Code Project Overview
![]() This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is made possible by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist.
This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is made possible by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist.
The framework is designed to integrate with any existing Data Factory solution by making the lowest level executor a stand alone Worker pipeline that is wrapped in a higher level of controlled (sequential) dependencies. This level of abstraction means operationally nothing about the monitoring of orchestration processes is hidden in multiple levels of dynamic activity calls. Instead, everything from the processing pipeline doing the work (the Worker) can be inspected using out-of-the-box ADF features.
This framework can also be used in any Azure Tenant and allow the creation of complex control flows across multiple Data Factory resources by connecting Service Principal details through metadata to targeted Subscriptions > Resource Groups > Data Factory’s and Pipelines, this offers very granular administration over data processing components in a given environment.
Framework Key Features
- Granular metadata control.
- Metadata integrity checking.
- Global properties.
- Complete pipeline dependency chains.
- Execution restart-ability.
- Parallel execution.
- Full execution and error logs.
- Operational dashboards.
- Low cost orchestration.
- Disconnection between framework and Worker pipelines.
- Cross Data Factory control flows.
- Pipeline parameter support.
- Simple troubleshooting.
- Easy deployment.
- Email alerting.
ADF.procfwk Resources
| Blogs | mrpaulandrew.com/ADF.procfwk | |
| GitHub | github.com/mrpaulandrew/ADF.procfwk | |
 |
#ADFprocfwk | |
| Vlogs | youtube.com/mrpaulandrew |
Thank you for visiting, details on the latest framework release can be found below.
Version 1.8 of ADF.procfwk is ready!
Release Overview
Following more great feedback from the Data Platform community the primary goal of this release was to further improve the resilience of the framework processing. These improvements included its restart clean up capabilities and introducing better dependency chain handling between Worker pipelines when failures occur. The latter builds on the existing restart functionality first introduced in release v1.2 and supplements the logic using a new set of pipeline dependency metadata. I’ve created the below visual to conceptually show the new dependency chain behaviour, should you wish to populate and make use of the new metadata handling.

Its important to say that this is another optional feature of the processing framework and is driven by the database properties table. By default, failure handling and restart functionality will remain exactly the same as in previous releases. Then when ready, you can implement the new dependency chain behaviour.
 Database Changes
Database Changes
The updates in this release relating to better pipeline dependency handling and the restart clean up process mean a lot of stored procedure changes. But only one new table added to the database ([procfwk].[PipelineDependencies]). An updated database diagram is shown below.
Click to enlarge.
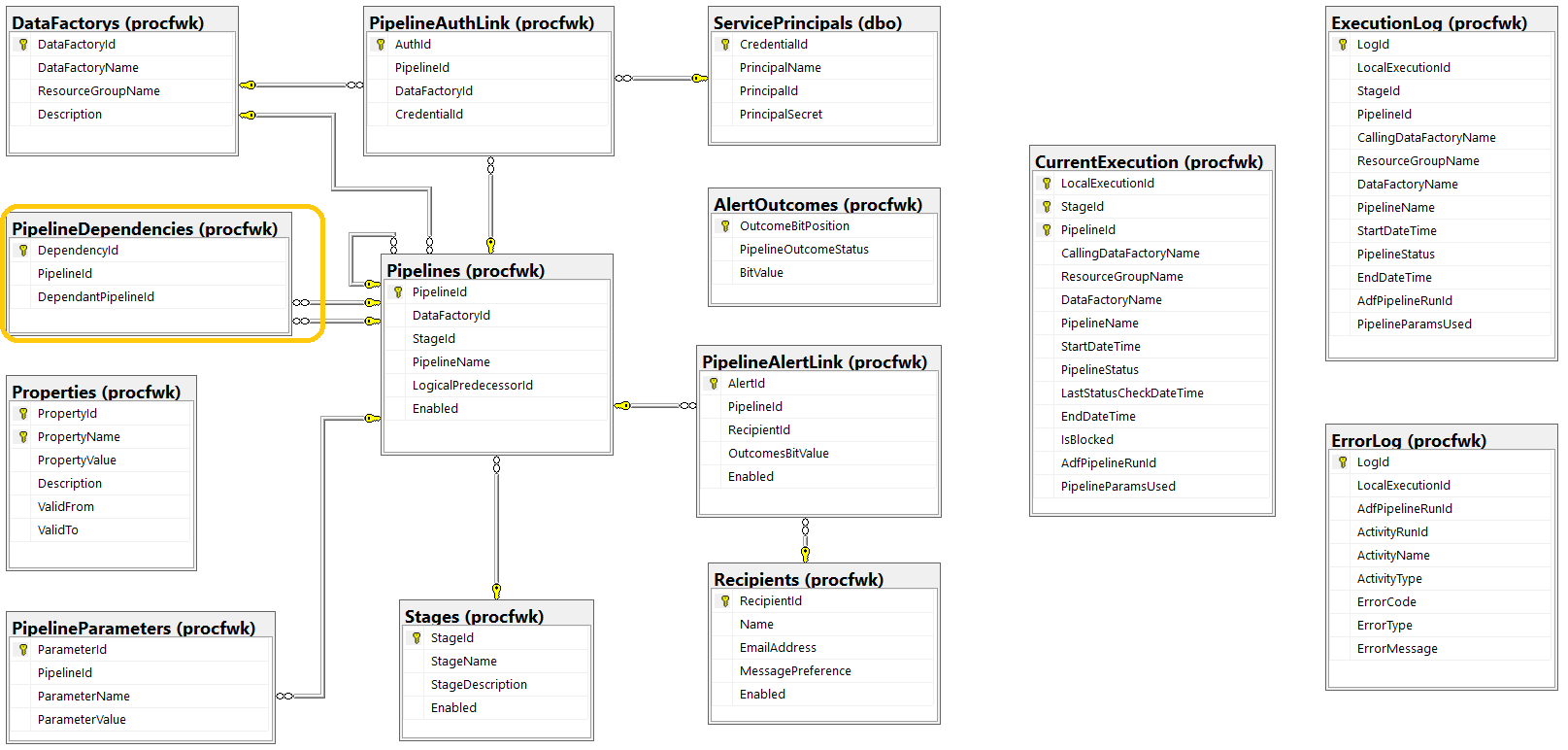
Dependency Chain Failure Handling
As mentioned above this feature was inspired by the Data Platform community through several blog post comments and GitHub requests has now come to fruition. Designing new functionality is always hard so having the support of the community really helped me refine this requirement to allow pipeline relationships to be used to drive a complete dependency chains across execution stages and better inform failure/restart behaviour. Thank you to all those who directly and indirectly contributed to this enhancement. You may in interested to learn that since the release of v1.7 my whiteboard at home has been taken over by this request and following various conversations has matured into what has now been developed for the processing framework. Thanks again!
Just to clarify, the new dependency chain metadata drives how failures are handled across stages. It is still expected that pipelines are put into separate execution stages so dependents are sequentially called upstream of there predecessor(s).
Property
At the heart of the new dependency chain behaviour is a new property called ‘FailureHandling‘. This drives the configuration for how failed Worker pipelines behave within a given execution run. The property can have one of the the following 3 values:
None = The pipeline status is updated to ‘Failed’ in the [procfwk].[CurrentExecution] table and the framework carries on regardless.
Simple = The pipeline status is updated to ‘Failed’ in the [procfwk].[CurrentExecution] table. Then all downstream execution stages are marked as blocked and processing framework is stopped after the stage where the failure occurred has completed any remaining Workers. This is the same as the restart behaviour first introduced in v1.2 of the processing framework.
DependencyChain = The pipeline status is updated to ‘Failed’ in the [procfwk].[CurrentExecution] table. Then only downstream pipelines are marked as blocked (using the [DependantPipelineId] attribute in the new [procfwk].[PipelineDependencies] table). Once done, processing is then allowed to continue. When the next execution stage starts only pipelines not blocked will get a status of ‘Preparing’ and be allowed to run. Finally, the stored procedure [procfwk].[CheckForBlockedPipelines] will look ahead to the next execution stage and mark any further downstream dependant pipelines as ‘Blocked’, continuing the chain.
To help with the explanation of this new feature I’ve created a short video to demonstrate the failure handling behaviour for each new property value mentioned above.
Table
[procfwk].[PipelineDependencies]– This table is used to drive the dependency chain failure handling. Relationships to the main pipelines table inform what is up/down stream of what. The simple 2 attribute structure of the table means one to many and many to one relationships can exist been Worker pipeline across execution stages. Also, to ensure metadata integrity the table has a series check constraints. As follows:- A foreign key check to the pipelines table for the pipeline ID.
- A foreign key check to the pipelines table for the dependant pipeline ID.
- Values must be unique in the table for the pipeline and dependant ID.
- Values for the pipeline and dependant ID cannot be equal.
View
[procfwk].[PipelineDependencyChains]– This view simply uses the[procfwk].[PipelineDependencies]table to provide a list of pipeline and stage names so dependency chains can be viewed in a readable form without checking primary/foreign key values.
Store Procedures
[procfwk].[AddPipelineDependant]– This is a procedure that can be used at deployment time or ad-hoc to add pipeline dependents to the metadata table[procfwk].[PipelineDependencies]. It resolves the provided pipeline names to there corresponding primary key values and also validates the dependency chain requirement to ensure integrity. It is recommended that you use this to create your own metadata chains.[procfwk].[UpdateExecutionLog]– Previously used just to archive off the[procfwk].[CurrentExecution]table data. This procedure now also checks that the execution run was completed successfully. Given the new dependency chain behaviour the pipeline status values need to be considered even if the Parent pipeline completes successfully. When failed Worker pipeline still exist in the[procfwk].[CurrentExecution]table an exception will be thrown here so the framework can be restarted and to avoid the table being truncated.[procfwk].[SetExecutionBlockDependants]– This procedure is used to update downstream execution stages marking Worker pipelines as blocked when using the ‘DependencyChain’ failure handling.[procfwk].[CheckMetadataIntegrity]– Three new metadata checks have been added to this procedure to guard against dependency chain problems and support the new ‘FailureHandling’ property. These checks are:- Is there a current FailureHandling property available?
- Does the FailureHandling property have a valid value?
- When using DependencyChain failure handling, are there any dependants in the same execution stage of the predecessor?
The following two stored procedure have been updated to exclude pipelines with a ‘Blocked’ status.
[procfwk].[SetLogStagePreparing][procfwk].[GetPipelinesInStage]
The following four stored procedures all have a similar updates applied; they use the new ‘FailureHandling’ property value and update the [procfwk].[CurrentExecution]table with the required pipeline status’ depending on the configured behaviour.
[procfwk].[SetLogPipelineFailed][procfwk].[SetLogPipelineUnknown][procfwk].[SetLogActivityFailed][procfwk].[CheckForBlockedPipelines]
 Data Factory Changes
Data Factory Changes
In this release I’ve included the complete Activity chain, shown below. For the failure and dependency handling there isn’t any significant changes, only a few renamed Activities to make the names more accurate.
The main Data Factory change is the introduction of the clean up Activities within the parent level. This logic is explained fully below the image.
Click to enlarge.
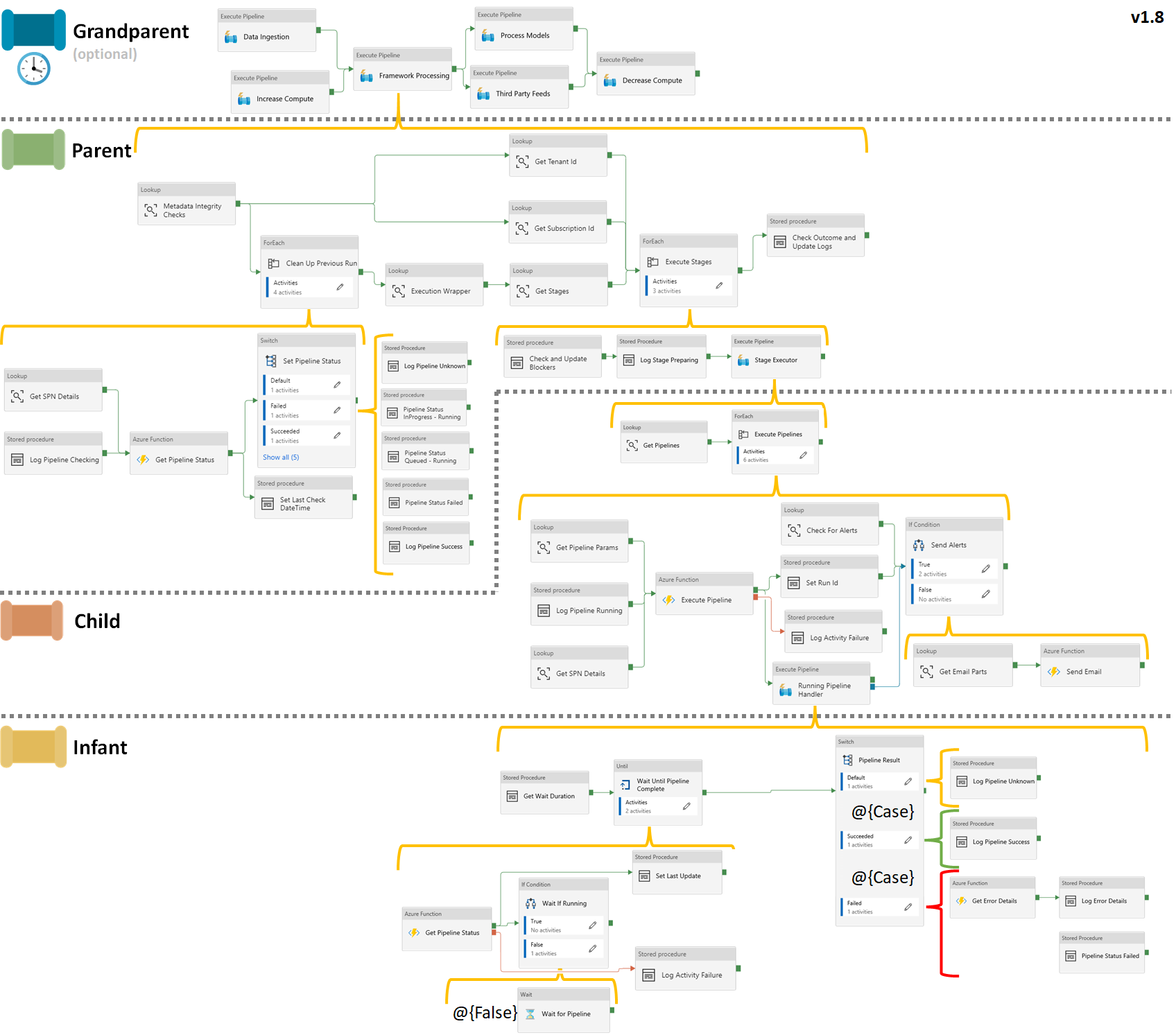
Clean Up Existing Run
During my own testing of the framework I encountered an Azure platform failure resulting in the connection to the metadata database being lost during an execution run. For the majority of the Worker pipelines this was handled gracefully meaning a normal restart could occur. However, an outlier situation was revealed affecting the Infant pipeline. The scenario was:
- A Worker pipeline had been called and was given a status of Running in the database.
- The Infant pipeline had been started for the Worker and was now in the process of waiting until the Worker completed.
- This is when the database connection issue occurred.
- As a result, the Worker pipeline completed successfully within its own Data Factory instance. However, the dropped database connection meant the metadata never got to find out about the pipeline completion status.
- Therefore, the Worker status remained as Running in the database and the Parent/Child pipelines failed.
- When attempting to restart, the execution wrapper threw an exception because of the apparent Running state of the Worker(s). As introduced in v1.7.2
To improve the handling in this outlier situation the Parent pipeline has been extended to now validate and clean up any Worker pipelines that appear with an unexpected status. By unexpected I mean they don’t have a status of: Success, Failed, Blocked.
The clean up ForEach loop follows a very similar activity structure to the Infant pipeline. But instead of waiting until the “Running” Worker completes. It simply does a one time call to get the pipelines actual status from the previously known run ID.
- If, the Worker is in fact still Running, the execution wrapper will still throw its intended error. As introduced in v1.7.2.
- If, the Worker has now completed with some other status. The actual pipeline outcome will now be reflected in the metadata before any restart action is taken.
To drive the clean up behaviour the [procfwk].[CheckMetadataIntegrity] stored procedure has had its parent pipeline activity type has been changed from ‘Stored Procedure’ to ‘Lookup’ allowing the output to be passed to the ForEach activity called ‘Clean Up Previous Run’. Internally the procedure now has two types of metadata integrity checks:
- Actual metadata integrity checks validating content before an execution run is started.
- Previous execution run checks where metadata is in an unexpected state.
Finally, during the clean up, affected pipelines will present in the [procfwk].[CurrentExecution] table with a new status of ‘Checking’. This is set by the stored procedure [procfwk].[SetLogPipelineChecking].
Other Changes
[procfwk].[GetPropertyValueInternal]– Within the database this scalar function has been created to help return current property values internally for other stored procedures as part of IF condition logic. Data Factory will continue to use the stored procedure[procfwk].[GetPropertyValue].- An NUnit project has been added to the solution with some initial tests. This is currently just a playground that I hope (with help) to mature into a complete set of functional tests in the future.
- The NuGet package ‘Microsoft.IdentityModel.Clients.ActiveDirectory’ has been updated to the latest version within the Azure Functions project.
That concludes the release notes for this version of ADF.procfwk.
Please reach out if you have any questions or want help updating your implementation from the previous release.
Many thanks

Are you familiar with Oracle DAC (Datawarehouse Administration Console)? This open source implementation seems to have some basic capabilities of DAC. I was wondering if someone has used this as DAC replacement for Informatica to ADF migration project?
LikeLike
Hi, I’ve never used DAC. I’ll leave the comment here for others to reply. Thanks Paul
LikeLike
Hi Paul,
Great work on this. It addresses lot of dependency issues that are there in adf as of now. I was wondering what would be approach if we need to trigger two different interdependent processes at different time.
Daily loads -> Runs every day and depends on itself
15 Min load – > depends on daily load and itself.
Regards,
Sid
LikeLike
Hi, thanks, I handle this in a recent release of the framework by introducing the concept of batch executions that sit as a level above stage executions. Check out procfwk.com
LikeLike
Hi Paul, Can you run multiple separate processes? In the demo there is 4 stages and the run in sequence. How would you set this up if there is 2 separates processes with no dependencies between them. Do I need to use batches for all stages then? Thanks!
LikeLike
Yes, within an execution stages worker pipelines will run in parallel. See latest documentation at procfwk.com
LikeLike