Data Mesh vs Azure –
Theory vs practice
Use the tag Data Mesh vs Azure to follow this blog series.
Context and Background
The concepts and principals of a data mesh architecture have been around for a while now and I’ve yet to see anyone else apply/deliver such a solution in Azure. I’m wondering if the concepts are so abstract that it’s hard to translate the principals into real world requirements, and maybe even harder to think about what technology you might actually need to deploy in your Azure environment.
Given this context (and certainly no fear of going first with an idea and being wrong 🙂 ) here’s what I think we could do to build a data mesh architecture in the Microsoft cloud platform – Azure.
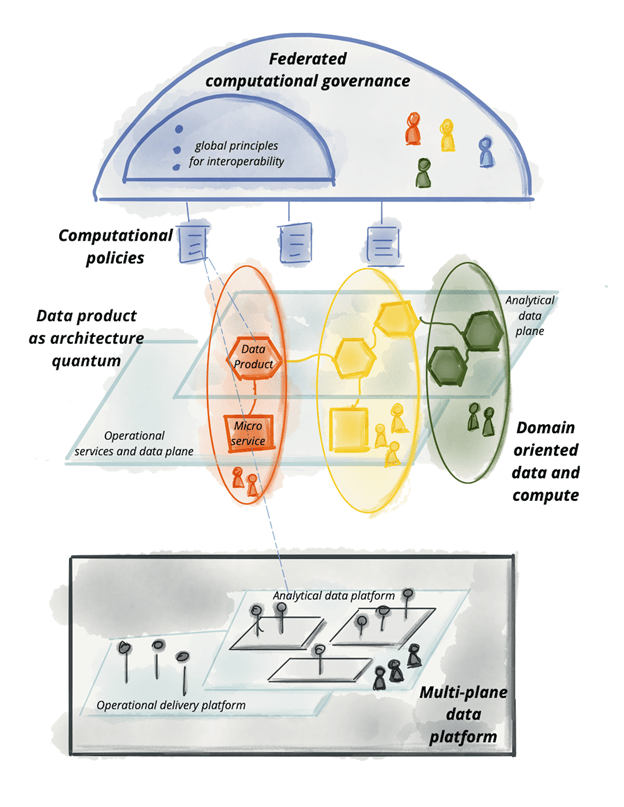
As a reminder, the four data mesh principals:
- domain-oriented decentralised data ownership and architecture.
- data as a product.
- self-serve data infrastructure as a platform.
- federated computational governance.
Source reference: https://martinfowler.com/articles/data-mesh-principles.html

Before digging in, it’s also worth saying that I have my own sceptical views on the ‘data mesh’. My current criticisms are:
- The data mesh is very input driven and lacking in the critical data insight and outputs components that ultimately deliver the business value. It’s alluded to, but not fully represented as a core component.
- Thinking about the first principal above, what stops disconnected domains ingesting the same data, affectivity duplicating effort and potentially stressing the underlying OLTP system. Or to ask the question another way; what governs the data ownership when multiple data products require the same dataset?
- If we deliver a self-serve data infrastructure, what data model should be targeted and where should it be built (without it becoming a monolith data warehouse amongst the mesh). Should this be part of the suggested virtualisation layer? Or is a single data model not the goal at the data product level?
That said, can we still deliver a data mesh, and live-in hope that we can utilise technology/innovation to overcome my criticisms. Right?!
Let’s explore this together in a series of blog posts where I’ll think about turning the theory into practice.
As always, I would very much welcome your feedback on my thinking and perspective here.
Let’s start breaking down this challenge, addressing the data mesh principals in turn.
2. data as a product
I’m going to explore this principal in a few different ways. Firstly:
Node ARCHITECTURE Containers
When working in Azure, the natural way to decentralise and apply this first principal could be by using Resource Groups or separate Azure Subscriptions, within the overall Azure Tenant (AD Domain). These logical structures of cloud organisation seem like a good way to separate the data ownership/architecture and allow a given data domain or business function to operate independently, within a Resource Group or Subscription.
That said, I’m very aware of the limitations Microsoft enforces at a Subscription level for things like role-based access controls (RBAC). So, let’s caveat this first principal with a design question about solution scale. I like using Resource Groups as the logical nodes within the data mesh, but if your solution needs to scale further than the service limitations allow, you should go a level up and have Subscriptions acting as each node. We’ll come back to this point later, espically considering scalability.
Visually, the affect is similar for the ultimate data owner, the re-charging of Azure consumptions costs might just need a little more thinking about considering the use of Azure Tagging vs the natural charging bucket of a subscription. All things to be aware of when we go from theory to practice.
| Azure Resource Groups as Data Mesh Nodes | Azure Subscriptions as Data Mesh Nodes |
 |  |
To offer another perspective, what I suggest we avoid, is going to a lower level than Resource Groups with the data ownership, whereby, we consider separate Azure Storage Accounts or Azure Data Lake Storage as the means of forming data ownership separation.
As a hierarchy: Tenant > Subscription > Resource Group > Storage (Resource) > Container.
Resource Group feels like the correct starting point for most solutions.
That concludes what I wanted to cover in this initial blog post. I didn’t want to make it too long and it seemed to take me a lot of words to establish the context and background.
In the next post we’ll look at mesh node interactions and interfaces, with the same practical lens.
Many thanks for reading.

“Thinking about the first principal above, what stops disconnected domains ingesting the same data, affectivity duplicating effort and potentially stressing the underlying OLTP system. Or to ask the question another way; what governs the data ownership when multiple data products require the same dataset?” – The way we’re attempting to solve this is a common resource group with batch and RT data sourced and standardized consistently, upon which domains can build their data products. Ownership of a dataset is assigned to a primary domain and fingerprinted with domains that will required them.
LikeLike
What governs the data ownership when multiple data products require the same dataset? => tough question.
I see two options:
– One of the domains is responsible for providing the single dataset to all domains, but then they’ll have to provide an SLA, which could lead to complexity and prioritization issues (can a domain commit to other domain requirements?)
– Or a central entity is responsible to provide common data products, but this is precisely what we want to avoid with the data mesh approach.
Note that it also brings another concern about data mesh, notably when it comes to business critical workloads : running production jobs is complex and costly when you must commit on SLAs (it requires advanced monitoring, incident response plan, on call engineers…). For sure, not all domains will be able to address those challenges.
LikeLike
My understanding for that requirement is that there is always a team (domain, either large or small) who owns the data product. But they are not alone in that, as domains usually doesn’t have much engineering understanding. In our case a central platform team delivers blueprints that each domain can deploy and use on their own (so they have their own instances of different resources). These blueprints covers also making their data products discoverable and other domains can use them (subscribe or ad-hoc) to get their own redundant copies. Cost of redundant data is something that we can digest in the context of lots of different teams that can operate on their own since moment they have their copy of the data.
LikeLike
You bring up an important aspect of the Data Mesh pattern: owning the data and owning the supporting technological infrastructure, in the sense of designing and managing it, don’t have to be within the same team to make the pattern work.
LikeLike
Ownership of the product should be own by the first business owner that request it or simply the one who pay! Velocity of the product data refresh need to be agreed. For the SLA, a composite one can be build as a start and then the upgrade of the SLA also beed to be budget driven.
LikeLike
I am not sure I’m in full agreement.
Ownership of the product in my opinion should sit with the team that creates the product and the cost should be paid by the teams that use it.
In the beginning this might imply that the producer is the only consumer or that no consumer exists at all and that the cost is allocated from the general budget.
If after a certain time no one is using (and paying for) the data product then the team should just stop producing it.
Just like a normal enterprise would do with any other product that doesn’t sell.
LikeLike