Data Mesh vs Azure –
Theory vs practice
Use the tag Data Mesh vs Azure to follow this blog series.
As a reminder, the four data mesh principals:
- domain-oriented decentralised data ownership and architecture.
- data as a product.
- self-serve data infrastructure as a platform.
- federated computational governance.
Source reference: https://martinfowler.com/articles/data-mesh-principles.html
In Part 1 of this blog series we looked at a suitable container for our data mesh nodes, which I concluded should be Azure Resource Groups, but could also be Azure Subscriptions if required.
Some of you agreed with this following comments on my LinkedIn post and some didn’t. For clarity, Microsoft suggest using subscriptions as the node containers, which you can read about in the following “reference architecture” docs page: https://docs.microsoft.com/en-us/azure/cloud-adoption-framework/scenarios/data-management/architectures/reference-architecture-data-mesh.
I’m sticking with Resource Groups as my Data Mesh Nodes.
Anyway, moving on. In part 2 of this blog series, keeping the same focus from part 1, with the first data mesh principal. Let’s take our nodes and start thinking about the edges. The data mesh – data product interfaces… Enter my Azure Resource Group with arms/antenna type things, seen on the right 🙂
Caveat: as you may have already gathered, I’m going to use the terms edge and interface a lot in this post. The meaning in the context of the data mesh is the same. Nodes with edges, nodes with interfaces.
Edges (Primary node Interfacing)
What Azure Resources could/should be used to provide the interfaces in and out of our data products? Or, to use the correct terminology, what resources will facilitate the edges for our nodes in the wider data mesh architecture? In the Microsoft cloud set of PaaS offerings we have lots of options here. So, to answer this simply…
Question: what Azure Resource(s) should we expose to interact with our data products?
Answer: it depends (sorry, but it just does).
For me, the initial question is should the edges in our data mesh be a common thing, and by thing, I mean PaaS resource, at this point. Stay with me. One size does not fit all, especially for a diverse set of data products. Mandating the need to support an interface or set of interfaces from data products, fine. That we should expect as a concept and minimum requirement. But not the exact method or resource for interacting. Right? Let’s assume yes, for now.
So, what does this depend on? Well, I suggest we look back at how we’ve come to define ‘big data’. With the 4x V’s:
- Volume
- Velocity
- Variety
- Veracity
These same classifications could also be used to establish what the primary interfaces for our data product nodes should be. Note: I said primary interface. I want to establish a primary interface within our data mesh as being the edges used for the exchange/integration of data. Data that is processed by the data product(s) and the ultimate purpose for having the decentralised data ownership. The other critical thing to understand for our potenital edges resources is the business role of a given data product. For example, sensitive datasets, exposing an outbound interface probably doesn’t make sense. Or, should this simply have other levels of data segregation in place before an interface can be added.
To explore this thinking with further questioning, let’s say:
- What is the interface for?
- Who is going to use the interface?
- Why do they want the interface?
- When should the interface be available?
- How will the handshake occur within the interface?
Given the above, lets draw something to look inside one of our previously created Azure Resource Group data products. Visualising things always helps me bring meaning to the narrative. An Azure data mesh node, with edges for other nodes to interact:

Let’s go one level deeper here and define the roles of the edge resources that I’ve (optionally) included above. Going round the exploded Resource Group clockwise, starting at the top left:
- Azure Event Grid – our data product processes write an event to the event grid topic(s) when a certain stage in the internal execution job has completed. This then triggers execution jobs for other nodes in a traditional publisher/subscriber setup.
- Azure Service Bus – allowing for downstream processes or other nodes to use a queued set of metadata messages which could be used to spawn other interactions. This allows for decoupled, asynchronous interactions with the current nodes data processing.
- Azure Functions App – offering a custom, serverless endpoint coded to perform either input or output operations for the data products internal workings. This could be anything. Even something as simple as sending an email alert.
- Azure API Management – for lightweight requests and interactions between nodes, offering direct (limited) query results as an outbound option. Or processing inbound payloads that supplement the main data processing. For example, a reference data update.
- Databricks SQL – as a very common query language an SQL endpoint allows connections from a wider range of consumers and other nodes. Performing analytical queries and allowing data exploration from 3rd party tools.
- Azure Event Hub – for the passing of data stream messages to other nodes, where 1 row of data processed equals 1 message written to the Event Hub namespace, either as a burst of records or a trickle feed.
- Azure Data Factory (Linked Service Connections) – supporting the pull of data via Data Factory Pipeline Activities from a wide range of data sources, including 3rd party connections.
- Azure Data Factory (Self Hosted Integration Runtimes) – allowing Data Factory to reach data sources in remote/private networks.
Hopefully, the ‘it depends’ answer now carries some more context given the different technical scenarios I’ve described.
Edge Conclusion
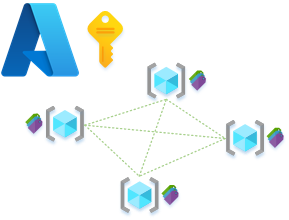
Let’s now reflect on this (and slightly contradict myself 🙂 ). Earlier I said ‘should the edges we define for our nodes be common’. Does that therefore mean certain nodes within our data mesh become isolated or disconnected because the way they interface doesn’t naturally fit with the rest of the mesh? Can a node be part of the data mesh if we don’t standardise the edge resources? In the below image of a simple 6 node mesh, node 5 doesn’t support a SQL endpoint, should it?

Given this evolution in thinking, is the better question, what should our standard primary edge Azure Resource be that offers the best all round level of interaction for nodes in the data mesh?
I’m going to say that the tool doesn’t matter, the answer (for now) should simply be a SQL endpoint. Which in Azure could be delivered using lots of different resources.
- Azure Synapse Analytics (SQL Serverless or Dedicated SQL Pools)
- Azure Databricks SQL
- Azure SQL Database
- Azure SQL Managed Instance(s)
- SQL Server running on an Azure Virtual Machine
SQL has become such a foundational language for the industry at the node interface level it makes the most sense. That is until natural langage processing gets perfected… A thought for a later post when we think about data virtualisation.
So, a SQL endpoint is the best interface as the edge to all the nodes in our data mesh architecture.
Many thanks for reading, stay tuned for more in this series of blogs.

Dont think that standardize should matter across the nodes..as the nodes are responsible for data products coming from different domain having different structure and complexity…some might need additional resources to deliver the data product..off course interface pattern could be standardized as REST APIs
LikeLike
I’ve had an intense relation with SQL for quite a while and I like it a lot, but I’m not sure I agree that the best interface should be SQL unless a very robust mechanism is put in place to avoid excessive consumption of resources and this might not be trivial.
Controlling consumption is not only a matter of costs (if the SQL interface is supported by an auto-scaling tool), but also a matter of service levels.
LikeLike