Code Project Overview
![]() This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is made possible by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist.
This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is made possible by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist.
The framework is designed to integrate with any existing Data Factory solution by making the lowest level executor a stand alone Worker pipeline that is wrapped in a higher level of controlled (sequential) dependencies. This level of abstraction means operationally nothing about the monitoring of orchestration processes is hidden in multiple levels of dynamic activity calls. Instead, everything from the processing pipeline doing the work (the Worker) can be inspected using out-of-the-box ADF features.
This framework can also be used in any Azure Tenant and allow the creation of complex control flows across multiple Data Factory resources by connecting Service Principal details through metadata to targeted Subscriptions > Resource Groups > Data Factory’s and Pipelines, this offers very granular administration over data processing components in a given environment.
Framework Key Features
- Granular metadata control.
- Metadata integrity checking.
- Global properties.
- Dependency handling.
- Execution restart-ability.
- Parallel execution.
- Full execution and error logs.
- Operational dashboards.
- Low cost orchestration.
- Disconnection between framework and Worker pipelines.
- Cross Data Factory control flows.
- Pipeline parameter support.
- Simple troubleshooting.
- Easy deployment.
- Email alerting.
ADF.procfwk Resources
| Blogs | mrpaulandrew.com/ADF.procfwk | |
| GitHub | github.com/mrpaulandrew/ADF.procfwk | |
 |
#ADFprocfwk | |
| Vlogs | youtube.com/mrpaulandrew |
Thank you for visiting, details on the latest framework release can be found below.
Version 1.7.2 of ADF.procfwk is ready!
Release Overview
Following some great feedback from the community I’ve put together another minor release to incorporate two database enchantments.
Database Changes
NULL Pipeline Parameters Values
![]() In the event that a pipeline parameter is added to the metadata table with a NULL value, this was not previously handled in a graceful way. The resulting JSON string simply got wiped while trying to concatenate the NULL. Now this is handled and also invokes the correct behaviour in Data Factory, assuming the metadata NULL was intentional and we actually want Data Factory to use a hard coded pipeline parameter default value. Eg:
In the event that a pipeline parameter is added to the metadata table with a NULL value, this was not previously handled in a graceful way. The resulting JSON string simply got wiped while trying to concatenate the NULL. Now this is handled and also invokes the correct behaviour in Data Factory, assuming the metadata NULL was intentional and we actually want Data Factory to use a hard coded pipeline parameter default value. Eg:
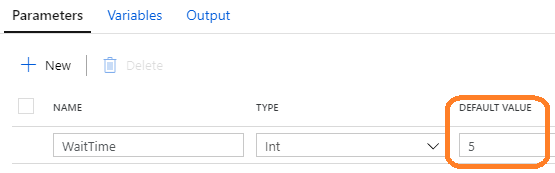
The logic for this is now as follows:
Database
- If a pipeline has a parameter or many parameters, attempt to create a key/value pair string that can be provided to the pipeline at runtime.
- If a parameter value in present, escape any JSON characters and add it to the output.
- If a parameter value is NULL, exclude both the key and the value from the output.
- If no keys are present because the pipeline simply doesn’t have any parameters or because the parameter(s) have NULL value(s) return an empty string.
- This then exclude the complete ‘pipelineParameters’ block from the eventual Function call request body.
Data Factory
- Where a NULL exists in the metadata, Data Factory will attempt to use the pipeline default value.
- Where a NULL exists in the metadata and no default value is available in Data Factory. A nature ‘missing value’ error will be returned from wherever the Work pipeline was attempting to use the parameter.
This logic now results in the intuitive behaviour for the couple framework resources and puts the ownership on the metadata added to being correct.
Thanks again James McLaughlin for reporting this issue.
Execution Already Running Error
In the event that Data Factory triggers a new execution of the framework while there is already an execution running this will now throw an error in the parent pipeline. Specifically, this will be thrown by the [procfwk].[ExecutionWrapper] stored procedure which will first inspect the [procfwk].[CurrentExecution] table for any Worker pipelines with a ‘Running’ status before considering any other framework restart logic. The expectation is that the existing execution run should be protected from a new Data Factory call to start over.
If the Worker pipeline isn’t truly running and Data Factory has (for some unknown reason) become disconnected from the metadata then manual intervention will be required. In this situation wider platform issues would require this anyway. Otherwise Worker pipelines need to be cancelled in Data Factory allowing correct metadata handling before a new restarted or clean execution can occur.
That concludes the release notes for this version of ADF.procfwk.
Please reach out if you have any questions or want help updating your implementation from the previous release.
Many thanks

Thanks for this Paul!
LikeLike
No problem, I was about to email you. But as you’ve seen the release already 🙂
LikeLike