Code Project Overview
![]() This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is made possible by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist.
This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is made possible by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist.
The framework is designed to integrate with any existing Data Factory solution by making the lowest level executor a stand alone Worker pipeline that is wrapped in a higher level of controlled (sequential) dependencies. This level of abstraction means operationally nothing about the monitoring of orchestration processes is hidden in multiple levels of dynamic activity calls. Instead, everything from the processing pipeline doing the work (the Worker) can be inspected using out-of-the-box ADF features.
This framework can also be used in any Azure Tenant and allow the creation of complex control flows across multiple Data Factory resources by connecting Service Principal details through metadata to targeted Subscriptions > Resource Groups > Data Factory’s and Pipelines, this offers very granular administration over data processing components in a given environment.
Framework Key Features
- Granular metadata control.
- Metadata integrity checking.
- Global properties.
- Complete pipeline dependency chains.
- Execution restart-ability.
- Parallel execution.
- Full execution and error logs.
- Operational dashboards.
- Low cost orchestration.
- Disconnection between framework and Worker pipelines.
- Cross Data Factory control flows.
- Pipeline parameter support.
- Simple troubleshooting.
- Easy deployment.
- Email alerting.
- Automated testing.
- Azure Key Vault integration.
ADF.procfwk Resources
| Blogs | mrpaulandrew.com/ADF.procfwk | |
| GitHub | github.com/mrpaulandrew/ADF.procfwk | |
 |
#ADFprocfwk | |
| Vlogs | youtube.com/mrpaulandrew |
Thank you for visiting, details on the latest framework release can be found below.
Version 1.8.5 of ADF.procfwk is ready!
Release Overview
A small release to include some minor enhancements to the processing framework. Specifically:
Issue #32 – Add support for an execution precursor to allow for custom control over the metadata database as part of an execution run. This as been added to help environments that require Worker pipelines to be executed at different intervals/frequencies. The precursor can help you control this by enabling/disabling Worker pipelines using some custom logic. Or do anything to the metadata at runtime using your custom database objects.
Issue #22 – Include a PowerShell script to scrap and prepopulate the metadata for an existing Data Factory of Worker pipelines.
Database Changes
 Property
Property
ExecutionPrecursorProc– This property which is a named stored procedure within the metadata database will be called first in the Parent pipeline and can be used to perform/update any required custom behaviour in the Procfwk execution by controlling the metadata values. For example, enable/disable Worker pipelines given a certain run time/day. Invalid procedure name values will be ignored and the precursor wrapper will return successfully.
Stored Procedures
[procfwk].[ExecutePrecursorProcedure]– this stored procedure is used by the framework to wrap the execution call to your custom precursor stored procedure. As the framework is calling custom code outside of its normal remit/control the wrapper is used mainly to inform what error message is returned should the custom code fail. The T-SQL within this wrapper is very simple as follows:
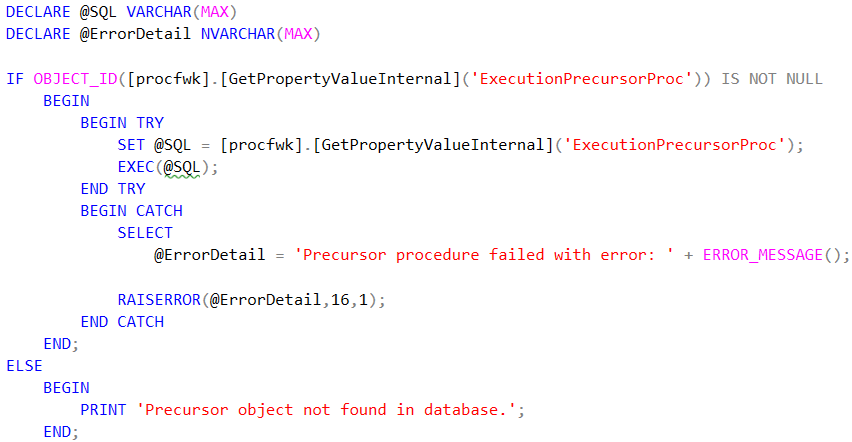
From a framework trigger perspective hopefully this will allow a lot more flexiblity for Worker pipelines that need to be called on different schedules. But without needing to completely rebuild a scheduling system into the metadata. That said, I’d be happy to include a simple date dimension to support any precursor logic if valuable.
[dbo].[ExampleCustomExecutionPrecursor]– this procedure is part of thedboschema and used as a example precursor within my framework development environment. Via the properties table this database object could be called whatever you want and do whatever you require before a given execution run.
 Data Factory Changes
Data Factory Changes
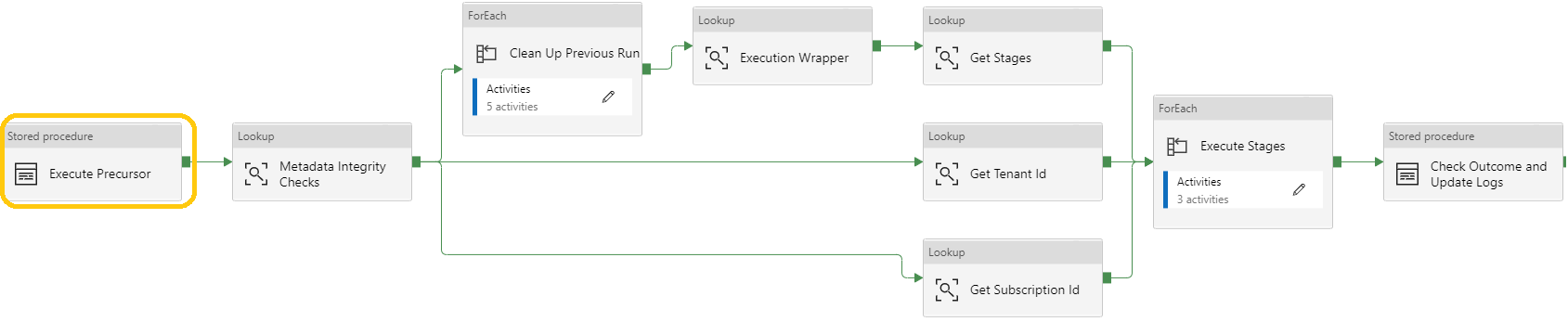
Only one new Activity has been added to Data Factory to support the new precursor behaviour. This exists at the very start of the Parent pipeline and calls the stored procedure [procfwk].[ExecutePrecursorProcedure] detailed above.
Snippet of the latest Parent pipeline Activity chain below with the new stored procedure call highlighted. The complete v1.8.5 Activity chain picture is available in PowerPoint here.
Other Changes
PowerShell

Through our great community contributors a new PowerShell script has been added to the Procfwk repository by Kamil Nowinski (@NowinskiK).
…\ADF.procfwk\DeploymentTools\DataFactory\PopulatePipelinesInDb.ps1
This script is intended to help out new users of the Procfwk by prepopulating the database metadata tables for a given Data Factory. Using the parameters provided to the script a list of existing Worker pipelines can be returned and using the new stored procedure [procfwkHelpers].[AddPipelineViaPowerShell] added to the metadata helping to get started with a Procfwk execution.
The procedure sets all Workers to a single execution stage called ‘PoShAdded’ which you may want to refine to make best use of Worker dependency chain. However, its a starting point to defining your framework metadata and to get going with the solution when retro fitting this to your existing Data Factory instances.
Testing
Using the new database helper and testing schema’s the NUnit test classes have new standard setup and teardown methods to empty the database and add basic metadata.
That concludes the release notes for this version of ADF.procfwk.
Please reach out if you have any questions or want help updating your implementation from the previous release.
Many thanks

Hi Paul, thank you for creating such detailed and fantastic ADF framework. I really enjoy your posts, tutorials, and have been able to make a prototype environment based on your code base. Subsequently, I have added some of my own improvements and will use it in real projects to prove its worthiness. Look forward to more features and explanations coming from you.
LikeLike
Hi, thanks for the feedback, really nice to hear. Please check out my new documentation site for the framework as well… procfwk.com
I’d love to hear more about your improvements. Would you like to raise them as feature requests to be built into the core code base? Then contribute to the repo? Or let’s exchange emails… paul@mrpaulandrew.com
Thanks
Paul
LikeLiked by 1 person
Hi Paul, thanks for the encouragement. Yes, I am currently in the midst of adding a couple features which I think is necessary in my environment. I will definitely write you once I have gained some solid ground on my code set. FYI, I did raise a couple feature requests into your repo for the moment. I will be in touch with you in the near future…Best, Henry
LikeLike
How does the framework get triggered?
LikeLike
By adding a trigger to the parent pipeline. See latest documentation at procfwk.com
thanks
LikeLike