Here’s a quick bit of information I thought was worth sharing…
For file types that don’t contain there own metadata (CSV, Text etc) we typically have to go and figure out there structure including; attributes and data types before doing any actual transformation work. Often I’ve used the Data Factory Metadata Activity to do this with its structure option. However, while playing around with Azure Synapse Analytics, specifically creating Notebooks in C# to run against the Apache Spark compute pools I’ve discovered in most case the Data Frame infer schema option basically does a better job here.
Now, I’m sure some Spark people will probably read the above and think, well der, obviously Paul! Spark is better than Data Factory. And sure, I accept for this specific situation it certainly is. I’m simply calling that out as it might not be obvious to everyone 😉
A quick example from my playing around:
The actual dataset as seen in Notepad++

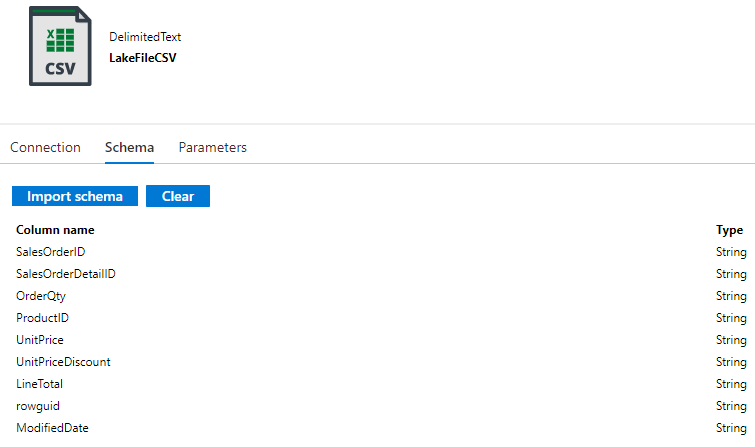
The metadata structure from Data Factory

The interred schema from the Spark data frame

A side by side comparison
| Column Name | ADF Data Type | Spark Data Type |
| SalesOrderID | string | integer |
| SalesOrderDetailID | string | integer |
| OrderQty | string | integer |
| ProductID | string | integer |
| UnitPrice | string | double |
| UnitPriceDiscount | string | double |
| LineTotal | string | double |
| rowguid | string | string |
| ModifiedDate | string | string |
This was only a small dataset with only 542 rows of data, I did the same thing with others before drawing this conclusion.
To that end, I’m suggesting the following:
- For quick schema inference without to much effort, the ADF Metadata Activity can help during a control flow operation.
- For more accurate schema inference use a dedicated transformation tool.
- For exact schema definitions, create it yourself or ideally inherit it from a metadata backed source system.
Side note; if you go to the Dataset within the Data Factory UI and Import Schema from the source connection, you’ll also get the same result as the Metadata Activity, seen below.
Many thanks for reading

Nice and cool info!
LikeLike
Nice Info. Databricks recommends that not to use inferSchema as it triggers separate job to find out the schema definition from the sample dataset.
So it is always better to inherit it from a metadata backed source system as mentioned above…
LikeLike
Yes, good point. Really it was about comparing the accuracy to the ADF metadata activity too.
LikeLike