Code Project Overview
![]() This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is made possible by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist.
This open source code project delivers a simple metadata driven processing framework for Azure Data Factory (ADF). The framework is made possible by coupling ADF with an Azure SQL Database that houses execution stage and pipeline information that is later called using an Azure Functions App. The parent/child metadata structure firstly allows stages of dependencies to be executed in sequence. Then secondly, all pipelines within a stage to be executed in parallel offering scaled out control flows where no inter-dependencies exist.
The framework is designed to integrate with any existing Data Factory solution by making the lowest level executor a stand alone Worker pipeline that is wrapped in a higher level of controlled (sequential) dependencies. This level of abstraction means operationally nothing about the monitoring of orchestration processes is hidden in multiple levels of dynamic activity calls. Instead, everything from the processing pipeline doing the work (the Worker) can be inspected using out-of-the-box ADF features.
This framework can also be used in any Azure Tenant and allow the creation of complex control flows across multiple Data Factory resources by connecting Service Principal details through metadata to targeted Subscriptions > Resource Groups > Data Factory’s and Pipelines, this offers very granular administration over data processing components in a given environment.
Framework Key Features
- Granular metadata control.
- Metadata integrity checking.
- Global properties.
- Dependency handling.
- Execution restart-ability.
- Parallel execution.
- Full execution and error logs.
- Operational dashboards.
- Low cost orchestration.
- Disconnection between framework and Worker pipelines.
- Cross Data Factory control flows.
- Pipeline parameter support.
- Simple troubleshooting.
- Easy deployment.
- Email alerting.
ADF.procfwk Resources
| Blogs | mrpaulandrew.com/ADF.procfwk | |
| GitHub | github.com/mrpaulandrew/ADF.procfwk | |
 |
#ADFprocfwk |
Thank you for visiting, details on the latest framework release can be found below.
Version 1.6 of ADF.procfwk is ready!
Release Overview
The primary goal of this release was to capture Worker Pipeline Activity error details in the processing framework database. Given the potentially wide reach and nature of the processing framework where Data Factory could be separated from the Worker pipelines the easiest way to get this information was via another short and sweet Azure Function. The foundations for this were laid as part of a separate blog post here where I created the basic Azure Function in isolation. It was important to get this working before considering the integration with the processing framework.

Using this existing Function to return an array of activity error content from a given Worker pipeline meant that all I then needed to do for this this was decide where to call the Function and how the result should be persisted in the metadata database. More details below on how this was applied to the Infant Pipeline and what additional Database objects have been created.
 Database Changes
Database Changes
The database in this release has one new table, one new view, two new table attributes (to capture the pipeline parameters used at runtime) and a bunch for stored procedure tweaks. Below is an updated database diagram with the table changes highlighted.

Execution Error Logging
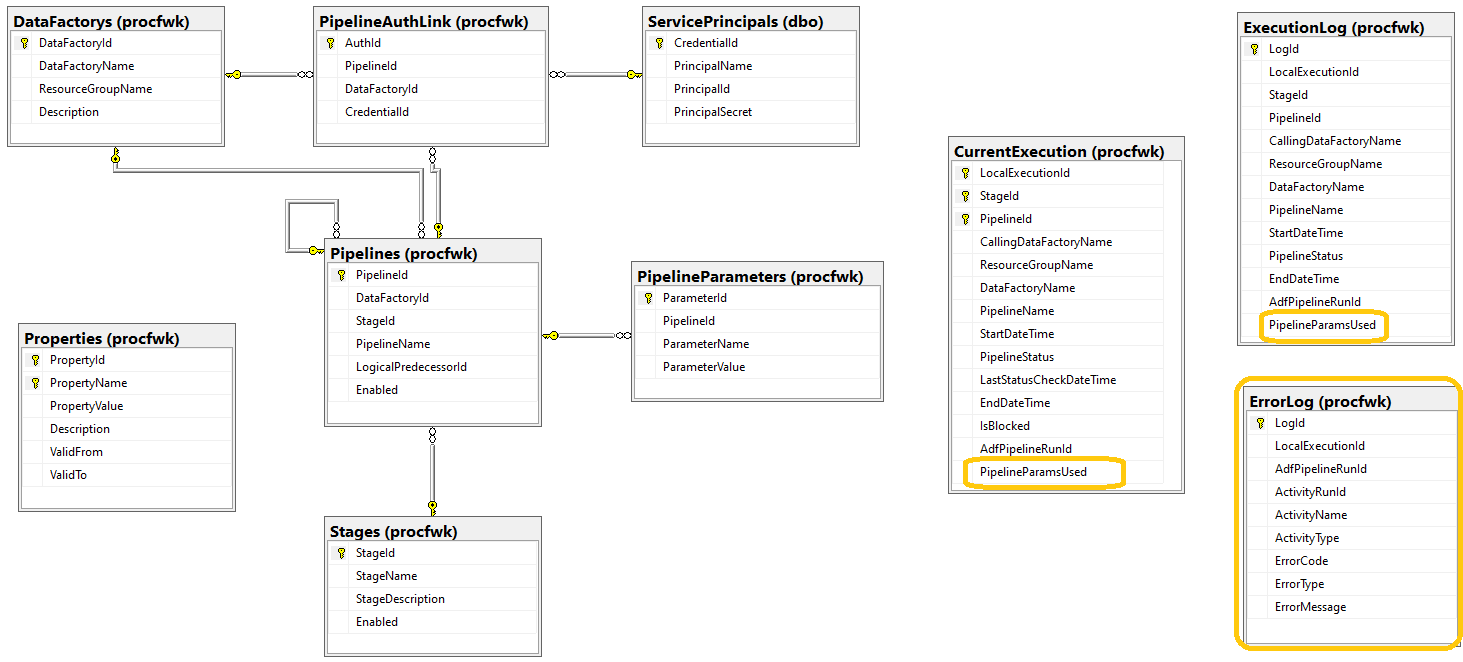
Capturing error details as mentioned was the main theme for this release. To support this behaviour in the metadata database the following objects have been added:
[procfwk].[ErrorLog]– this table is used to house Pipeline Activity Error details in the event of a failure. It contains only basic information about the pipeline and then complete information for the Activities errors. It is expected that for a single Pipeline Run ID multiple Error Log details may exist. The main reason for this is because a Worker pipeline could have many Activities that if executed in parallel and fail mean error details for each are returned.
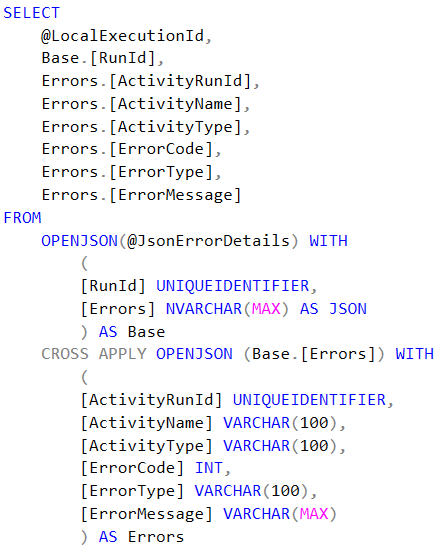
[procfwk].[CompleteExecutionErrorLog]– this new view provides execution information with the attached error details where applicable. The view performs an inner join on the[procfwk].[ExecutionLog]and[procfwk].[ErrorLog]tables using the[LocalExecutionId]and[AdfPipelineRunId]attributes. The inner join assumes a failure has occurred for the pipeline Run ID.[procfwk].[SetErrorLogDetails]– this procedure is used to parse the error details provided by the new ‘Get Activity Errors’ Azure Function detailed below. The JSON output is received by the stored procedure as a simple string and then parsed using the OPENJSON methods within T-SQL. Once parsed the row(s) are inserted into the Error Log table. SELECT code snippet on the right.
Unknown Status Optionally Blocks Stages
Next, in the event of an unknown status being returned from a Worker pipeline the Switch activity within the Infant pipeline will call its default condition and stored procedure. Previously, this simply updated the [procfwk].[CurrentExecution] table with the value of ‘Unknown’ and the framework would carry on. Now, to better handle potential cancellations and other miscellaneous behaviour that aren’t simple Success or Failures this unknow/default outcome from the Switch will also result in downstream processing stages being blocked, in the same way as a Worker failure is handled. Thank you Matias Samblancat for providing this hardening improvement.

In addition, this behaviour can be controlled via a new property called ‘UnknownWorkerResultBlocks’. By default (in the database post deployment script), unknown Worker pipeline outcomes will block downstream processing stages. Set the property to ‘0’ if you prefer processing stages to continue.
Get Execution Details
[procfwk].[GetExecutionDetails] is a new stored procedure I’ve added to act as a friendly combination of both the execution and error log tables. It offers a summary of any execution or the last execution and includes left joins for error information, plus ordering of results that makes the output easy to understand for a given run and/or potential restart.
Pipeline Parameters Captured in Execution Logs
This change has been in the backlog for a while and for a long time I couldn’t decide how to do it (seeing the wood for the trees I think was the problem). Anyway, all sorted now. At run time pipeline parameters are now captured as part of the Get procedure that provides them to the Worker pipeline during framework execution.
As not all worker pipelines being called have or require pipeline parameters the simplest place to capture these values was using the existing stored procedure [procfwk].[GetPipelineParameters]. If parameters are used for a given pipeline ID an update is also done to the table [procfwk].[CurrentExecution]. This was such an easy change after I thought about it, I don’t know why I didn’t include it sooner 🙂

As you can see in the screen shot above the attribute contains a complete JSON block of parameters as this could be many key/value pairs for a given Worker pipeline. Additional braces have also been included to make the JSON snippet valid compared to how its actually injected into the Execute Pipeline Function body.
 Function Changes
Function Changes
This release of the processing framework includes two new Azure Function as follows:
Get Activity Errors
This Function hasn’t changed much from when I first created it in my earlier blog post mentioned above. Within the context of the processing framework the only differences to the Function are:
- The connection and authentication is now handled via the Data Factory client helper class, as per the existing Execute Pipeline and Check Pipeline Status Functions.
- The Activity Run Id has been added as an output from the Function call for each error found.
Below is a snippet showing the second point in Postman, compared to the earlier blog output.

Send Email
I’ve added this Function to the Solution now mainly because I had the code available from another project and I was already working on the framework functions, so it made sense to front load this bit of work. The Function isn’t yet implemented anywhere in the framework, that will come in a later release. However, feel free to use it for your own alerting. The code is very simple and uses the System.Web.Mail library.
The body request for the Function expects the following things:
| Attribute | Mandatory | Value(s) |
| emailRecipients | Yes | String value of one or many email addresses separated by comma’s. |
| emailCcRecipients | No | String value of one or many email addresses separated by comma’s. |
| emailSubject | Yes | String free text value. |
| emailBody | Yes | String free text value. |
| emailImportance | No | This uses the Mail.Priority values of:
The default value is ‘Normal’ if not provided in the request. |
 To promote good practice the SMTP credentials are stored as Application Settings local to the Azure Functions App. In the Visual Studio Solution the project ‘local.settings.json’ file has now been excluded via the Git.Ignore file from the repository. However, I’ve added a ‘template_local.settings.json’ file which you can copy and use when publishing the Function and debugging locally. On the right is a screen shot of how my project looks with the actual local settings file being copied to the bin folder for every build. This is also support via the Functions App publish screens if you want to edit the local and remote app settings. When the Function is fully implemented in the framework I’ll go into more details if you haven’t done this before. I did consider including the mailbox details in the framework metadata database but decided that would make the Function call too ‘chatty’ at runtime, laboured pun intended! Plus, the database credentials would then need to be sorted as app settings anyway, or SPN details to get to Key Vault etc etc.
To promote good practice the SMTP credentials are stored as Application Settings local to the Azure Functions App. In the Visual Studio Solution the project ‘local.settings.json’ file has now been excluded via the Git.Ignore file from the repository. However, I’ve added a ‘template_local.settings.json’ file which you can copy and use when publishing the Function and debugging locally. On the right is a screen shot of how my project looks with the actual local settings file being copied to the bin folder for every build. This is also support via the Functions App publish screens if you want to edit the local and remote app settings. When the Function is fully implemented in the framework I’ll go into more details if you haven’t done this before. I did consider including the mailbox details in the framework metadata database but decided that would make the Function call too ‘chatty’ at runtime, laboured pun intended! Plus, the database credentials would then need to be sorted as app settings anyway, or SPN details to get to Key Vault etc etc.
 Data Factory Changes
Data Factory Changes
Finally, building on the work done for error handling in the Database and Function App above. The actual error handling call is now being done by the Infant pipeline within the existing Switch activity when the case condition is ‘Failed’. Snippet of the Activity chain below.
The complete v1.6 activity chain picture in PowerPoint here as usual.

The output of the Function Activity is simply passed to the Stored Procedure Activity as a string, as mentioned in the database changes section. These two new activities (as you can see) happen in parallel to the existing failure procedure allowing error details be to reported on as soon as the downstream Worker pipelines becomes blocked in the current execution.
I’m still very conflicted about where Worker pipeline failures are handled vs actual platform failures and if all scenarios are covered. For example, capturing the Worker error details in this way assumes a lot of the framework boiler plate code is going to complete successfully. You’d hope that this is the whole point of a framework. But… What if? What if? What? If you have any thoughts on this I’d be interested to hear them. Anyway, moving on.
Other Changes
A few other minor things to be aware of in this release…
General
- The Azure Data Studio Notebook created with lots of handy code snippets and narrative has been updated to include the new Error Log table, view and stored procedure.
- The default value for the property ‘PipelineStatusCheckDuration’ has been reduced from 60 seconds to 30 seconds. This means the Infant pipeline Until activity will have shorter iterations between Worker pipeline checks. Please update this to best fit with your environment and worker pipelines.
Visual Studio Solution Housekeeping
I’ve done a reasonable amount of cleaning up in the solution as part of this release so please make sure you get the latest version. Changes as follows:
- The project within the Visual Studio Solution used to house the Azure Functions has been renamed from ‘PipelineExecutor’ to just ‘Functions’ and its namespace updated to ADF.procfwk. Given the number of Functions now included in the framework that deliver and support the execution process the original singular project name had to go. The change has also been applied to the underlying solution folder structure to avoid any confusion.
- The legacy pipeline executor Function has now been removed as advised it would be in release v1.4.
- The Functions .cs files now include C# code regions for easier reading.
- The database project has had its default schema set to ‘procfwk’ when creating new objects. Sorry ‘dbo’, we’ll start using you again one day!
- All database stored procedures have been updated to include some element of code hygiene. For example; RETURN values added. All code included within BEGIN and END blocks. Nothing that affects functionality, just hygiene.
- Credentials used in the PowerShell scripts for deploying Data Factory have been refactored to use local environment variables. This is mainly to make my life easier when (not) committing free text credentials into the GitHub repository. Long term I will be created a proper Azure DevOps release pipeline.
That concludes the release notes for this version of ADF.procfwk.
Please reach out if you have any questions or want help updating your implementation from the previous release.
Many thanks

Thanks Paul for yet another post with a detailed explanation.I was watching your video on Complex Azure Orchestration on YouTube. We never used Custom activity in our pipelines.
Can we look at a mainframe EBCDIC file to ASCII conversion as a use case for custom activity and then feed to subsequent activities in the pipeline?. We still maintain the code in the On-premise ETL for converting the files to ASCII and move the files to the storage account. We are looking at the options to make our solution a complete Cloud-based solution. Please let me know if this can be achieved using a custom activity.
Thanks in advance,
Arun Sankar
LikeLike
Hi, yes, you could lift and shift your on prem code to a Custom Activity. Does the mainframe have a private endpoint? If so, you’ll probably need to add the Batch Service compute pool to a VNet that in turn has a connection to your local resources.
Cheers
Paul
LikeLiked by 1 person
Hi Paul,
i was trying to set-up the framework, however i do have some difficulties when executing pipelines (via Azure Functions). I have set up Service Principal and gave him grants. From ADF i am getting the following message:
Call to provided Azure function ” failed with status-‘InternalServerError’ and message – ‘Invoking Azure function failed with HttpStatusCode – InternalServerError.’.”
When i open the Function in the Azure to test it out, i am getting already error message “the function runtime is unable to start”, When looking at the Debug Console i see:
System.InvalidOperationException : The BlobChangeAnalysisStateProvider requires the default storage account ‘Storage’, which is not defined.
at async Microsoft.Azure.WebJobs.Script.ChangeAnalysis.BlobChangeAnalysisStateProvider.GetCurrentAsync(CancellationToken cancellationToken) at D:\a\1\s\src\WebJobs.Script.WebHost\BreakingChangeAnalysis\BlobChangeAnalysisStateProvider.cs : 37
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw()
at async Microsoft.Azure.WebJobs.Script.ChangeAnalysis.ChangeAnalysisService.TryLogBreakingChangeReportAsync(CancellationToken cancellationToken) at D:\a\1\s\src\WebJobs.Script.WebHost\BreakingChangeAnalysis\ChangeAnalysisService.cs : 92
I believe that when i did deploy the function over your ARM Template it did not map it to any storage account? Do you think this is the problem, can one map the Storage account as the function is already created?
Thanks and regards,
Gapy
LikeLike
Check the permissions between ADF and Key Vault. Also that the Function App default key is used for the ADF Linked Service. Email me if this still isn’t working. Cheers Paul
LikeLike
Hi Paul,
yes indeed the default key was also missing. By the way does one have to create for each Azure Function (ExecutePipeline, GetActivityErrors) a separate Linked Service? I mean one Function Linked Service maps to one Secret only.
Furthermore, does the framework support that one could execute the pipelines in defined order inside one Stage (For instance: Stage1 -> Pipeline 1 & 2 parallel, Pipeline 3 when both are finished)? Or i suspect this might be resolved by using many different stages…
Thanks and cheers,
Gapy
LikeLike
Hi Gapy
Azure Function authentication can work at both levels. 1) A single key for the whole Functions App, covering multiple Functions within the App and only requiring a single Linked Service from ADF. 2) Separate keys for each Function within a Functions App requiring a different Linked Service in ADF for each. I’ve worked with both situations. However, for the ProcFwk I use option 1 in my development environment and assume the same in the deployment steps. Of course, apply this as you prefer. For info, I’ve seen option 2 used where many isolated Data Factory’s (or other services) need to hit a central set of Azure Functions and have those Functions charged under a single App Service Plan, this also means one set of shared compute for the Functions. Then more granular access to keys might be better. But this isn’t a requirement for my solution.
To your second question, no, the framework doesn’t currently support this. Interesting idea. What is your use case? I’d be happy to add the feature to the backlog. But, generally, yes, this is what execution stages are used for. Feel free to log an new feature request via the repo issues areas… https://github.com/mrpaulandrew/ADF.procfwk/issues
Thanks
Paul
LikeLike
Hi Paul,
it was merely a question, i do not have the business case yet to support within stages the multiples dependencies, so no need to further complicate it. I know from SSIS (when i was building with BIML) there were some ideas to implement complex dependencies handlings in order to go on with the process even if some predecessor objects failed, but they were not dependant/relevant for the next processes. So you might have:
– Stage 1 -> Pipeline 1, Pipeline 2… Pipeline 2 failed
– Stage 2 -> Pipeline 3 can continue since Pipeline 2 was not dependant (business dependant), however Pipeline 4 should not continue
The advantage of this approach would be to have at least some business areas (let us say Production) processed, even if some other pipelines failed (e.g. Marketing, Human Ressource).
I was looking also at deployments options of the data factory and somehow came to the conclusion also based on your suggesstions, that if we have separate DEV & PROD environments (two Azure SQL DBs – used as DWH) then we should have also 2 separate data factories, since they are connected to the different environments, Otherwise i would have to always change the connection of underlying Azure SQL DB to PROD before publishing the data factory to the live service (very cumbersome). So instead i would rather use 2 data factories (dev and prod), where DEV is with GIT (Azure DevOps) integrated, and PROD will only have live service. The deployment to PROD will be done over ARM templates. Are there any better ways to deal with this?
Thanks and regards,
Gapy
LikeLike
Hi Gapy
To your first point. I have considered this. I have an item already on the backlog to allow processing to continue in the event of a failure. Plus, in the pipelines table there is also an attribute ‘Logical Predecessor’ to inform this behaviour. Not fully implemented yet though. I need to give the design some more thought, but yes, it will work roughly as you described.
To your second point, I always use Powershell to deploy ADF parts. Check out the PowerShell script under the deployment tools project in the framework solution.
Cheers
Paul
LikeLike