![]() Hi data friends! Version 1.1 of my ADF.procfwk is ready!
Hi data friends! Version 1.1 of my ADF.procfwk is ready!
Following the great response I got to the version 1.0 blog series I decided to push ahead and get version 1.1 out there as soon as possible. The main thing I’ve addressed with this release is the big problem of having hard coded service principal credentials in the body of the Azure Function request that called our execution pipelines. Hopefully we can all agree this was/is not great for a number of reasons.
Before we dive into the details of the release the other exciting thing to share is that the ADF.procfwk now has its own public GitHub repository, complete with Visual Studio Solution. As promised in the previous part 4 blog series this repository includes all the artifacts needed to get processing framework setup in your tenant. Projects and files included are:
- The content of my new ‘FrameworkFactory’ Azure Data Factory, which is linked directly to the same GitHub repository.
- A SQL Database project for all parts of the Azure SQL metadata objects, including sample data via post deployment scripts.
- A C# Azure Functions project used for calling our pipelines.
- An empty deployment project that I’m planning to use in conjunction with a release pipeline in a later version. Should we use Azure DevOps?
- Read me, release version and backlog details via some root Markdown files.
- An archive of ARM templates for the Data Factory taken manually from the adf_publish branch.
- Images and none technical bits of collateral to support various blogs and documents.
Link to all this good stuff in GitHub below.
Please also be aware that I’ve added a new blog post category to group all ADF.procfwk things together for readers. I hope this helps track the evolution of the processing framework.
ADF.procfwk in my GitHub repository:![]()
github.com/mrpaulandrew/ADF.procfwk
Release Overview
As mentioned above the main reason for this release is to remove the hard coded SPN details used in the body of the Azure Function request. To do this I’ve moved the authentication details required by the Azure Function into the SQLDB. I explored options for getting the Function to call Key Vault directly but this then presented another issue of coupling Key Vault to the processing pipeline executions. It also would mean having a very chatting solution that potentially couldn’t be used to call any Azure Data Factory pipeline in any Azure Tenant.
Given this I went for the least worst option (and while still trying to keep things simple) of creating a service principals table in the metadata database. To promote good handling of these credentials and to ensure things aren’t stored as plain text I’ve added the following layers of security for the framework.
- At runtime Data Factory will be authenticated to access the SQLDB with its existing Linked Service connection (backed by Azure Key Vault). This connection and credential will use a special database ROLE that I’ve called
[adf_procfwkuser]. - The database role will have only SELECT and EXECUTE permissions for the procfwk database schema.
- Service Principal details will be stored in a table under the dbo database schema, rather than procfwk.
- Adding and deleting Service Principals will need to be handled using a pair of internal stored procedure which ensure data integrity between the metadata as well as adding the SPN values.
- It is recommended that the SPN used only have contributor access to the Azure Data Factory being called to run the processing pipelines.
- The Service Principal secret will be encrypted using a combination pass phrase which will be linked to the calling Data Factory and Pipeline.
- The secret will be held in the database in a VARBINARY format and only decrypted at runtime when provided with the correct metadata combination for the pipeline being exeucted.
- Processing pipelines can have dedicated Service Principals per Pipeline or per Data Factory.
- The Tenant Id and Subscription Id are held separately in the properties table.
In all cases, these assumes, like with the Azure Portal itself that user access via the portal management plane is sound. If you were an Owner on the Azure Subscription, or the Resource Group where the processing framework resources are deployed these things could be easily avoided. That said, if you were an owner on the subscription you would just manipulate Data Factory directly and not need to worry about framework callers. Therefore, these layers of security are all relative.
To attempt to visual that I’ve created the following authentication flow.

Given this, the database table [dbo].[ServicePrincipals] could be considered as a second level metadata Key Vault.
Bug Fix
By accident, doing this release meant fixing a bug in v1.0 of the processing framework (sorry) where the Azure Function body was being created using a variable within the child pipeline. This variable was set for each of the pipelines being called before passing the resulting concatenated body (as a variable) to the Azure Function. Unfortunately, variables are scoped at the child pipeline level, meaning the parallel execution of the second level ForEach activity was not “thread safe” when it came to setting/creating the new variable strings for each pipeline being called. This was certainly a miss placed assumption I had about the scope of pipeline variables. Please watch out for this if using v1.0 and refactor the ‘Set Body’ activity as a priority. Workaround below.
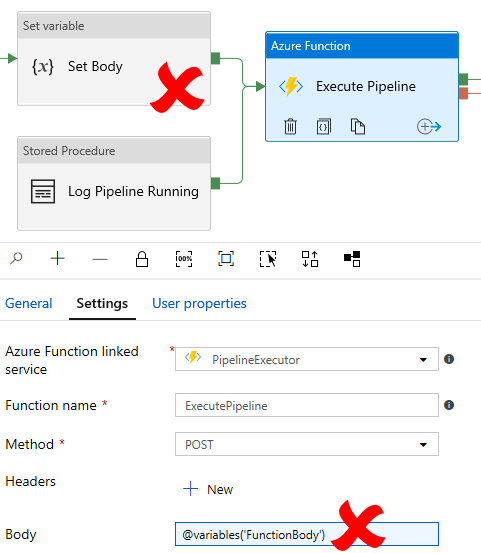
As a quick work around you can simply copy the expression from the ‘Set Body’ activity and use it to replace the body expression in the ‘Execute Pipeline’ function activity. Then delete the variable parts from the pipeline and re-connect the Lookup activity.
Database Changes
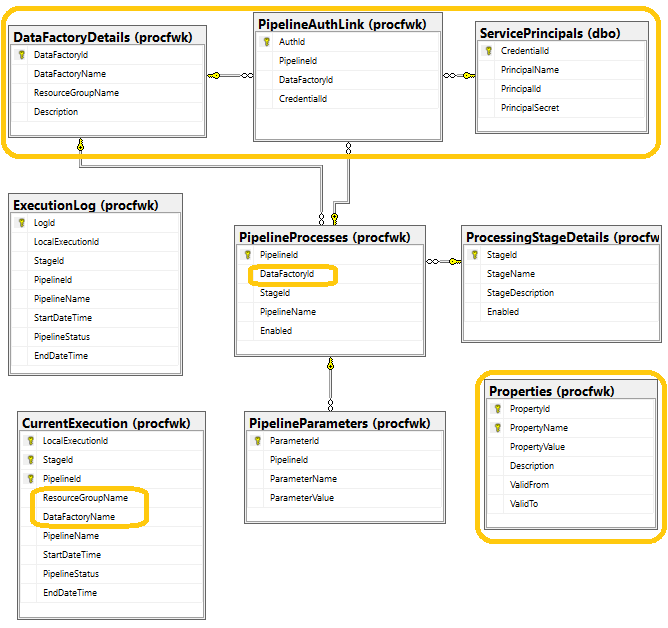
Tables
[procfwk].[DataFactoryDetails]– extends the existing metadata to the next level allowing many pipelines to be joined to a Data Factory and Resource Group record.[procfwk].[PipelineProcesses]– updated to support the new relationship to the Data Factory metadata table.[dbo].[ServicePrincipal]– added to house encrypted service principal details in an isolated schema to all other metadata.[procfwk].[PipelineAuthLink]– allows a many to many relationship between Service Principal’s, Data Factory’s and Pipelines.[procfwk].[Properties]– houses global properties for the framework and supporting slowing change behaviour for property values.[procfwk].[CurrentExecution]– updated with new attributes for Data Factory name and Resource Group name.
Views
[procfwk].[CurrentProperties]– filters the underlying properties table where the ‘valid to’ date field is NULL.
Stored Procedures
[procfwk].[AddProperty]– for internal use, to add system properties using ‘valid from’ and ‘valid to’ date behaviour within the properties table.[procfwk].[GetPropertyValue]– allowing Data Factory calls to retrieve the current version of a property value using the property name.[procfwk].[GetServicePrincipal]– allowing Data Factory to decrypt and return a Service Principal ID and Service Principal Secret for a given Data Factory and Pipeline.[procfwk].[AddServicePrincipal]– for internal use, to add and encrypt new Service Principal details as well as populate the required metadata link table.[procfwk].[DeleteServicePrincipal]– for internal use, to delete Service Principal details as well as delete records from the metadata link table where they exist and are no longer used by other pipelines.[procfwk].[CreateNewExecution]– updated to now populate the Data Factory name and Resource Group name from the metadata name at runtime.[procfwk].[GetPipelinesInStage]– updated to return the Data Factory name and Resource Group name in the child pipeline caller.
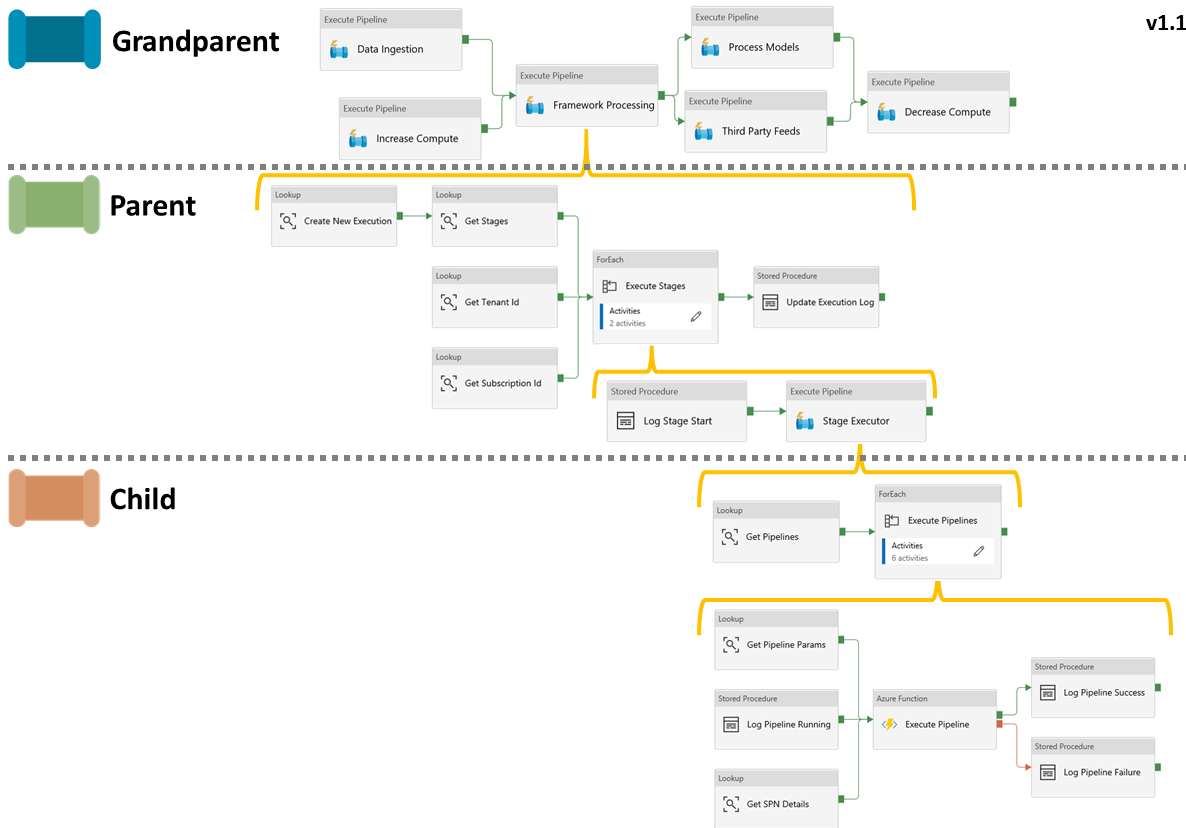
Data Factory Changes
For Data Factory the changes are minimal. Only three new activities have been added:
- Two Lookups at the parent level to retrieve the Tenant Id and Subscription Id, both use the stored procedure
[procfwk].[GetPropertyValue].
These values are then passed onto the child executor as pipeline parameters.
- One Lookup at the child level to retrieve the SPN details for the given pipeline being called which uses the stored procedure
[procfwk].[GetServicePrincipal].
Finally, the definition of the lookup ‘Get Pipelines’ has been refreshed to now also return the Data Factory name and Resource Group name using the new metadata.
Once returned, the outputs received from the databases procedures drive the body of the Azure Function call by replacing the static values with the following new expression.
@concat('
{
"tenantId": "',pipeline().parameters.TenantId,'",
"applicationId": "',activity('Get SPN Details').output.firstRow.Id,'",
"authenticationKey": "',activity('Get SPN Details').output.firstRow.Secret,'",
"subscriptionId": "',pipeline().parameters.SubscriptionId,'",
"resourceGroup": "',item().ResourceGroupName,'",
"factoryName": "',item().DataFactoryName,'",
"pipelineName": "',item().PipelineName,'"',activity('Get Pipeline Params').output.firstRow.Params,'
}')
This concludes the update for version 1.1 of my metadata driven processing framework. Version 1.2 will be started in the coming weeks.
As before, please reach out if you need any support implementing this.
Many thanks for reading.

3 thoughts on “ADF.procfwk v1.1 – Service Principal Handling via Metadata”