Best practice for structuring your Azure Data Factory?
 Hello friends, this post and my next few posts have been born out of a community talk I’ve delivered a couple of times now at various conferences. In my session I talk about using Azure Data Factory (ADF) in production – inspired by my own lessons learnt with the cloud technology over the years. Well, as with most community events an hour never feels long enough to share everything. Therefore, in this post I’m going to cover one aspect of said PowerPoint deck – the hierarchy of pipelines that you could create in ADF.
Hello friends, this post and my next few posts have been born out of a community talk I’ve delivered a couple of times now at various conferences. In my session I talk about using Azure Data Factory (ADF) in production – inspired by my own lessons learnt with the cloud technology over the years. Well, as with most community events an hour never feels long enough to share everything. Therefore, in this post I’m going to cover one aspect of said PowerPoint deck – the hierarchy of pipelines that you could create in ADF.
Now, before going deeper we can probably start by saying that this isn’t a new concept. In a previous life, I’ve applied this same idea of having a grandparent, parent, child and infant structure to SQL Server Integration Services (SSIS) packages. And I’m sure many other people out there have done the same. Given that, we can safely say, as a concept, we are fairly mature in our thinking/understanding of how we might want to separate these execution planes. This is mainly due to how we might translate the concept to SSIS package execute in a legacy ‘extract, transform and load’ type solution. Hopefully you agree and we can make a few assumptions in understanding.
Next, even if the concept isn’t new, where I’d like to call out two big differences in my approach to orchestration with ADF comes from working within Microsoft Azure. The highly scalable cloud platform presents some new challenges that SSIS simply didn’t. For me these are:
- Needing to consider our wider solution and what things now cost. I’m fairly sure I’ve said it before. When working with ‘Pay-as-you-go’ services we need to think about designing for cost/consumption as well as all our other data transformation and output requirements. In Azure it is so easy to just leave resources running night and day, when only a short window of compute is needed.
- We need to consider the scale out capabilities of the other services that ADF is going to invoke. Or, to put it another way, how much parallel activity execution do we want ADF to achieve? As you may know the ADF ForEach activity by default allows us to execution inner activities in parallel, but is that enough?
In the below content I’ll cover my approach for handling both of these cloud based factors in our hierarchical design of ADF pipelines as well as covering be reasons for separating our control planes.
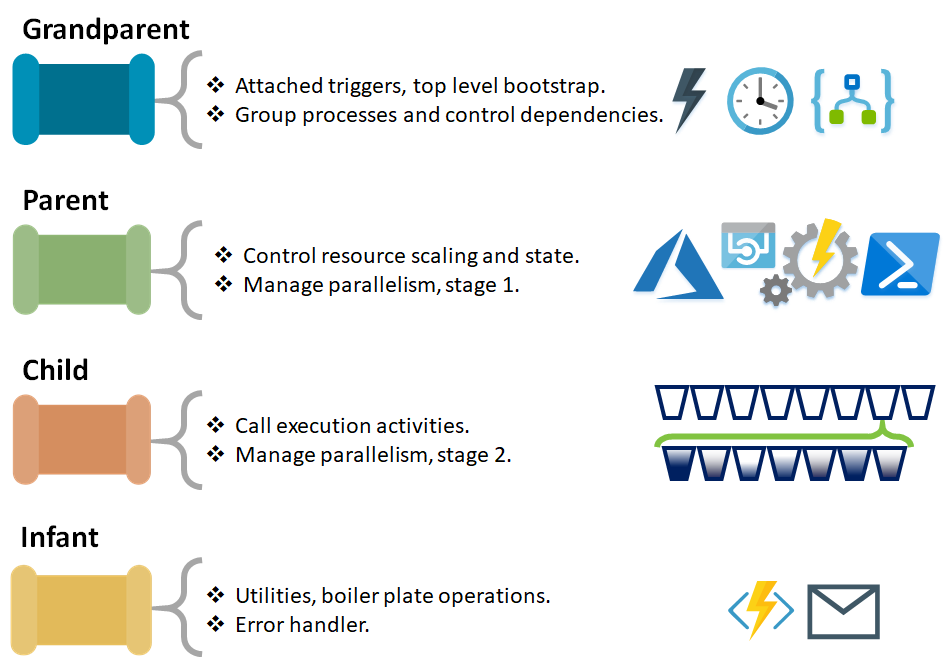
 Grandparent
Grandparent

Firstly, the grandparent, the most senior level of our ADF pipelines. In our grandparent pipeline my approach would be to build and consider two main operations:
- Attaching Data Factory Triggers to start our solution execution. Either scheduled or event based. From Logic Apps or called by PowerShell etc. The grandparent starts the processing.
- Grouping the execution of our processes, either vertically through the layers of our logical data warehouse or maybe horizontally from ingestion to output. In each case we need to handle the high level dependencies within out wider platform.
If created in Data Factory, we might have something like the below.
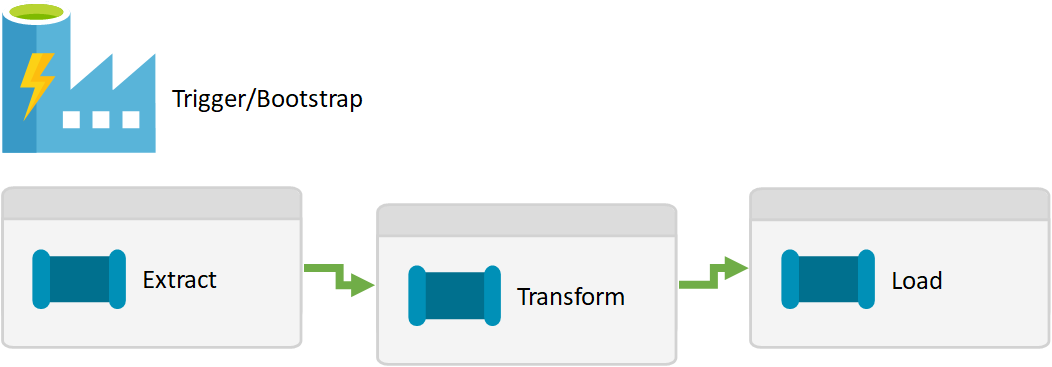
In the above mock-up pipeline I’ve used extract, transform and load (ETL) as a common example for where we would want all our data ingestion processes to complete before starting any downstream pipelines.
 Parent
Parent

Next, our parent, at this level my approach would be to handle two further elements of our data processing solution:
- Controlling the scale and state of the services we are about to invoke. For example, when working with:
- Azure SQL Database (SQLDB), scale it up ready for processing (DTU’s).
- Azure SQL Data Warehouse (SQLDW), start the cluster and set the scale (DWU’s).
- Azure Analysis Service, resume the compute, maybe also sync our read only replica databases and pause the resource if finished processing.
- Azure Databricks, start up the cluster if interactive.
- To support and manage the parallel execution of our child transformations/activities. The Data Factory ForEach activity helps, but if we want more I use the concept of buckets, which I’ll cover in more detail in a later blog post. For now let’s think about these examples, when working with:
- Azure SQLDB or Azure SQLDW, how many stored procedures do we want to execute at once.
- Azure SSIS in our ADF Integration Runtime, how many packages do we want to execute.
- Azure Analysis Service, how many models do we want to process at once.
If created in Data Factory, we might have something like the below, where SQLDB is my transformation service.
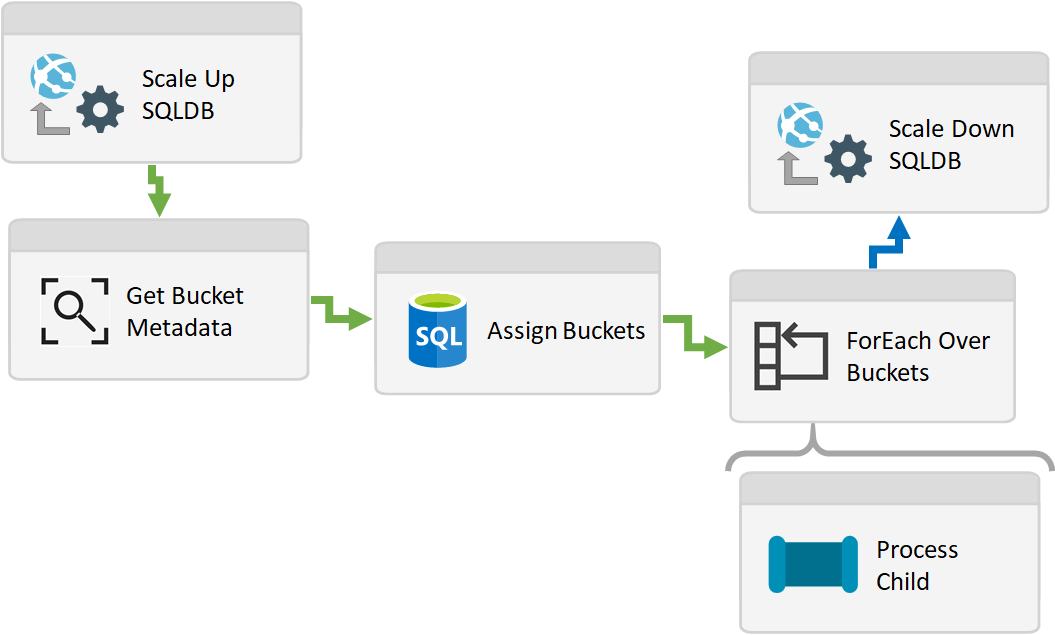
In the above mock-up pipeline we are firstly scaling up our SQLDB, then establishing our buckets from metadata and calling the first stage ForEach activity which will contain the child pipeline caller.
 Child
Child

Next, at our child level we handle the actual execution of our data transformations. Plus, the nesting of the ForEach activities in each parent and child level then gives us the additional scale out processing needed for some services.
If created in Data Factory, we might have something like the below.
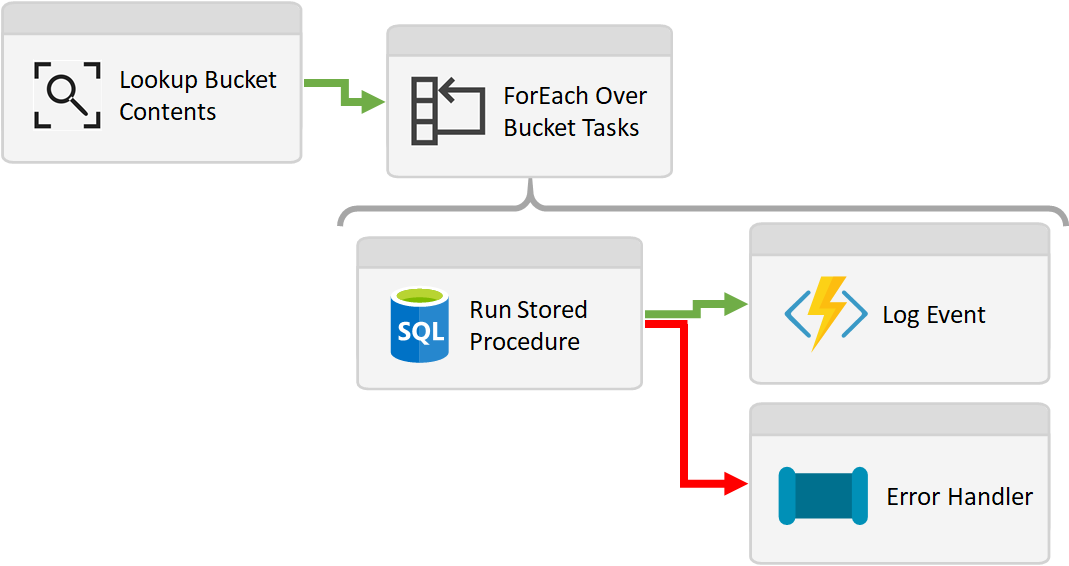
In this mock-up pipeline we are getting the contents of a bucket, created at the parent level. Then in a second stage ForEach activity running the lowest level transformation operations against the given compute. Logging the outcome at each stage then allows up to re-distribute our buckets if the amount of compute needed per bucket becomes uneven as data volumes increase.
Infant (Utilities)

Finally, our infant pipelines. As you’ll see from the subheading I’d also describe our infant pipelines as our utilities or boiler plate code if you prefer. Our infants contain reusable handlers and calls that could potentially be used at any level in our solution. The best example of an infant is where I’ve called an ‘Error Handler’ in my child pipeline mock up above. As already stated, these utilities could be called from any part of our solution as required.
If created in Data Factory, we might have and ‘Error Handler’ infant/utility containing something like the below.

Specifically for an error handler process my approach would be to pass several parameter into the downstream activities.

Summary
To summarise this design pattern I’ve put together the below table for reference and as a PDF to take away, here.
I hope you found this post useful. I’d be really interested in your comments and if we would consider this approach as an emerging best practice for structuring your Data Factory.
Many thanks for reading.

Great pattern. Have you implemented it in a production project and seen the nuances and will you say it’s more complicated than straight old SSIS packages? I’ve tried my hands on ADF several times and do find the ability to connect to many cloud resources S3, and other data systems quite easy and abstracted, but the simple things SSIS or T-SQL does best are quite cumbersome to do without calling procs.
LikeLike
Yes, several times now.
Agreed.
LikeLike
Hi Paul,
Great Blog !
Do you have a sample json for the pipeline hierarchy that you would like to share in your GitHub repository for reference ? Looking forward to hearing from you.
Thanks and regards
Ambar
LikeLike
Hi Paul,
Great blog thank you for sharing this , i have a situation where i need to get on-prem data which doesn’t support encryption, but I want to encrypt data in-transit irrespective of source, how easy is to achieve this ?
LikeLike
I suggest the simplest way would be to use a private connection to Azure either with a secure gateway/endpoint or with an Express Route circuit. Then as things aren’t going over the public internet you could avoid doing the encryption work? Just an idea.
LikeLike
Thank you for beiing you
LikeLike