflect your processes and produce the required dependency chain using this framework Stages and Pipelines concepts. As a side note; scrapping a list of current Data Factory pipelines can be done by parsing the ARM template with T-SQL, see my previous blog on that. Or maybe with a little PowerShell using the Get-AzureRmDataFactoryV2Pipeline cmdlet
Finally, some wrap up questions to come full circle on the questions I raised in part 1 of the blog series when thinking about the design:
- Is this framework perfect? No.
- Does it handle a wide reaching set of orchestration challenges? Yes, I think so.
- Does it overcome limitations in the Data Factory resource? Yes.
- Are we still uncomfortable about tightly coupling Azure SQLDB with Azure Data Factory? Yes, but what other choice do we have? Comment welcome.
- Does a set of generic pipelines driven with metadata make daily operations difficult to troubleshoot? No, because we trigger the pipeline doing the work in an abstract way using the Azure Function so all monitoring stays the same.
- Could we expand this framework to cover multiple Data Factory’s? Yes.
- Is an Azure SQLDB the best type of store for our metadata? I think so. Mature, flexible, easy and relational. Although happy to argue about a dependency chain being better suited to a graph database.
- Does this framework support the required level of toggle control over process? Yes, but it needs to be set before an execution run starts.
That’s all for now folks. I’ve really enjoyed building this framework and will continue developing it. I’d love to hear about anyone that has also applied it to a solution.
Many thanks for reading.

Hello Andrew,
It is a very detailed blog. Very informative as always. The model can be expanded to include Exception and Error data from the pipeline runs. It will work in tandem with the model you have used here. It will help with a detailed report of the load metrics. Just sharing my suggestions.. 🙂
Thanks,
Arun
LikeLike
Hi Arun
Error detail capture will be included in release v1.6 next week.
Thanks
Paul, not Andrew
LikeLike
Thanks for the reponse Paul. Looking forward to the post.
LikeLike
Great blog Paul! Will experiment with it shortly, thanks very much! 🙂
LikeLike
Thanks, make sure you check out the release details for the latest version via the blog post category… https://mrpaulandrew.com/category/azure/data-factory/adf-procfwk/
LikeLike
I am still playing catch up. I remember using PROJECT REAL’s reference implementation as a boilerplate in delivering some solutions in SSIS. I consider this the ADF equivalent!
Regarding your final bullet point, a maintenance front end for populating the metadata schema would not be a bad project enhancement. I remember creating a script when sewing the Kimball Architecture for Data Quality into the MSFT DWH Toolkit solution as well. There just aren’t enough hours in the day to do this on your own…..it becomes so easy to get lost inside…
LikeLike
Ok thanks for the feedback
LikeLike